Попробовали pytest, потом попробовали mypy, но баги продолжают просачиваться в код. Что дальше? В данном выступлении мы обсудим два простых, но мощных инструмента для ограждения кода от проблем. Тестирование свойств (property-based testing) с помощью библиотеки Hypothesis поможет запустить сотни тестов в одном шаблоне. Благодаря контрактам (contracts) из модуля dpcontracts программа будет тестировать себя самостоятельно. Вы научитесь тому, как и для какой цели использовать данные инструменты, а также тому, каким образом сочетать их с остальной частью своего тестового комплекса.

Введение
Сегодня мы поговорим про генерирующее тестирование (generative testing), которое проводится с помощью спецификации, как полностью, так и частично основанной на контрактах, а также с помощью формальных методов. Если все эти слова не имеют для вас никакого смысла, значит вы пришли на то выступление, которое вам нужно.
Используемый в данном выступлении код будет не питоническим (pythonic), поэтому я сообщаю об этом на отдельном слайде. Не следуйте моим стандартам, они плохие.
Unit Tests
Во-первых, все присутствующие знают, что представляет собой модульные тесты (unit tests). Поднимем руки, прекрасно. Большинство. Кто не знает, те, наверное, с YouTube.
Модульные тесты представляют собой мелкие функции питона, которые тестируют наш код. Например, я пишу функцию add, могу написать один плюс два равно три. Теперь мы можем воспользоваться модулем pytest. "Для записи", я предпочитаю pytest, а не unit test. Во-вторых, мы еще можем написать, наверное, ноль плюс ноль, ноль. Сложение с нулем дает то же число. Давайте добавим еще отрицательное число.


Вот, у нас получились модульные тесты (unit tests) для функции add. Суть в том, что правдивое название данного выступления не подразумевает отказа от unit tests. На фундаментальном уровне unit tests и в самом деле составляет основу того, что мы считаем хорошим поведением кода.
Поэтому я начну именно с этого. Пишите модульные тесты!

Так, теперь давайте выйдем за пределы модульных тестов. Обычно, когда думают по поводу того, чтобы выйти за пределы модульных тестов, речь идет про интеграционные тесты (integration tests). Это то, что тестирует более крупные участки кода. Если идти еще дальше за пределы этого, то там уже приемочное тестирование (acceptance testing). Таким образом, создается что-то вроде пирамиды. Самое простое и мелкое — внизу, а более сложное и комплексное — наверху.
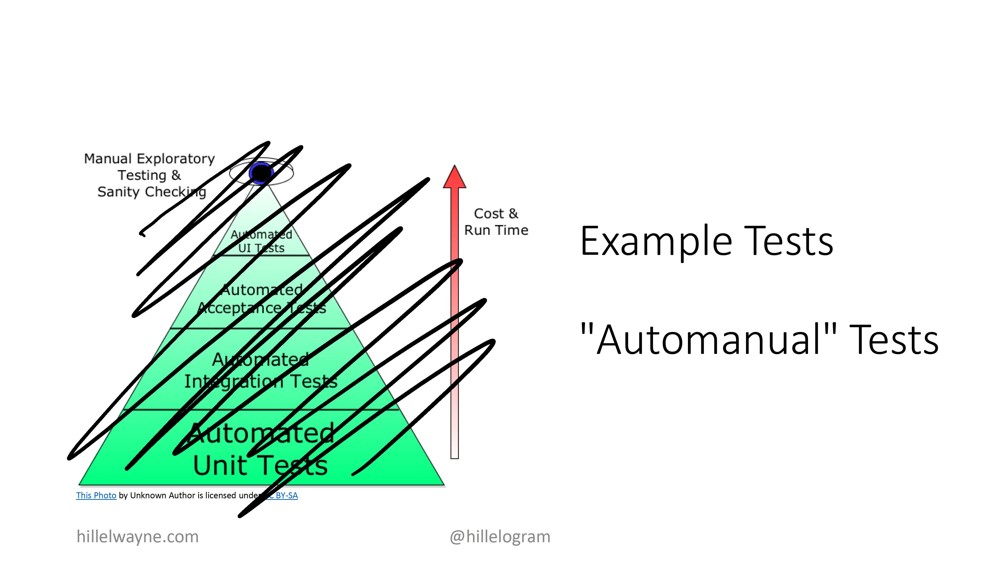
Все это мы сожжем прямо сейчас. Смотрите, дело в том, что все это мы называем полуавтоматическим тестированием (auto manual testing) или тестированием на основе примеров (example testing), потому что вы вручную пишете каждый тест, который запускается компьютером в автоматическом режиме. Опять-таки, все это очень хорошо, но есть несколько крупных недостатков.
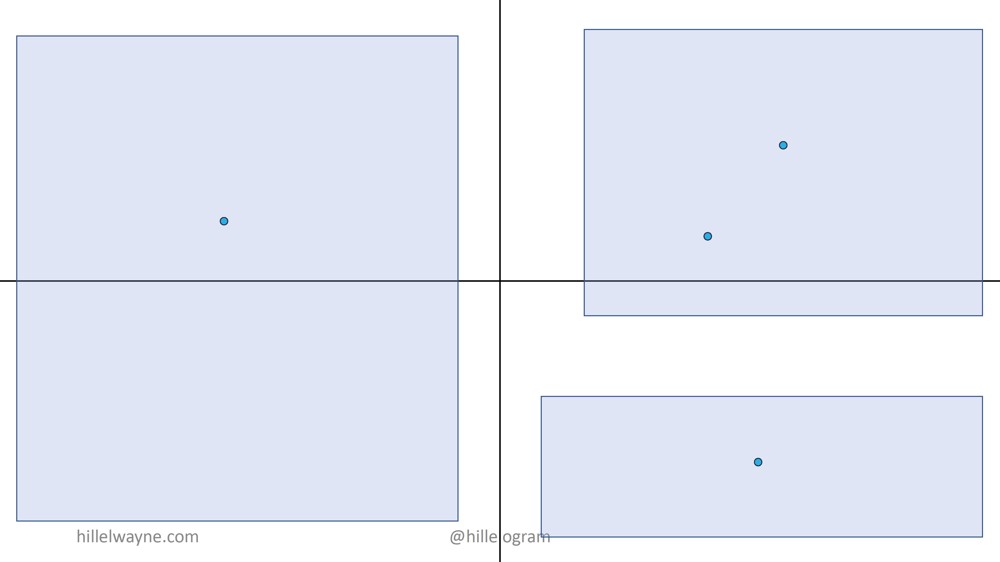
Вернемся к тому примеру с функцией add. Вот мое пространство состояний (state space).
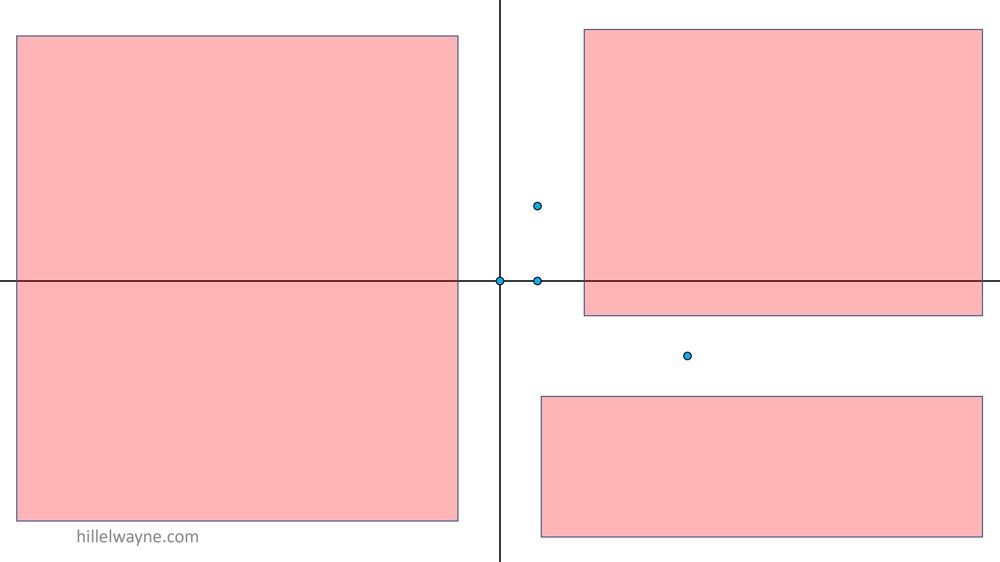
Что здесь показано. Здесь все возможные точки, которые мы можем ввести в функцию add. Здесь все четыре теста. В наше покрытие вошла немалая часть пространства состояний. Но на самом деле с этими вводными данными мы упустили два квадранта целиком. Это много.
Более того, что если существует несколько крайних случаев, которые мы полностью пропустили.
Можно подумать, конечно, что это простая функция, в ней нет конфликтующих ошибок.
Тестирование на основе свойств (property-based testing)
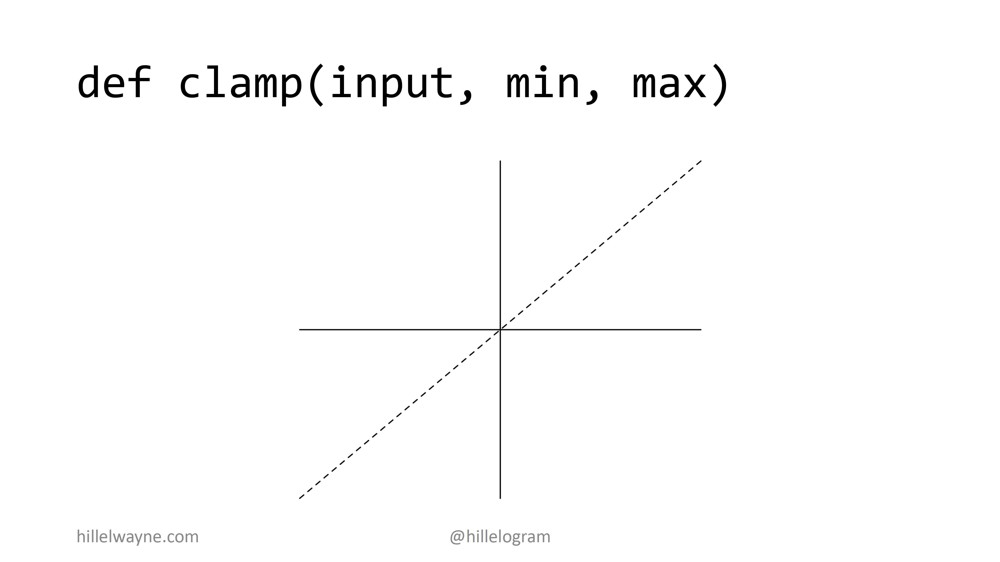
Но как насчет более сложных функций. Как насчет функции clamp, в которой есть третье пространство состояний. Теперь у нас три числа, а не два.
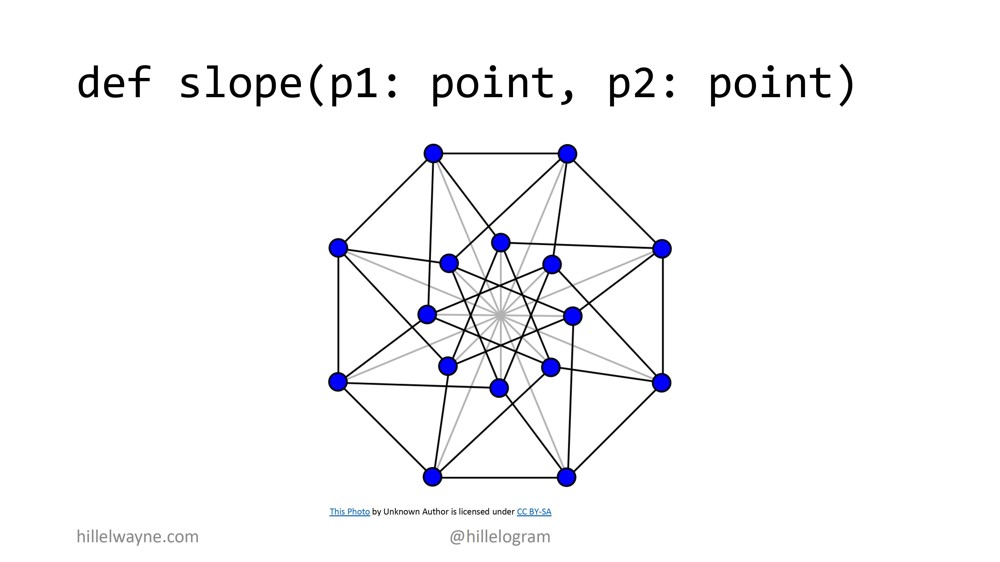
Как насчет, скажем, функции slope между двумя точками. Это будет что-то вроде странного пространственного гиперкуба.
Что если мы даже не знаем, какое пространство состояний в нашей функции. Как насчет функции leftpad. Какое вообще пространство состояний в left pad?

Вот, прямо сейчас вы уверены, что в состоянии прямо на месте вспомнить обо всех до последнего крайних случаях, с которыми нужно иметь дело в leftpad. Наверное, нет.
Поэтому нам нужно что-нибудь получше полуавтоматического тестирования, чтобы нам не приходилось вручную готовить рецепт каждого крайнего случая, который мы могли бы придумать. Нам нужен какой-нибудь способ обобщить это.

Именно это мы называем тестированием на основе свойств (property-based testing). Для записи, это не питонские свойства (Python properties), это понятие пришло из другого сообщества. Мы говорим о свойствах нашего кода. В качестве альтернативного термина подойдет тестирование инвариантов (invariant testing).
Я мог бы перейти к теории о том, как это выглядит. Но мне кажется, что за практикой попросту намного проще следить. Поэтому давайте и правда пройдемся по примеру.
Буду использовать библиотеку hypothesis, которая, возможно, является одной из лучших тестовых библиотек среди всех существующих языков программирования. Не только среди динамических языков (dynamic languages), не только среди постижимых языков (gripping languages). Просто — среди всех языков, точка. Ее создал Дэвид Макгайвер (David MacGyver). Он — гений. На самом деле, именно он задал основную тему для нескольких из этих конференций.
Вот мой генерирующий тест (generative test).
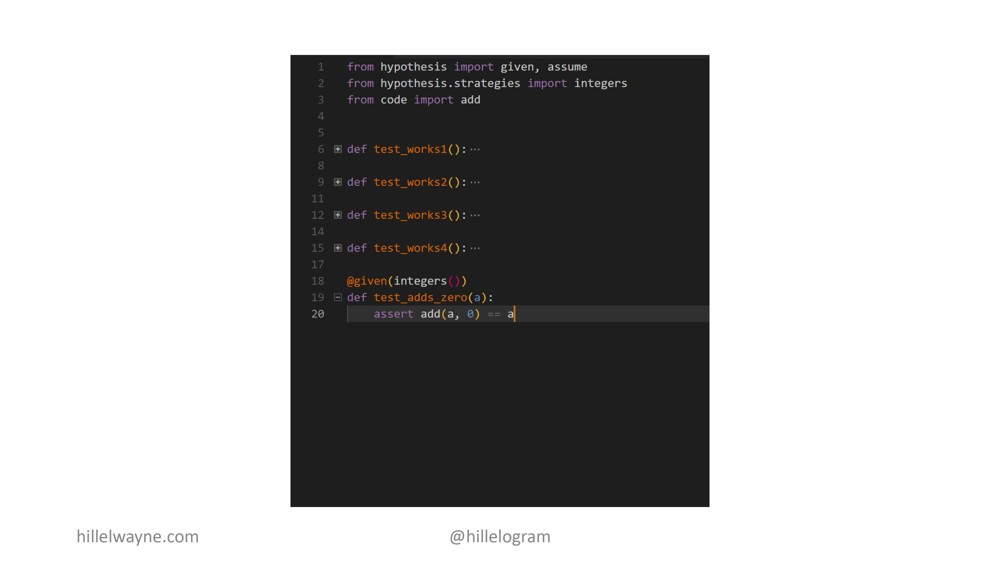
Если прибавить любое число к нулю, то будет то же самое число.

Выглядит совсем как любой другой тест. Давайте и правда посмотрим сюда внимательнее.
Так, написанное здесь похоже на любой другой вид теста, который мы бы написали. Скажем, сложение с нулем дает то же самое число. Это наш инвариант, это наше свойство. Этот ноль идентифицирует операцию сложения.
Данный тест отличается от любого другого только тем, что мы пишем декоратор given decorator прямо над ним. Теперь это больше не индивидуальный тест, а целый шаблон тестов. Следует использовать все, что соответствует стратегии, а в данном случае стратегией являются числа (integers), и создать на основе этого все тесты, которые придут в голову. Питон будет просто подчиняться.
Посмотрим, на что это похоже при запуске:

Результат "5 passed in 0.20s" похож на любой другой вариант, который мы бы написали, даже несмотря на то, что мы прогнали примерно сто тестов. В первую очередь, мы протестировали все цифры от 1 до 20, ноль. Затем мы протестировали большие числа, огромные отрицательные числа, а также все патологические вводные данные, которые можно было бы найти.
На самом деле, если добавить другие данные, например, если указать в качестве стратегии строки (strings), питон попробует китайские иероглифы, символы Unicode, попробует 10 000 неразрывных пробелов. Он ищет крайние случаи, о которых мы, будучи людьми, чаще забываем.
Это было успешное выполнение теста. Теперь давайте получим отрицательный результат. Для этого я попробую другое свойство (property).

Таким свойством будет коммутативное сложение, то есть А + В всегда равно В + А. Сейчас нам нужны два вида вводных данных, две стратегии. Мы можем попросту расширить свой декоратор @given, чтобы он это охватывал, просто добавив еще один параметр. Давайте посмотрим, что случится после запуска этого варианта.
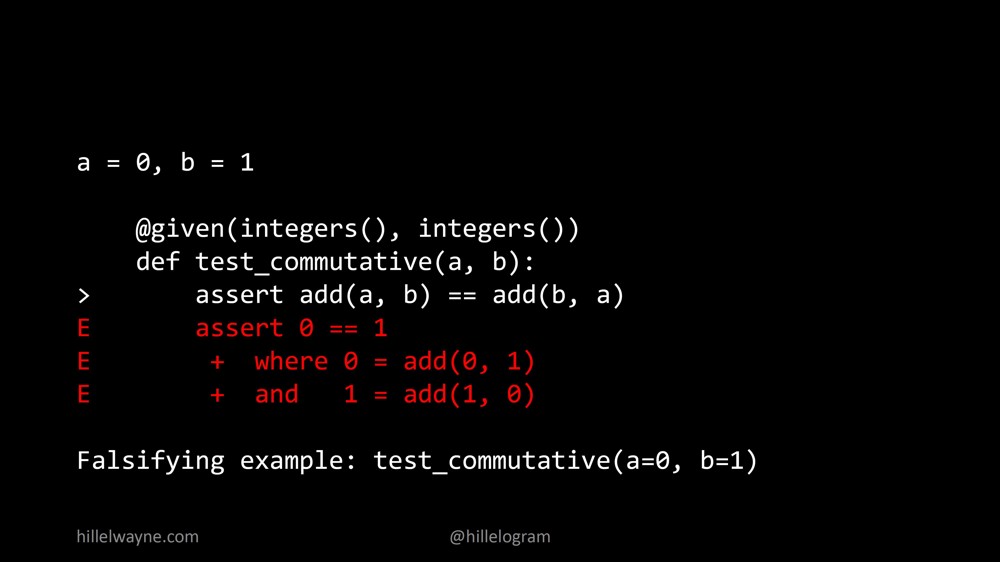
Мы получили ошибку. Оказалось, что наша функция на самом деле не была коммутативной.
Итак, что здесь происходит на самом деле. Все выглядит практически так же, как другие неудачные тесты за исключением того, что мы дополнительно видим вводные данные. Оказывается, если а = 0, а b = 1, то почему-то наша функция add дает нам 0 на одной стороне и 1 на другой стороне. В этом нет никакого смысла.
Так получилось потому, что моя функция add прошла модульный тест (unit test), и это означает, что она была верной. Вот как она выглядит:

Когда я поднимаю данную тему, мне часто задают два вопроса. Первый: если мы хотим использовать рандомизированное тестирование (randomized testing), как мы поймаем регрессии (regressions). Оказывается, питон кэширует все найденные неудачные варианты и попробует их в будущих запусках.
Поэтому, если я теперь поправлю свою функцию add:

Что же случится? Мы протестируем 1 и 0 в любом случае. То есть, мы дополнительно можем добавить конкретный пример, который заставит программу тестировать его каждый раз.
При этом нельзя забывать, что мы по-прежнему стремимся выйти за пределы модульных тестов (unit tests).
Мы не заменяем их чем-то другим, и общая стратегия заключается в том, чтобы unit tests поймал правильное поведение, а тест свойств (property test) прошелся по всему пространству состояний в поисках неправильного поведения.
В этом случае появляется еще одна проблема. Как найти хорошие свойства? Я хотел бы пройтись по более проработанному примеру. Оказывается, при использовании тестирования на основе свойств мы чаще представляем себе паттерны тестирования почти так же, как паттерны написания кода.
Давайте попробуем более сложный пример.

Здесь речь про максимально возможное произведение двух элементов списка. То есть, 2 * 5 = 10, 1 * 5 = 5, 1 * 0 = 0. Поэтому результат должен быть 10.
Я попросил одного своего очень умного друга, который сейчас работает на Scala в Берлине, написать функцию, которая будет это делать. Вот, что у него получилось.

Сначала мы проверяем, что в списке достаточно элементов, потому что он — очень осторожный программист. Если данное условие не выполняется, вызывается ошибка питона TabError. Затем мы сортируем список, берем два максимальных элемента и перемножаем их.
Еще я попробовал несколько модульных тестов. Их тоже написал друг, о котором я говорил.

И вновь у нас очень хорошее покрытие (coverage). Мы пробуем патологические вводные данные, у нас широкий диапазон теста, мы пробуем большие вводные данные, мы пробуем не связанные между собой вводные данные. Все, что можно.
Давайте по-быстрому поднимем руки, кто из присутствующих при виде этого кода и этих тестов будет в разумной степени уверен, что все корректно. Примерно половина. Неплохо, думаю, некоторые из вас видят, в каком месте сейчас баг. Кто-то не видит. Так оно всегда и бывает, мы — люди, мы не можем видеть всего.
Так, сначала давайте возьмем что-то работоспособное.

Я могу написать тест свойств, в котором дается список чисел. Попробую не только пустой список, но и списки с одним, двумя, двадцатью элементами. Тест позволяет нам создавать вложенные стратегии. Хотя, если мы попробуем пустой список, то тест сразу же будет неудачным, потому что вводные данные некорректные.
Поэтому нам нужно убедиться, что тест пробует только такие списки, в которых элементов два или больше.
Мы можем сделать это, просто добавив один параметр в свою стратегию. В списке должно быть не меньше двух элементов. Теперь данный тест свойств будет успешным.

Поищем более сложное свойство. Допустим, у нас есть вот это:
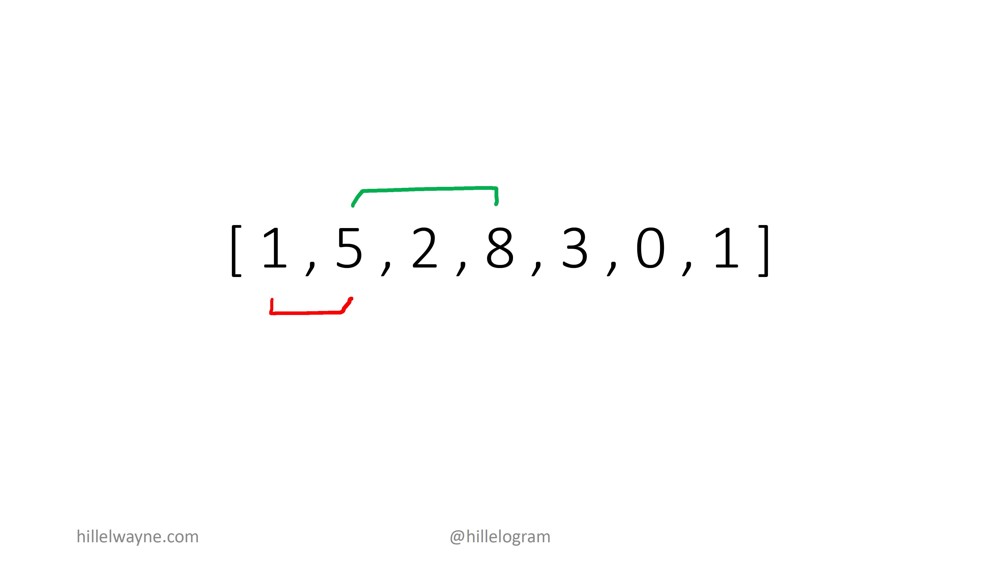
Вводные данные предусматривают, что максимальное произведение составляет 5 * 8 = 40. Это будет максимально возможный результат. То есть, если я возьму другую пару чисел, например два числа в начале, у меня будет переменная с показателем не больше максимума. В виде кода это выглядит так:

Мы добавили утверждение (assertion) о том, что максимальное значение функции max_product во всех случаях больше или равно произведению первого и второго элемента. Если запустить тест с этими свойствами, мы тоже очень быстро увидим вот это:
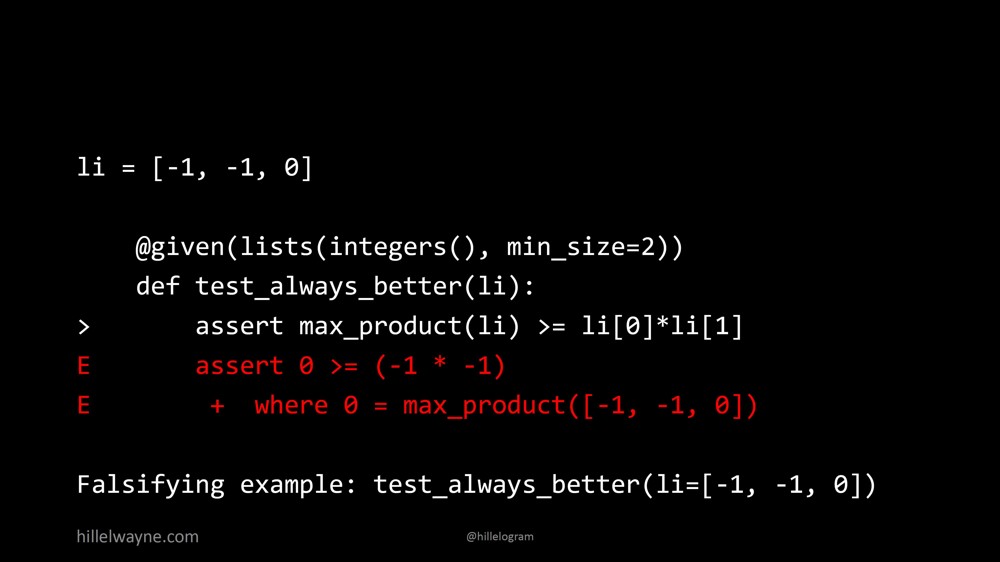
Будем искать ошибку. Оказывается, мы совершенно не учли отрицательные числа. Напомню, что умножение двух отрицательных чисел дает положительное число. Поэтому умножение числа -1 на само себя дает 1. Однако максимальное произведение после сортировки элементов в данном случае представляет собой 0 и -1. Это дает результат 0, который меньше 1.
Интеграционное тестирование (integration testing)
Итак, тесты свойств предоставляют довольно хорошие возможности для покрытия модульных тестов (unit tests). Однако в данных вопросах я не люблю останавливаться на достигнутом. Хочу идти дальше. Хочу посмотреть, можем ли мы использовать это в интеграционном тестировании.
С интеграцинными тестами проблема в том, что сделать это гораздо сложнее.
Потому что вместо одной изящной и сжато написанной функции у вас все эти модули, которые взаимодействуют с другими модулями. Во-первых, это превращает поиск хороших тестов свойств в нетривиальную задачу. Но еще хуже то, что при виде сообщения об ошибке, когда наше свойство ломается, мы, конечно, понимаем, что ошибка где-то там:
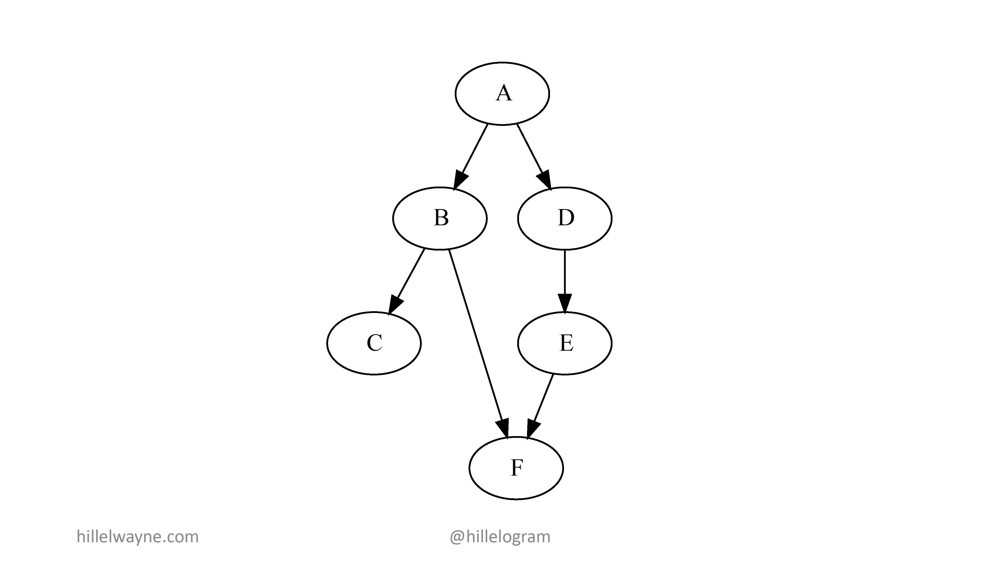
Мы не знаем, возможно она в А или в В.
В идеале мы хотим, чтобы тесты свойств каким-нибудь образом давали нам хорошую инвариантность, которую мы могли бы с легкостью найти для большой системы, а также чтобы локализовать проблему. На самом деле это все очень сложно. Именно поэтому многие тестировщики обращаются к Agile.
Нужно просто писать как можно меньше интеграционных тестов и как можно больше модульных тестов. Нам такое не нравится, мы — человечество, запустили кабриолет в космос, поэтому мы должны быть в состоянии написать несколько интеграционных тестов.
mypy
Оказалось, что на самом деле существует по-настоящему элегантный способ сделать это. Но, чтобы увидеть своими глазами, нам придется заехать к mypy. Обещаю, мы просто ненадолго заедем. Кто здесь слышал про mypy. Снова — большинство из вас, прекрасно.
Итак, mypy — отдельная программа, которая ищет статические ошибки типизации (static type errors) в коде питона (Python). Ее разрабатывает основная команда питона, так что это официальный инструмент. Однако она существует отдельно от питона. С ее помощью можно добавить примечание, аннотацию о типе (type annotations).

Скажем, функция add принимает пару чисел и возвращает новое число. Что случится, если я сделают что-то неправильное, скажем добавлю строку Х + Y, а затем запущу питона:

Он покажет мне данную конкретную ошибку по возвращаемому типу переменной. Мы получили строку (string), но ожидали число (integer). Для меня в этом всем замечательно то, что питон не сказал об ошибке в данной функции. Он сказал, что ошибка здесь, в выходных данных. Это означает, что он может принять вводные данные, локализовать баг в функции самостоятельно, даже ничего не запуская.
Однако, что мы сделали с функцией дальше:

Если, допустим, у меня корректная функция и я вызываю ее с помощью функции g, в которой число 1 и строка. При этом, mypy также локализует баг в данном конкретном параметре. Она знает, что функция может быть как корректной, так и некорректной. Но наши входные данные, очевидно, неверные.
Все это очень круто, потому что когда мы говорим про интеграционную цепочку, у нас нет возможности это локализовать. Поэтому мы наблюдаем тенденцию на эйфорическое восприятие статической типизации (static typing). Мы слышим о том, что типизация нас спасет, чудесно, мы нашли ответ.
Но это тоже не работает от слова "совсем".

На самом деле, это не будет ответом, и причиной тому не только сам питон (Python), но и почти все остальные языки, какие только есть, за исключением нескольких нишевых языков для академических исследований. У вас не так много возможностей с типизацией. Какую-то структуру вы указать можете, но вы ничего не сделаете с поведением, потому что оно существует как отдельная от вашего кода система.
Что нам нужно на самом деле, так это способ использовать всю мощь языка для тестирования своего кода и проверки его корректности. Мы не можем сделать этого со статической типизацией, но мы можем сделать это во время выполнения.
Вот как мы могли бы переписать этот код, чтобы выполнять проверку на типы во время выполнения, а не в ходе компиляции.

Все то же самое за исключением того, что теперь мы добавили требование об использовании выражения assert, которое проверят, чтобы инстансы Х и Y были числами. После этого мы делаем аналогичную проверку для Z. Здесь речь идет про выражения assert (assert statements). Если какое-нибудь из них окажется неверным, у нас появляется ошибка Assertion Error. Поэтому теперь во время выполнения мы делаем с помощью питона абсолютно то же самое, что и в ходе компиляции.
Возможно, это в реальности не так уж возбуждающе, но дело в том, что мы открыли целую вселенную внутри питона и можем писать любые выражения assert для любых нужных нам проверок.
Поэтому давайте посмотрим, как это применимо к более сложному примеру с функцией tail, которая принимает список и возвращает его целиком, исключая первый элемент.

Вновь оказывается, что в большинстве языков невозможно охватить данное поведение с помощью только системы типизации, потому что не получится разделить возврат хвоста и полный возврат без последнего элемента. Попробуем.
Сначала используем способ с проверкой типов. Мы принимаем любые списки и выводим любые списки, возвращаем пустой список.

Проверка проводится, все хорошо.
Однако, если я запущу список [1, 2, 3]:

Я получу пустой список. Это вовсе не то, чего мы хотим, это никак не связано с нашими реальными намерениями. Поэтому мы хотим как-нибудь проверить, что наши выходные данные — корректные.
Для этого нужно спросить себя, как будет выглядеть функция tail, если взять хвост элементов и добавить его к отрезанному элементу.

Мы получим первоначальный список. Так и должно быть. В реальности, по сути, голова плюс хвост равно первоначальный список.
Вот и давайте сделаем такое утверждение (assertion).

Мы используем временные переменные выходные данные и делаем утверждение о том, что добавленный (appended) в начале выхода (output) элемент позволяет создать выход, равный первоначальному списку. Что произойдет, когда мы это запустим.
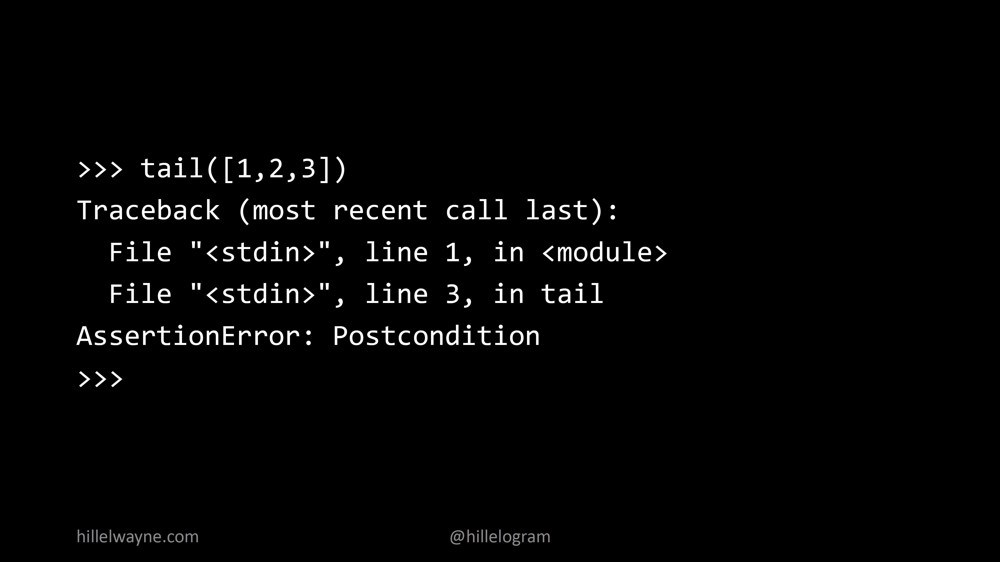
Мы получили ошибку Assertion Error. Я добавил данное постусловие (post condition) для создания лога. Изначально такого в коде нет, это тоже не по-питонски.
Итак, во всем этом интересно то, что если я напишу корректную версию:

Просто используем слайс. Теперь все работает прекрасно, ошибок нет. Видим наше постусловие после его вызова.
Но еще мы хотим убедиться, что не вызываем свою функцию с плохими данными. У нас не должен проходить вызов функции со строкой, поэтому в данном случае потенциальными плохими данными могут оказаться пустые списки.
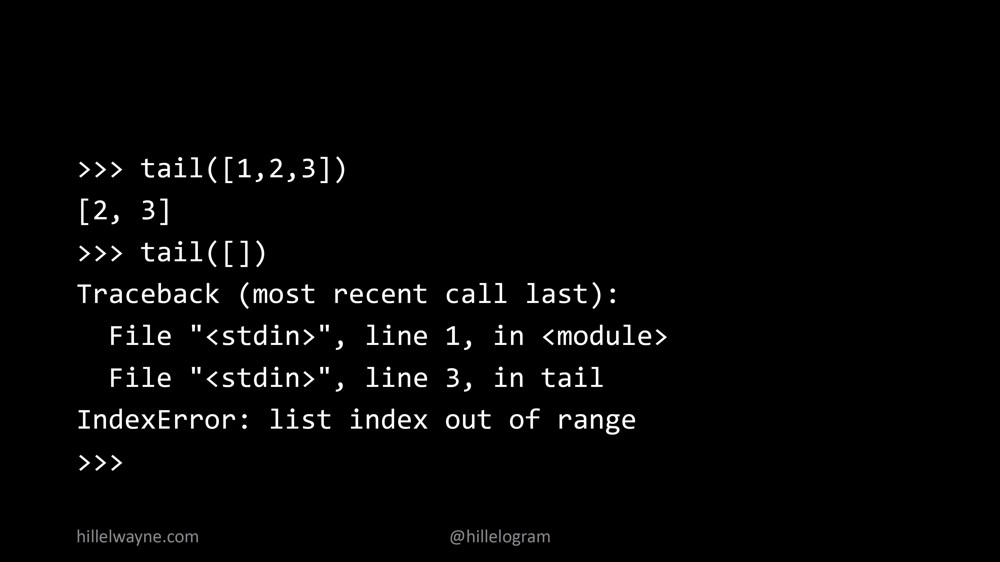
Здесь мы получим ошибку индексирования Index Error. Для пустого списка хвост не определяется, потому что нет смысла получать хвост от пустого списка. Но мы не хотим просто вызывать ошибку индексирования, мы хотим на фундаментальном уровне запретить такое и сказать программе, чтобы она не запускалась при таких условиях, когда где-то в цепочке что-то происходит не так и вызывает такое поведение.
Поэтому мы можем добавить предварительное условие (precondition) в утверждение assert. Длина списка должна быть больше нуля.

Обратите внимание, что утверждение для списка здесь тоже есть, потому что условие по поводу пустого списка стоит в начале нашей политики. Но я очень хотел бы обратить внимание на то, что мы хотим получить списки больше нуля.
Теперь при запуске мы получаем ошибку предварительного условия Precondition Error.

Вот так мы подошли к тому, что мы называем контрактами.
Обусловленное проектирование (design by contract)

Идея обусловленного проектирования состоит во внедрении утверждений, которые должны быть верными при выполнении кода. Если условие утверждения (assertion) не выполняется, мы останавливаемся, начинаем с начала и ищем баг.
Все это может показаться очень простым, но на самом деле это одна из самых сильных техник проверки из всего, что нам известно. Мы проверяли ее эмпирически на самых разных масштабах, но в основном это было в сфере авиаэлектроники, критических систем, оборонки, науки. Поэтому никто об этом не слышал. Честно говоря, считаю это просто невероятным. Ну вот кто из вас слышал про Ada, кто по-настоящему вникал в то, какие возможности у Ada.
Ладно, на самом деле я провел несколько экспериментов. С помощью Ada можно сделать невероятное, но, поскольку это Ada, всем без разницы. Давайте перенесем это все в питон (Python).
Контракты
Первым делом нам нужна библиотека, мы любим библиотеки. Но проблема в том, что эти методики очень-очень малоизвестны, к сожалению. Они не заслуживают такого. В общем, это означает, что библиотеки — плохие.
Для питона есть несколько различных библиотек с контрактами. Я буду пользоваться библиотекой contracts Роба Кинга (Rob King).

Это связано с тем, что почти все остальные библиотеки почти не выходят за пределы проверки типов во время выполнения. Нам это не нужно, потому что уже есть mypy. На самом деле, это сильно снижает эффект, который мы можем получить от контрактов. Давайте переделаем наш код с помощью этой библиотеки.

Итак, во-первых, у нас декоратор required, в котором мы задаем свойство и функцию с булевым выражением. Если функция возвращает True — прекрасно, а если False — будет вызывана ошибка Assertion Error. На самом деле это условие распространяется на все аргументы, которые мы используем, поэтому можно написать args.l, а не просто l.
Теперь нам не нужно предварительное условие, мы получили аналогичный результат. Мы можем оставить постусловие или ввести проверку. Это полностью совпадает с нашим предварительным условием за исключением того, что у нас еще есть доступ к выходным данным.

Так что мы можем избавиться от него. На самом деле, поскольку здесь остаются не нужные нам выходные данные, та временная переменная нам больше не нужна. Можно просто вернуть l[1:].

Прекрасно, мы все сделали. В чем же была цель всех этих действий, когда мы добавляли к функции tail ряд новых данных. Именно тут история становится по-настоящему интересной. Какой, на мой взгляд, мы могли бы написать тест свойств для tail.
Сначала дам небольшую подсказку. Нам нужно убедиться, что для выполнения предварительного условия мы вызываем список как минимум с одним элементом. Сейчас дам вам несколько секунд подумать по поводу подходящего в данном случае теста свойств. Вот что я бы написал:

Полная спецификация
Оказывается, с помощью контрактов мы сделали полную спецификацию функции tail. Мы в точности корректно и с полным пониманием своих действий определили сущность функции tail.
Это означает, что любое отклонение от всей этой идеи вызовет ошибку контракта Contract Error. А это оначает, что для проверки функции tail на корректность нам достаточно вызывать ее с разными входными данными и убедиться, что условия всех контрактов выполняются.
Пусть даже это все может казаться игрушечным примером, но на самом деле мы можем так оформлять множество различных функций. На самом деле, давайте вернемся к функции max_prod.
Оказывается, контракты обычно создаются для тестирования и разработки, а не для использования во время выполнения. Поэтому им можно быть очень медленными. Я могу написать вот так:

Посмотрим на функцию is_max_prod. Что мы тут делаем. Мы попросту принудительно запускаем все возможные сочетания индексов, перемножаем их и убеждаемся, что результат меньше максимального. Это подойдет для функции is_max_prod, но вместе с тем будет очень-очень медленно. Но нам неважно, мы ведь просто проводим тест.
Поэтому, если мы напишем работающий вариант:

Мы можем использовать функцию max_product или декоратор ensure. После этого нам надо протестировать эту функцию целиком с самого начала.

Теперь просто вызываем ее во время теста свойств (property test). Теперь у нас есть есть нужные нам тесты, которые позволят убедиться в корректности функции max product.
Должен признаться, не всегда получится создать полную спецификацию. Ее можно сделать для чистых функций. Но когда мы начинаем добавлять, например, мутации, глобальные переменные или сторонние системы, становится сложнее, но, честно говоря, главная ценность не только в полной спецификации. Частичной спецификации, когда мы добавляем несколько свойств, по-прежнему достаточно, чтобы дать нам что-нибудь по-настоящему замечательное.
Поэтому мое мнение такое:

Контракты (contracts) плюс тесты свойств (property tests) равно интеграционные тесты (integration tests). Что мы под этим всем понимаем. Давайте вернемся к началу всей нашей цепочки запусков питона (Python).
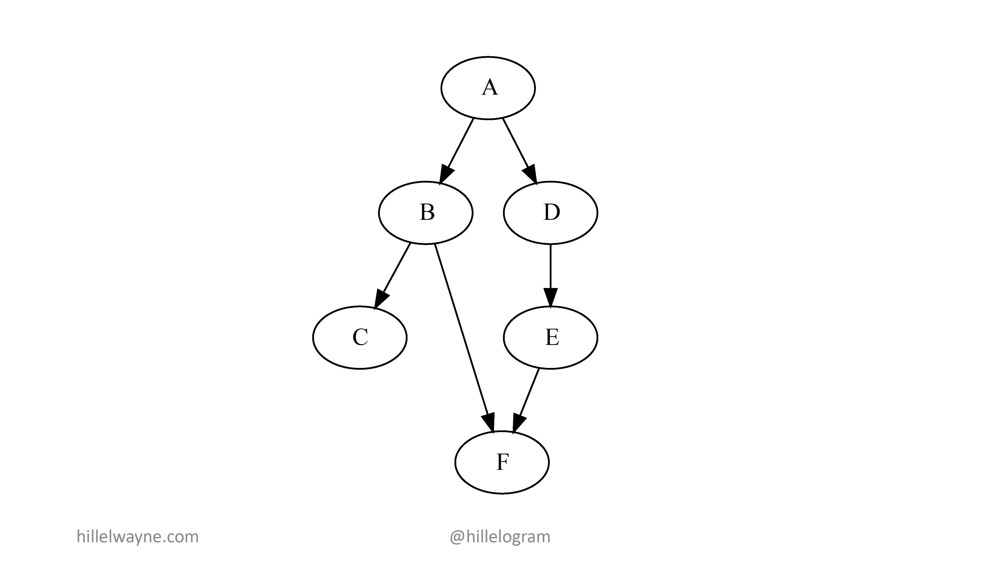
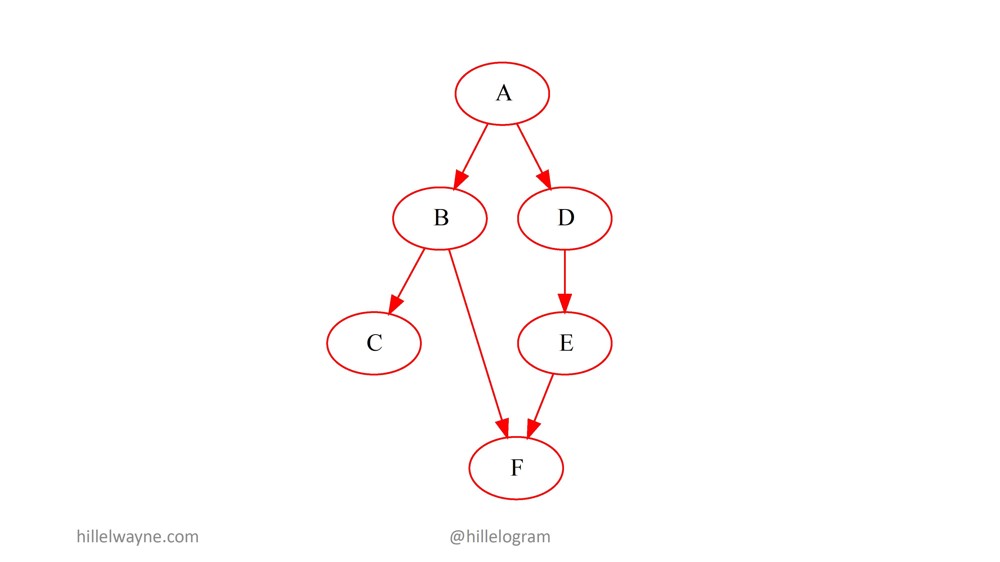
Данное изображение уже не является точным воспроизведением того, что мы на самом деле делаем. В реальности у нас скорее что-то вроде этого:
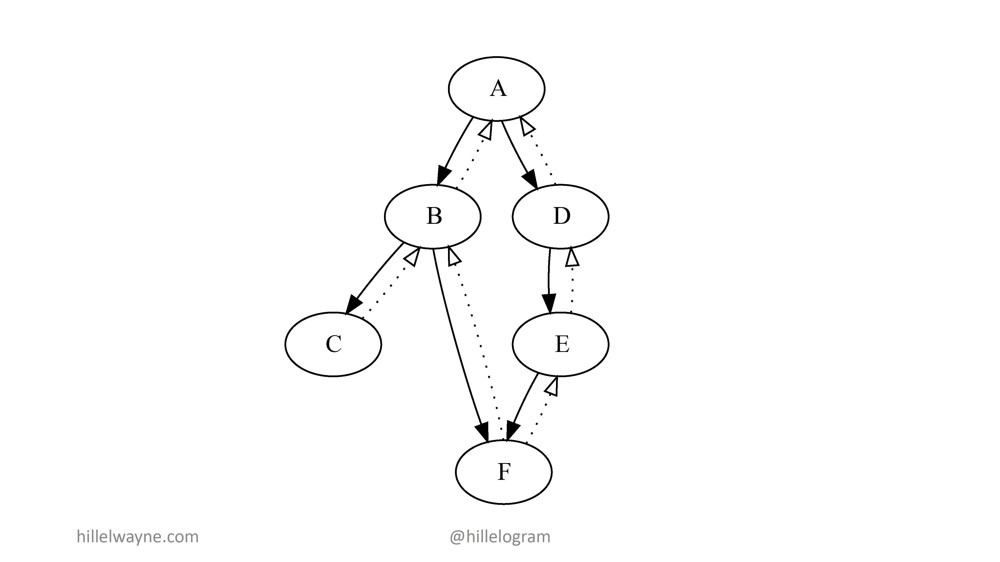
А вызывает В и реализует требования В, когда В возвращается к А. В ней предусмотрены свои постусловия. Затем В вызывает С и F, а также реализует их требования. И так далее, и так далее.
Во-первых, что это нам дает. Это дает то, что необходимо выполнить большое количество инвариантов для проверки каждого контракта. Но еще важнее то, что каждая ошибка теперь локализована.
Например, если В вызывает F и нарушает предварительное условие F, у нас появляется ошибка.
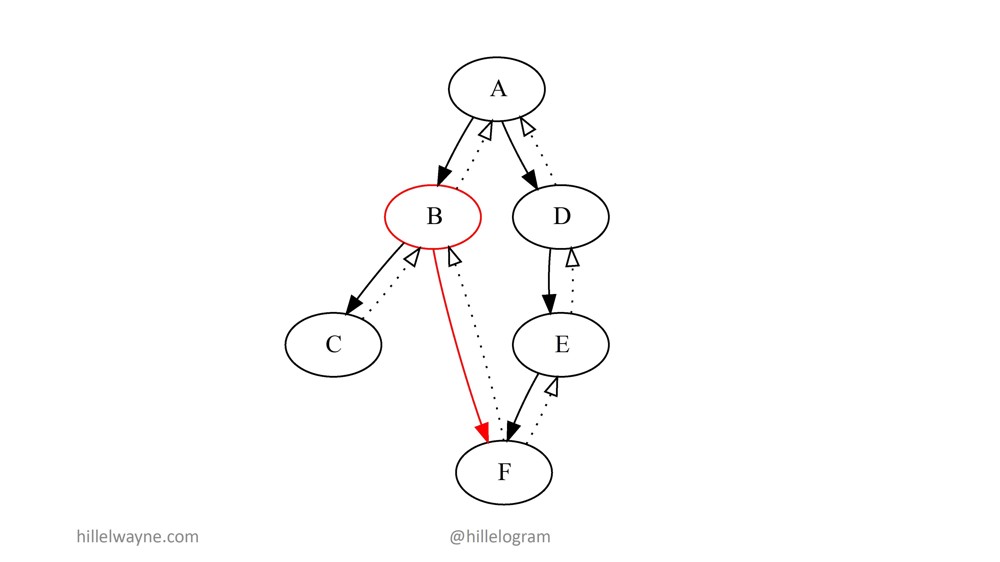
Кроме этого, мы теперь знаем, что мы локализовали В и должны искать баг там и в нашей интегрированной системе для модуля В.
Но если В в порядке, но F нарушается:
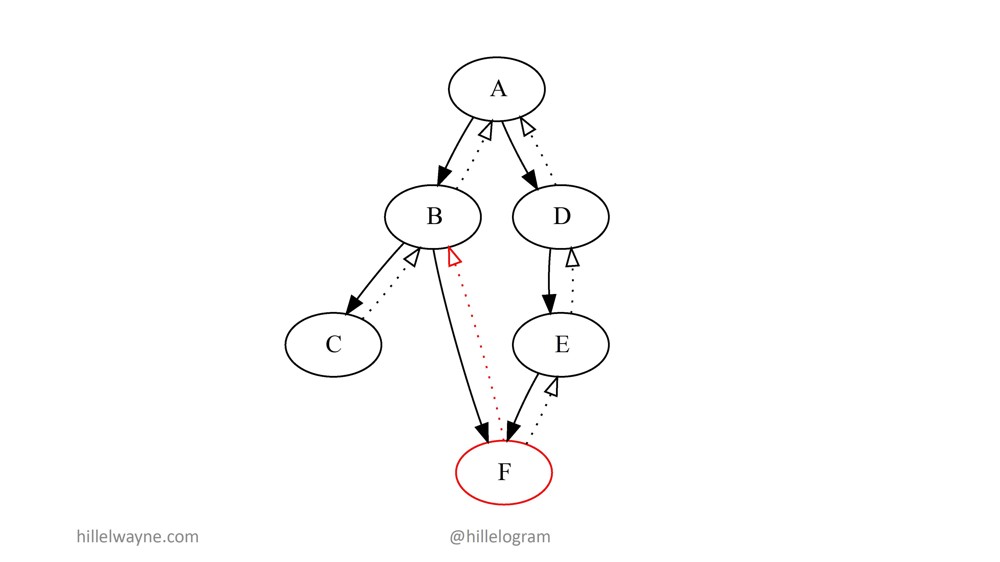
Мы получим ошибку постусловия Post Condition Error, и мы моментально поймем, после одного взгляда на ошибку, что баг в F.
Даже если мы добавим тест на А, который может сказать нам: "Хорошо, ты вызвал А с тестом свойств. Баг — в F", если В возвращает на А что-то не то, мы знаем, что, вероятно, С и F вызываны корректно. Однако, с учетом всех данных, баг на С и F. Повторюсь, полной уверенности нет, но вероятность очень высокая. Причем очень-очень маловероятно, что баг на D или E либо обязательно на F.
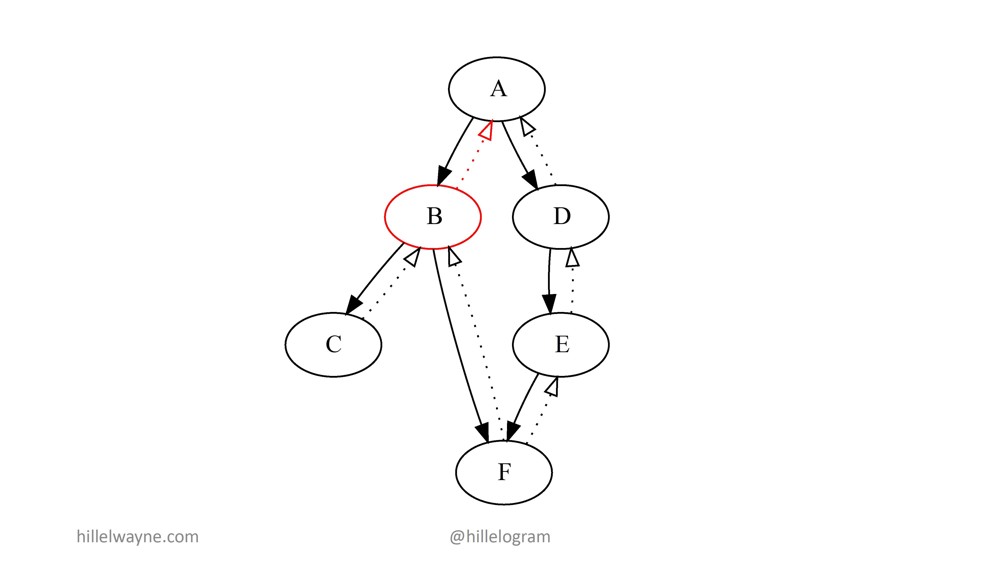
Мы отрезали половину модулей, которые могли бы содержать баг, с помощью одних только контрактов. На самом деле, это было показано во множестве различных баз исходных кодов (code bases) на самых разных масштабах.
Классы инвариантов (class invariants)
Именно так мы стараемся делать высокоточное и высоконадежное ПО. И даже не только так. Мы можем пойти дальше и расширить обе эти идеи, чтобы охватывать больше вещей. На этой теме я задержусь немного покороче, потому что не хочу погружаться в тему. Сделаю только быстрый обзор.
Во-первых, у нас есть классы инвариантов. Под ними понимаются свойства, которые всегда должны быть верными для классов, имеющих внутреннее состояние (internal state).

В классе BankAccount есть публичный метод, который может пройти по всем его непубличным методам за раз. Но к тому моменту, когда он закончит, не должно оставаться овердрафтов со значением True.
Тестирование с фиксацией текущего состояния (stateful testing)
Вот теперь мы можем сказать, что если есть какая-нибудь мутация состояния, мы можем подтвердить, что мутация, которую мы создаем для своего состояния, не выходит из системы и не попадает в не подходящее для нее состояние.
Так мы получаем тестирование с фиксацией текущего состояния (stateful testing)
Оно дает тестирование изменяющегося состояния. У нас есть концепция тестирования с фиксацией текущего состояния или тестирования на основе моделей (model driven testing) из библиотеки hypothesis. Такое тестирование помогает не только с вводными данными, которые можно попробовать, но и помогает определить поведение функций.
Например, такое тестирование позволяет вызвать функцию add_num два раза c xbckfvb 3 и 5, а после этого вызывать функцию reciprocal, а после этого вызывать ее повторно. Наконец, мы можем вызывать функцию add_num еще пять раз. Можно выбирать вводные данные, последовательность и количество шагов.
Если мы будем использовать такое тестирование с полной системой, оно позволяет создавать полноценное приемочное испытание (acceptance testing). Мы можем симулировать на нашем веб-сайте случайные и сделанные где попало клики пользователей. Мы можем симулировать прерывания, вызанные сторонними системами. Мы можем симулировать все, что захотим с помощью этого функционала. Мы можем пользоваться им, что прокрасться через свой код еще раз в поисках самых незаметных и самых критических багов.
Более безумные вещи
После этого мы можем получить еще более безумные вещи.

Все это трудно найти в питоне (Python), но можно перенести с помощью различных библиотек.
Во-первых, у нас есть тестовые генераторы Clojure. Они могут смотреть на контракты в коде и определять, какие вводные данные допустимы в наших тестах свойств. Они могут сказать, что вот они ваши контракты, и что тесты следует генерировать только с числами.
Eiffel. Мы можем создавать контрактные классы, правила наследования (inheritance rules) на основе того, каким образом осуществляется наследование в контрактах между различными классами. Eiffel может пользоваться этим функционалом, что формализовать по-настоящему элегантную форму питона, не виданную больше нигде, ни в каких других языках. По сути, это позволяет сказать, что питон — это язык, в котором много формальной верификации.
Ada. Мы можем вводить в контракты утверждения с глобальными эффектами. Скажем, строке кода, в том числе ее различным версиям или связанным с ней цепочкам функций или процедурам, не разрешается затрагивает определенного рода глобальное состояние. Либо наоборот, она должна затрагивать другой вид глобального состояния. Либо должна вести или не вести лог. И это еще дальше расширяет наши возможности с такой спецификацией.
Dafny. Здесь у нас есть статическая верификация (static verification). После одного взгляда на контракты компилятор может сказать, что есть баг, даже не нужно выполнять, нужно найти какие-нибудь тесты.
Наконец, есть, на мой взгляд, по-настоящему прекрасные вещи, которые можно делать в питоне 2 (Python 2), например, с абстрактными базовыми классами (abstract base class) в точках входа (hooks) внутри подклассов.
Мы можем сделать по-настоящему удивительные вещи с динамической метатипизацией во время выполнения (runtime dynamic meta typing). Данная сфера еще не изучалась как следует ни в одном языке, но я уже работаю с парой примеров с time. Надеюсь, что смогу достичь большего с этим, чтобы охватить основы как полагается.
Заключение

Хочу сделать короткий обзор. Что у нас есть. Модульные тесты (unit tests), которые реализуют тесты свойств (property tests). У нас есть mypy, которая может реализовать так называемые контракты (contracts). Еще у нас есть интеграционные тесты (integration tests), которые по сути реализовали сочетание тестов свойств и контрактов.
Вот две вещи, которыми я пользуюсь. Hypothesis и Contracts.

Пара мыслей в заключение. Во-первых, гвоздь данного выступления:

Они правда помогут вам, если у вас нет твердой почвы. И вы знаете, что тесты как раз ее создают.
Во-вторых, формальные методы (Formal Methods):

На самом деле, я не обсуждал суть этой идеи. Это именно то, что мы зовем формальными методами. Это исследование того, как мы можем доказать корректность ПО на уровне, недоступном ни одному языку с современной производительностью. Ничто не может подойти к тому уровню, который нам доступен с формальными методами. Хотя Ada может, но не берите в голову.
Однако, все это большей частью всегда было нишевой методикой в определенных отраслях и в науке. На самом деле, никто не думал о том, как мы можем использовать это для все существующих языков.
Оказывается, то, о чем я говорил — совмещение тестирования свойств и контрактов — является одной из идей, которую можно с легкостью использовать в любых других языках по своему желанию. Особенно в питоне (Python).
Так что здесь есть несколько по-настоящему прекрасных идей, которые просто нигде не изучались.
На самом деле, думаю, что в ближайшие десять лет новые уровни добавленной стоимости и большие части прорыва в корректности проявятся тогда, когда мы наконец научимся использовать формальные методы в реальном мире.