- Введение
- Понятие об операторе
if statement - Недостатки оператора
if - Виды плохого кода и варианты рефакторинга
- Составные условия
- Вложенные условные выражения
- Дубликаты условных выражений
- Кейс с рефакторингом кода
- Минимально жизнеспособный продукт
- Расширение функционала
- Абстракция более высокого порядка
- Расширение функционала
- О чем следует помнить
- Заключение
- Дополнительные материалы
Введение
Хочу сказать спасибо организаторам от Python и всем сотрудникам Python Software Foundation, потому что подготовить конференцию — это много тяжелой работы. Было трудно, но вы смогли перенести PyCon из Питтсбурга в сеть.
Я по-настоящему ценю этот шанс поделиться своими знаниями с сообществом и вообще со всеми. Спасибо, что подключились послушать мои жалобы по поводу условного оператора (if statement). Будет смешно. Меня зовут Элай Сивджей (Aly Sivji), меня можно найти в твиттере.
Еще я участвую в организации группы пользователей Python в Чикаго, одной из самых больших в мире. У нас примерно 6 000 пользователей. Каждый месяц мы проводим 4-6 мероприятий. Обычно я бы позвал вас поучаствовать, но сейчас нам пришлось отменить все личные встречи до тех пор, пока крупные мероприятия не станет безопасны.
Понятие об операторе if statement

Данное выступление посвящено оператору if statement как показателю плохого кода (code smell). Начну с того, что не собираюсь ругать ничей код. Просто хочу поделиться опытом, благодаря которому могу использовать схему написания немного более понятного и подходящего для тестов кода.
Итак, что такое оператор if. Это элемент языка программирования, который помогает нам контролировать, какие выражения следует исполнять.
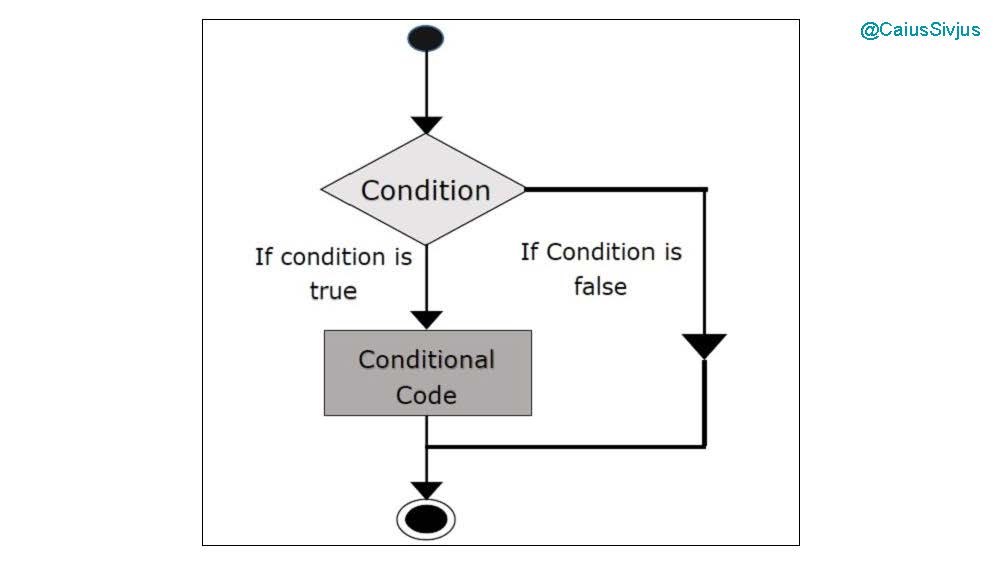
Обычно, когда мы запускаем программу, она исполняется сверху вниз построчно. Когда она добирается до условного оператора, то, если условие выполняется (то есть, оно дает ответ True), находящийся под ним блок кода исполняется. Если условие не выполняется (оно дает ответ False), то этот блок кода пропускается, и программа продолжает исполнение, как будто его вообще не существует.
Давайте перейдем к конкретике. Вот немножко питона.
# ... code
if today == user.birthday:
print("Happy Birthday!")
# code ...
Наш код проверяет будет ли переменная today равна дню рождения пользователя. Если условие выполняется, мы выводим (print) сообщение с поздравлением. Если нет, то пропускаем его и продолжаем исполнение программы, как будто этого кода не существует.
С помощью оператора if у нас есть возможность давать компьютеру указания о том, что следует делать при выполнении заданного условия. Соединив условные операторы в цепочку, можно выполнить любую задачу. Это очень сильная концепция. Не зря условные операторы стали фундаментальным строительным блоком в большинстве языков программирования.
Недостатки оператора if
Однако, если в вашем коде слишком много условных операторов, то код очень сложно проследить и еще сложнее модифицировать. Например, этого может быть макаронная логика кода. Мы постоянно скроллим вверх-вниз, прыгая между модулями, пытаясь проследить за нитью кода и понять, что в нем происходит.
Еще бывает так, что пишут длинные функции, которые делают много разных вещей. Например, это могут быть взаимосвязанные функции, которые не будут сгруппированы логически.
Поэтому, если мы плохо перенесем концептуальное решение в свой код, то следить за ним будет по-настоящему трудно. Например, это могут быть плохие имена для переменных или названия функций. Мы можем применять линейную логику, а не абстракцию более высокого уровня.
Все это означает, что у нас код, который трудно модифицировать. Когда нам нужно внести какое-нибудь изменение, то придется пройтись по нескольким частям кода. При добавлении нового функционала нужно модифицировать ранее написанный код, чтобы этот новый функционал ужился с имеющимся кодом.
Еще часто бывает так, что по всей базе кода разбрызганы дубли одной и той же логики. Поэтому когда нам нужно что-то поменять, данное изменение надо будет вносить много раз в самых разных частях кода, причем ни в коем случае не забыв ни одного блока.
Это очень трудно, особенно если нет тестов. Как же мы тогда узнаем, что изменение внесено корректно и ничего не поломало в уже имеющемся функционале? Без понятия. Так что наш код трудно понимать и трудно обновлять. Перед нами плохой код, как говорится, с душком.

Такой подход к программированию ИНОГДА показывает, что где-то сделан неверный выбор. Подчеркну, что плохой код не всегда говорит о наличии проблемы. Но если есть трудности с пониманием, то мы можем упростить эту логику.
Вообще, писать код на основе условных операторов очень долго. Мы можем упростить и модифицировать схему кода, чтобы продвигаться быстрее.
Виды плохого кода и варианты рефакторинга
Составные условия
Во-первых, это составные условия для выполнения блока под условным оператором.
Если в наше выражение с оператором if заложено одно условие, то его сравнительно легко прочитать.
# ... code
if today == user.birthday:
print("Happy Birthday!")
# code ...
Но вот когда мы заготавливаем составные условия, становится чуть-чуть сложнее переварить логику.
# ... code
if today.month == 6 and today.day == 21:
print("First day of summer")
# code ...
Чем больше сложностей мы закладываем в свои условные выражения, тем сложнее понимать нашу логику.
# ... code
if year % 4 == 0 and (year % 100 != 0 or year % 400 == 0):
print("Leap year")
# code ...
Предлагаю переделать условия в булевую переменную (boolean variable) или функцию.
Вернемся к условному выражению с двумя компонентами.
# ... code
if today.month == 6 and today.day == 21:
print("First day of summer")
# code ...
Рефакторинг кода может заключаться в вынесении условия в отдельную переменную с понятным описательным названием. Затем мы используем эту переменную в выражении с оператором if:
# ... code
first_day_of_summer = today.month == 6 and today.day == 21
if first_day_of_summer:
print("First day of summer")
# code ...
Эту переменную можно использовать и в том более сложном условном выражении, и еще много-много раз.
Как вариант рефакторинга, можно переделать выражение в функцию, чтобы код стал более читаемым.
# ... code
def leap_year(year):
return year % 4 == 0 and (year % 100 != 0 or year % 400 == 0)
if leap_year(year):
print("Leap year")
# code ...
Вложенные условия выражения
Еще одна схема программирования, усложняющая чтение кода — это вложенные выражения с оператором if (nested if statements). Они включают в себя серию подчиненных выражений, которые приобретают форму наконечника стрелы.

Какие проблемы создает такой код.
Во-первых, в таком коде высокая цикломатическая сложность (cyclomatic complexity). Это такая метрика для количества отдельных ветвей кода. Чем выше цикломатическая сложность, тем код сложнее для понимания и еще сложнее для тестов.
Кроме того, для глубоко вложенных условных выражений остается слишком узкая строка с небольшим количеством символов. Чем дальше вложенность выражения, тем больше пробелов нужно ставить.
Второй совет по поводу рефакторинга кода связан как раз с выравниванием вложенного кода.
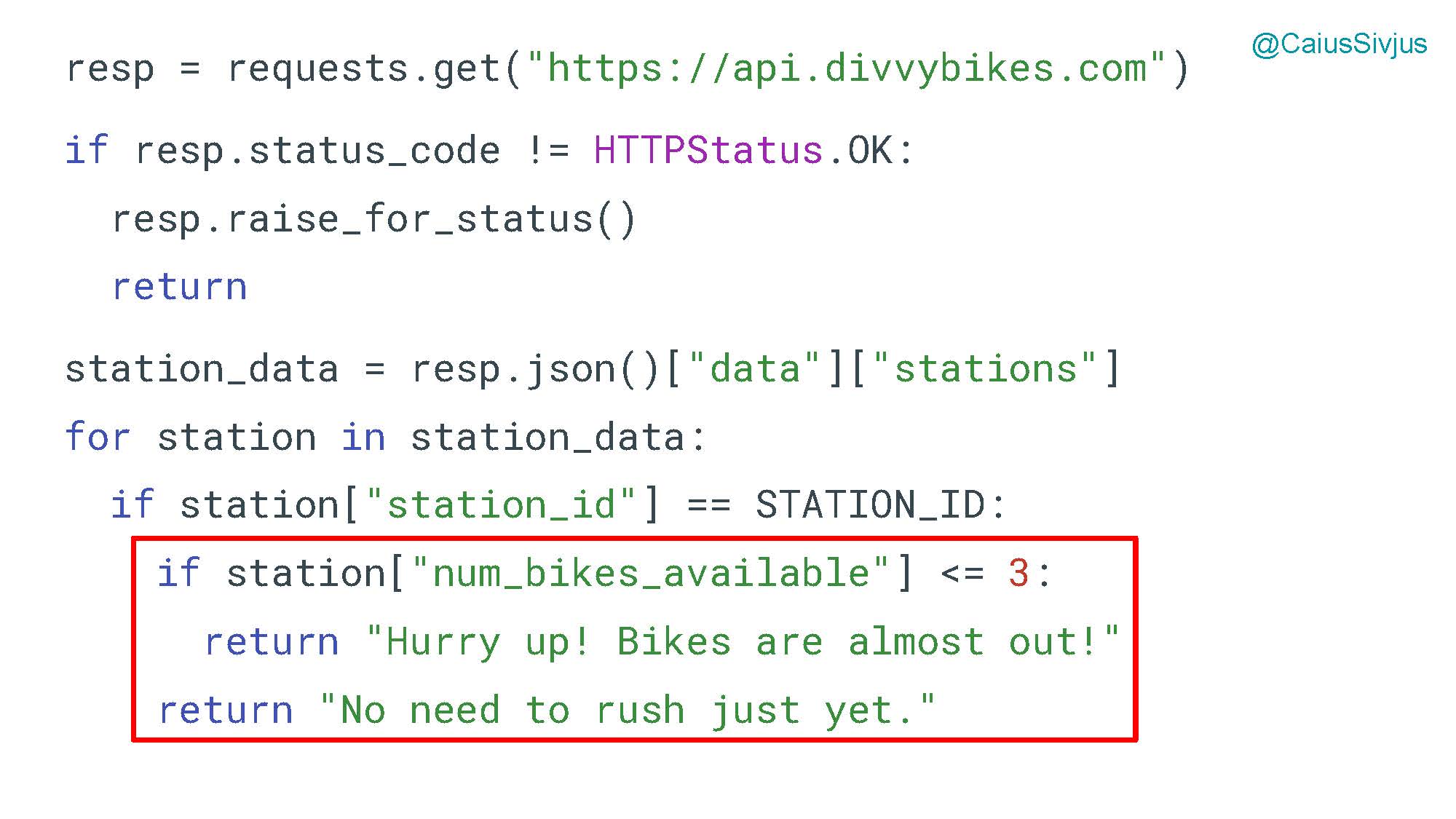
Пускай примером станет программа совместного пользования велосипедами у нас в Чикаго. У нее будет открытый API, а у меня дома — панель с количеством велосипедов, доступных для использования на ближайшей станции.
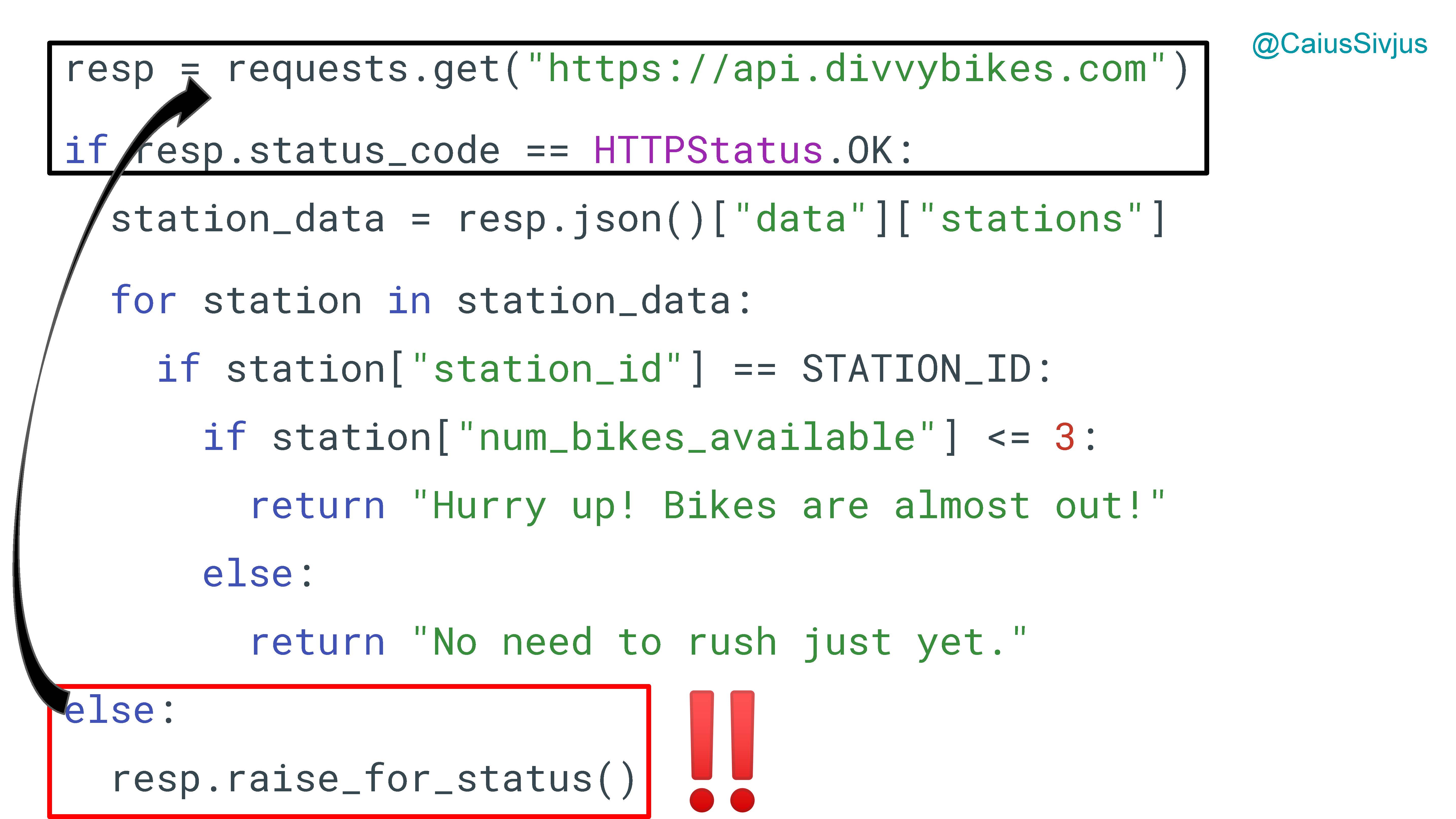
Давайте пройдемся по коду, который создает эту панель. В нем используется библиотека requests, которая соединяется с API. Мы получаем ответ (response), и если он 200, то мы получим данные со станции. Затем мы запустим цикл for loop по всем доступным станциям и найдем ту, которая нужна именно нам.
Далее, если количество велосипедов меньше или равно заданному пороговому значению (здесь это будет 3), то мы вернем сообщение о том, что нужно поспешить ("Hurry up! Bikes are almost out!"). Если же велосипедов больше порогового значения, то мы возвращаем другое сообщение о том, что их много и торопиться не нужно ("No need to rush just yet.")
resp = requests.get("https://api.divvybikes.com")
if resp.status_code == HTTPStatus.OK:
station_data = resp.json()["data"]["stations"]
for station in station_data:
if station["station_id"] == STATION_ID:
if station["num_bikes_available"] <= 3:
return "Hurry up! Bikes are almost out!"
else:
return "No need to rush just yet."
else:
resp.raise_for_status()
Наконец, если первый запрос получает не 200 в качестве ответа, то мы можем выбросить исключение. Оно окажется достаточно далеко от того кода, с которым связано.
Есть много способов, с помощью которых можно выровнять вложенный код. Основные из них следующие:
- всегда добавлять строку о возвращаемом значении как можно раньше;
- заменить условное выражение контрольным оператором (guard clause);
- заменить проверку на положительный ответ проверкой на отрицательный ответ;
- дополнительная информация
Итак, что можно сделать с этой программой. Сначала мы добавляем контрольного оператора (Guard Clause), который проверяет код статуса на случай, если ответ будет не 200. Это дает возможность объединить логику завершения программы в этом случае, а остальной код не будет иметь посторонних элементов.
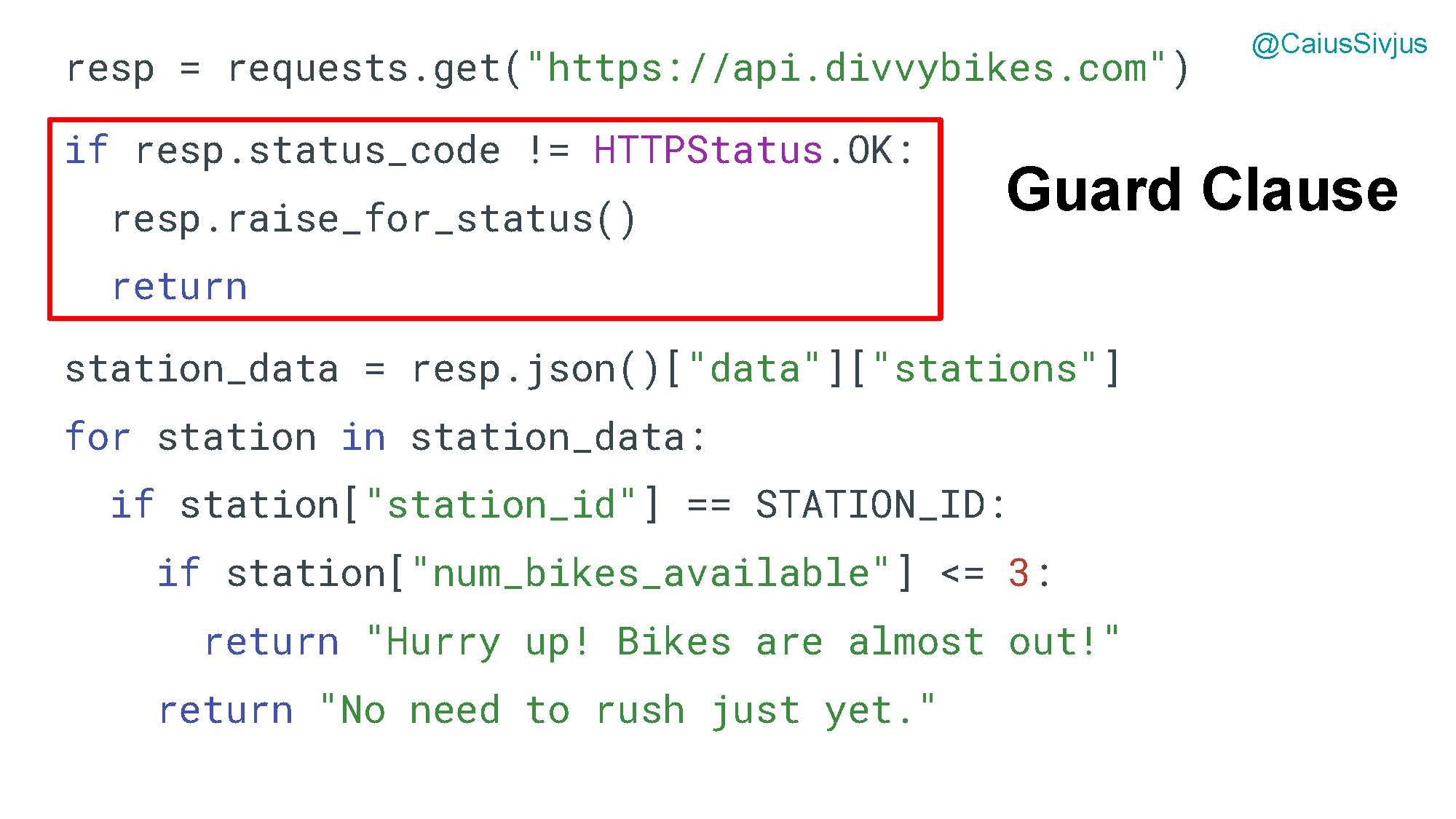
Также обратите внимание, что в новом варианте полностью удален блок else, потому что он не приносит никакой пользы.
Дубликаты условных выражений
Еще один вид плохого кода, который мы сегодня обсудим — дубли выражений с оператором if, набрызганные по всему коду.
Если сравнивать эту проблему с рассмотренными ранее, то их легко найти и исправить, а эту проблему найти тоже легко, но исправить уже сложнее. Это связано с тем, что найти новое решение можно только основательно погрузившись в задачу.
Каждому из нас приходилось заниматься этим, т.е. многократно пробегать по всему коду вверх-вниз, пытаясь проследить логику. На самом деле, это не такая уж проблема, если нет планов менять код.
Однако, если есть намерение в будущем вносить обновления, то, возможно, есть смысл попробовать другой вид абстракции.
Кейс с рефакторингом кода
Минимально жизнеспособный продукт
Давайте изучим пример с дублированием условных выражений из чикагской базы Python. У нас есть бот по имени "busy beaver" (занятой бобер) для освещения активности пользователей гитхаба. Одна из его функций — создавать ежедневные резюме активности в специальном канале для зарегистрированных пользователей:

Как мы можем реализовать этот функционал. Можно создать цепочку условный выражений для реализации любой задачи. Например:
- получение данных из API
- классификация событий по видам
- подсчет статистики событий
- генерация текста резюме
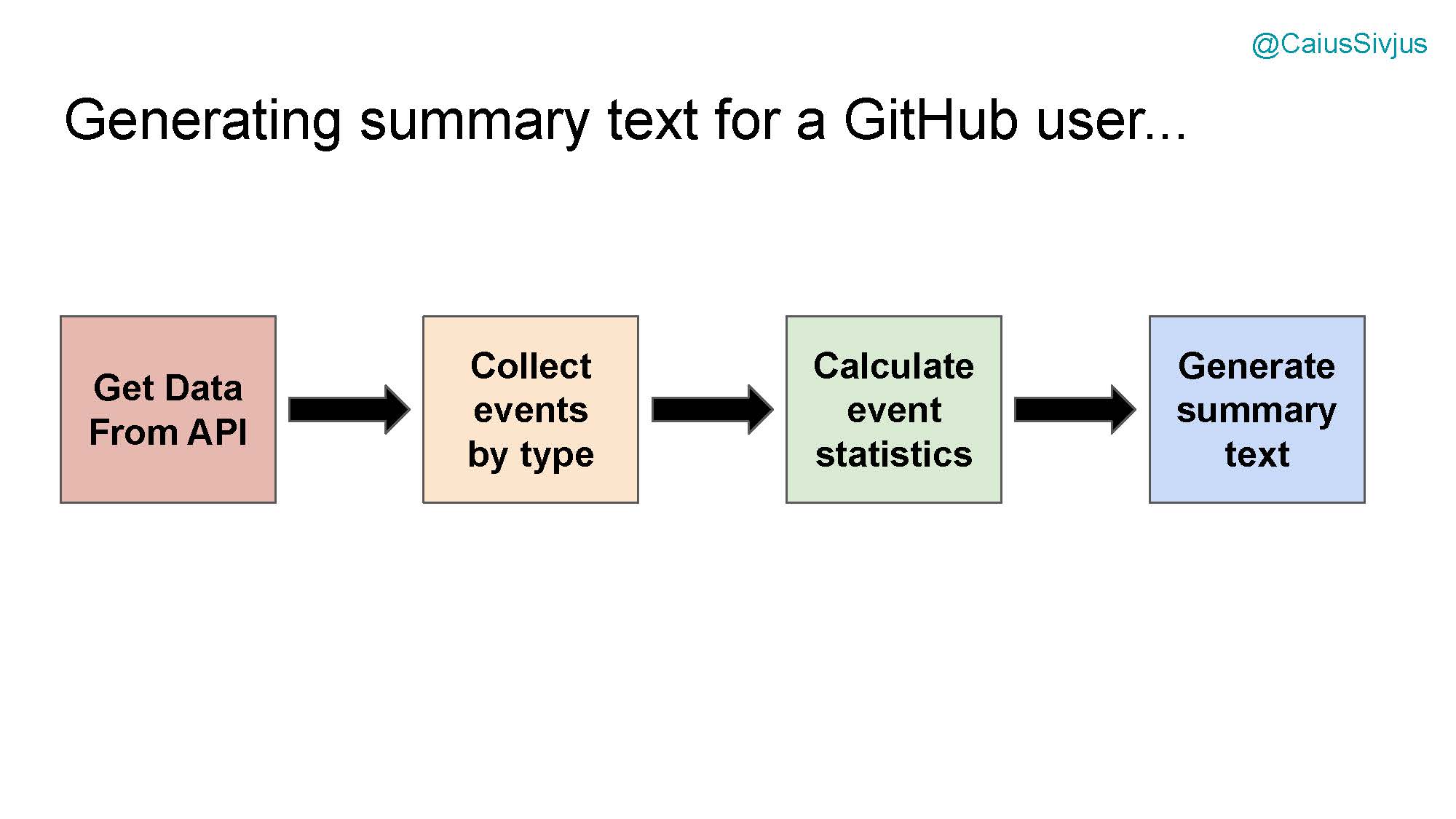
Чтобы создать минимально жизнеспособный продукт (Minimal Viable Product), мы будем отслеживать два вида событий. Нас интересуют все коммиты пользователя и все репозитории (будем отталкиваться от количества звезд).
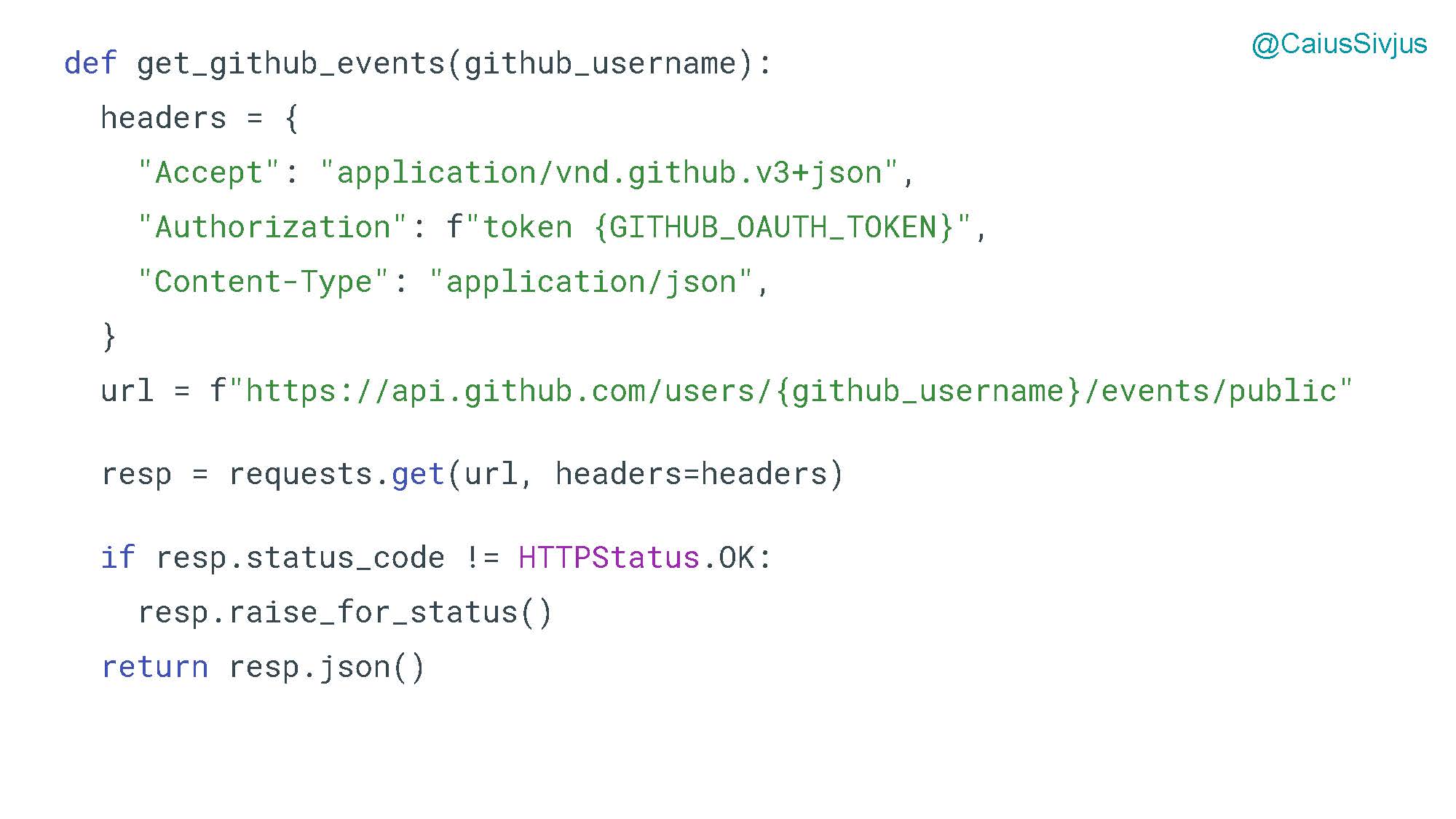
Начнем с получения данных через API гитхаба, функция get_github_events. Мы определим нужные заголовки и возвратим JSON. Вполне обычный вариант для использования requests:
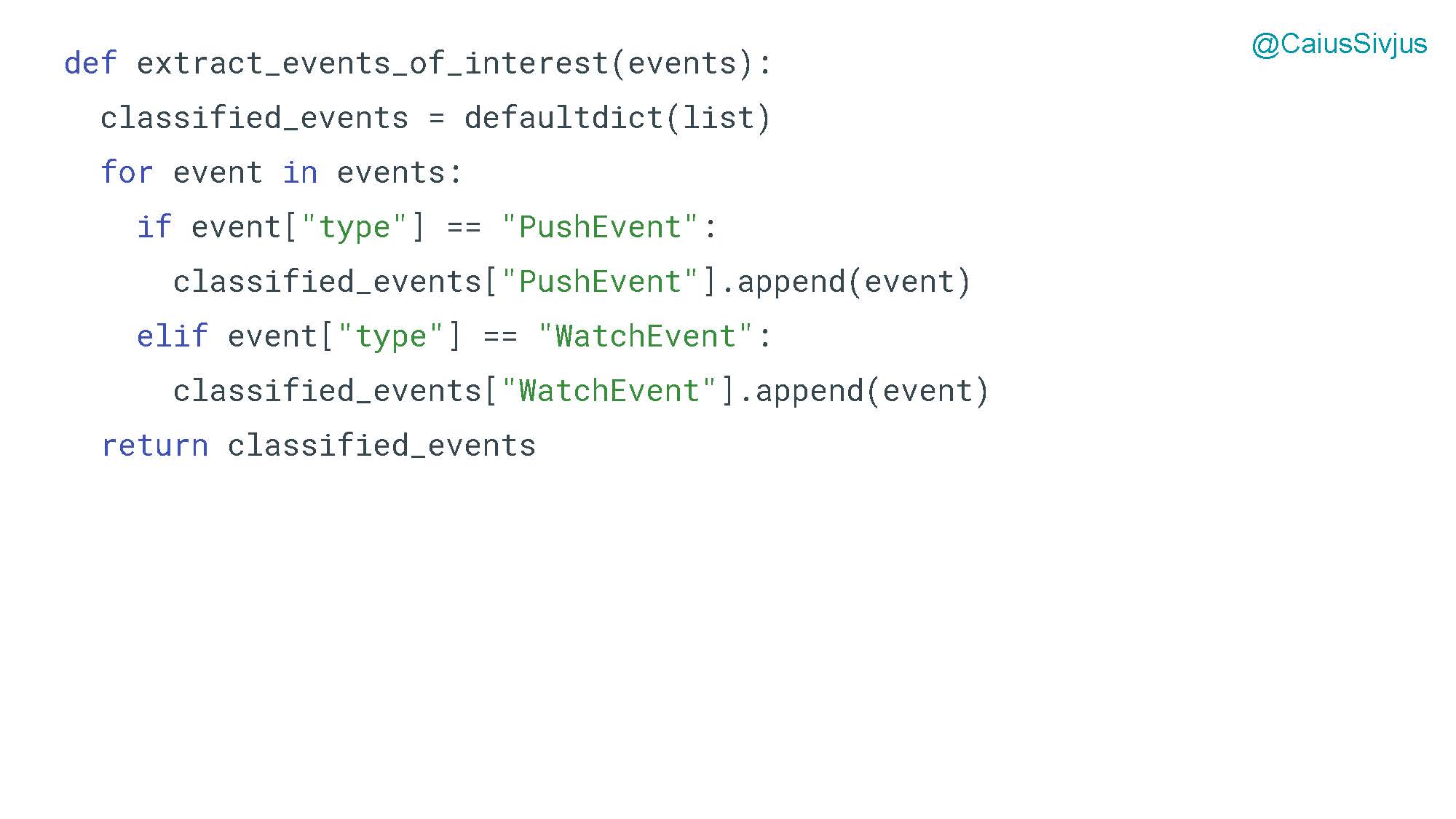
Далее мы извлекаем интересующие нас события из JSON. Делаем цикл итерации по всем событиям, которые содержатся в полученном от гитхаба словаре. В конце функции мы возвращаем итоговый вариант словаря classified_events. Его ключом будет вид события, а значением — список всех событий нужного вида:
Наконец, мы создаем текст резюме по всем нужным нам событиям. Сначала мы делаем заголовок, затем пройдемся по всем парам ключ-значение нашего словаря и под конец обновим текст в зависимости от вида события. В итоге функция возвращает текст резюме:
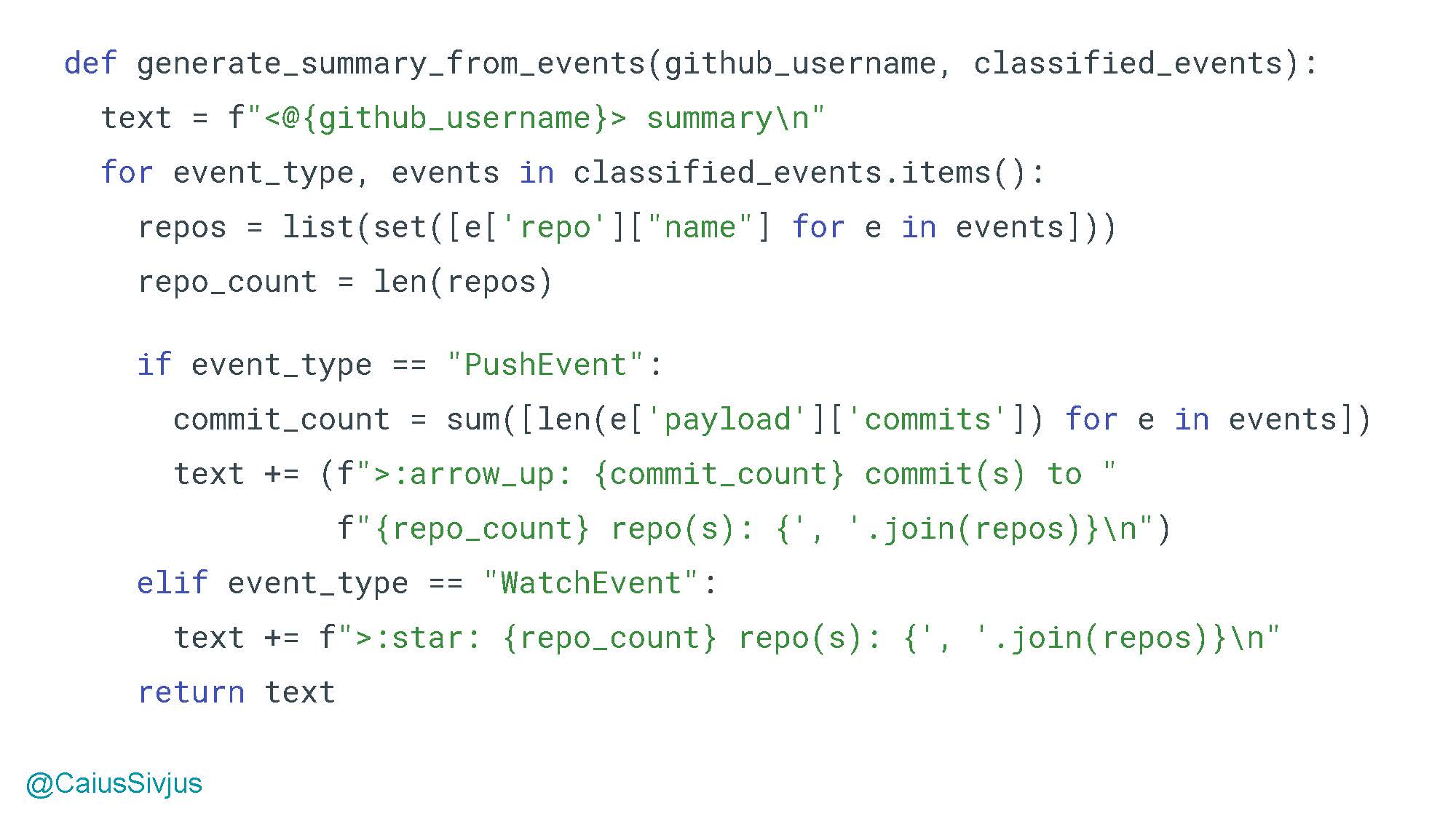
Функция perform объединяет данную логику и выполняет задачу, поставленную перед программой:
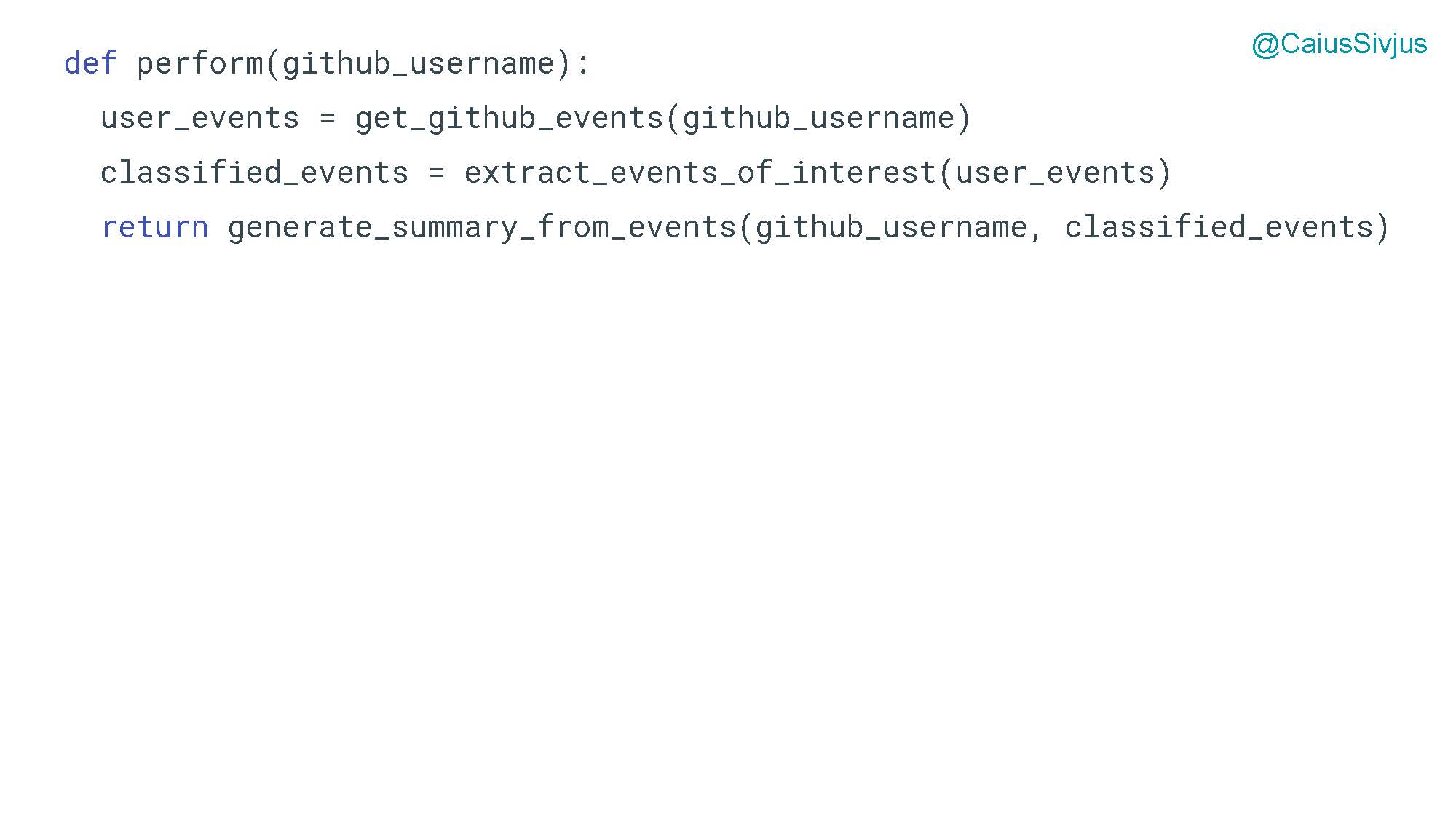
Вот так у нас получился минимально жизнеспособный продукт.
Расширение функционала
Представим, что все в Чикаго полюбили нашего бота, поэтому мы расширяем функционал. Начнем с добавления новых видов событий.
Изменения в функции perform:
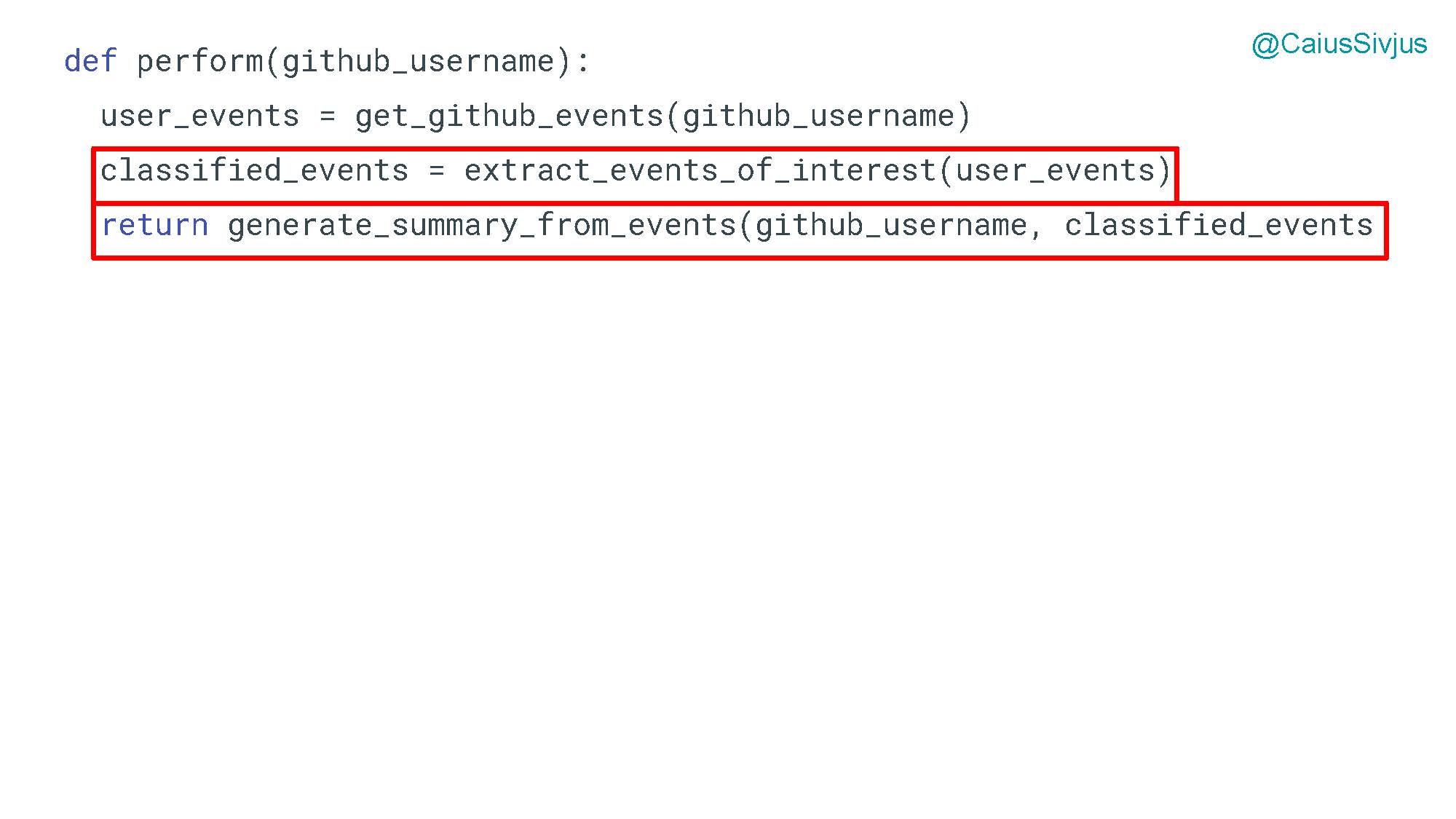
Изменения в функции extract_events_of_interest для извлечения событий из полученного словаря. Добавляем еще одно условное выражение:
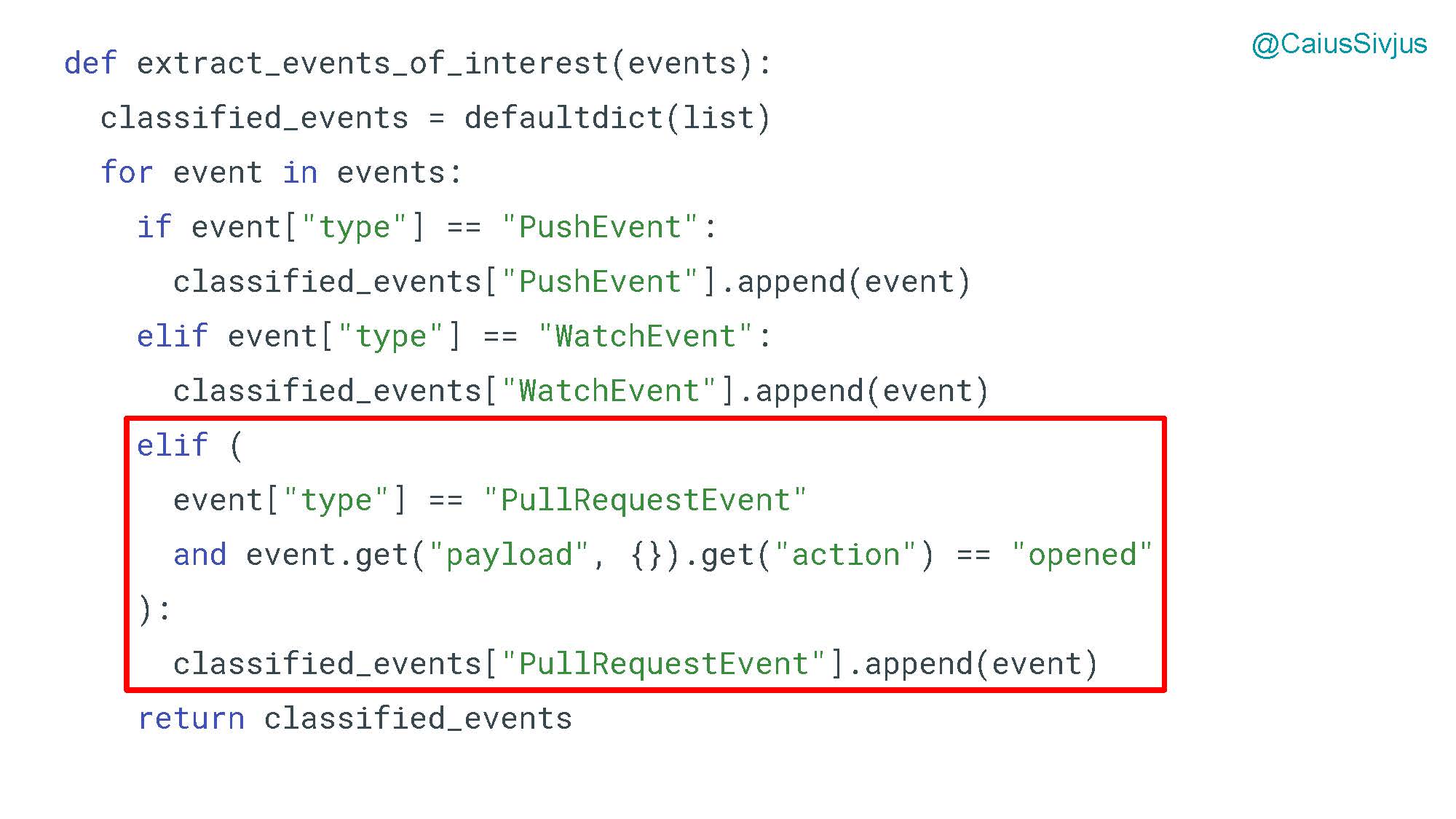
В функции generate_summary_from_events для создания текста резюме мы добавляем условное выражение с логикой для запросов на принятие изменений (pull requests). Эта функция уже начинает становиться сложнее:
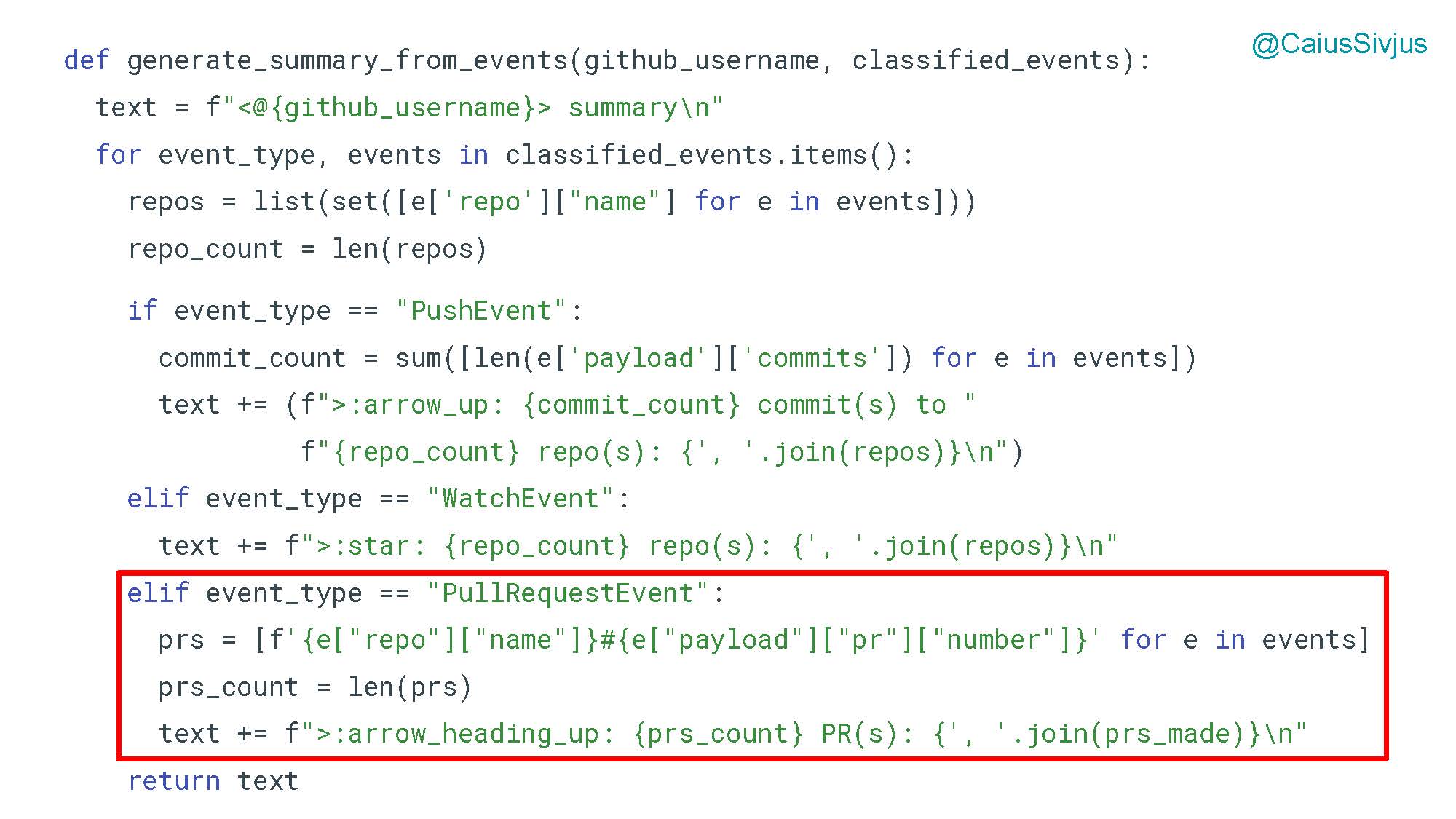
Это было легко. Наверное. Мы видим, как легко начать утрачивать контроль над кодом. При этом на данный момент мы отслеживаем всего три события.

А как же тесты? Давайте сравним тесты для первого варианта программы и тесты для расширенного варианта. Нам нужно написать тест для проверки функционала для запросов на принятие изменений в гитхабе, поэтому мы модифицируем уже написанные тесты:
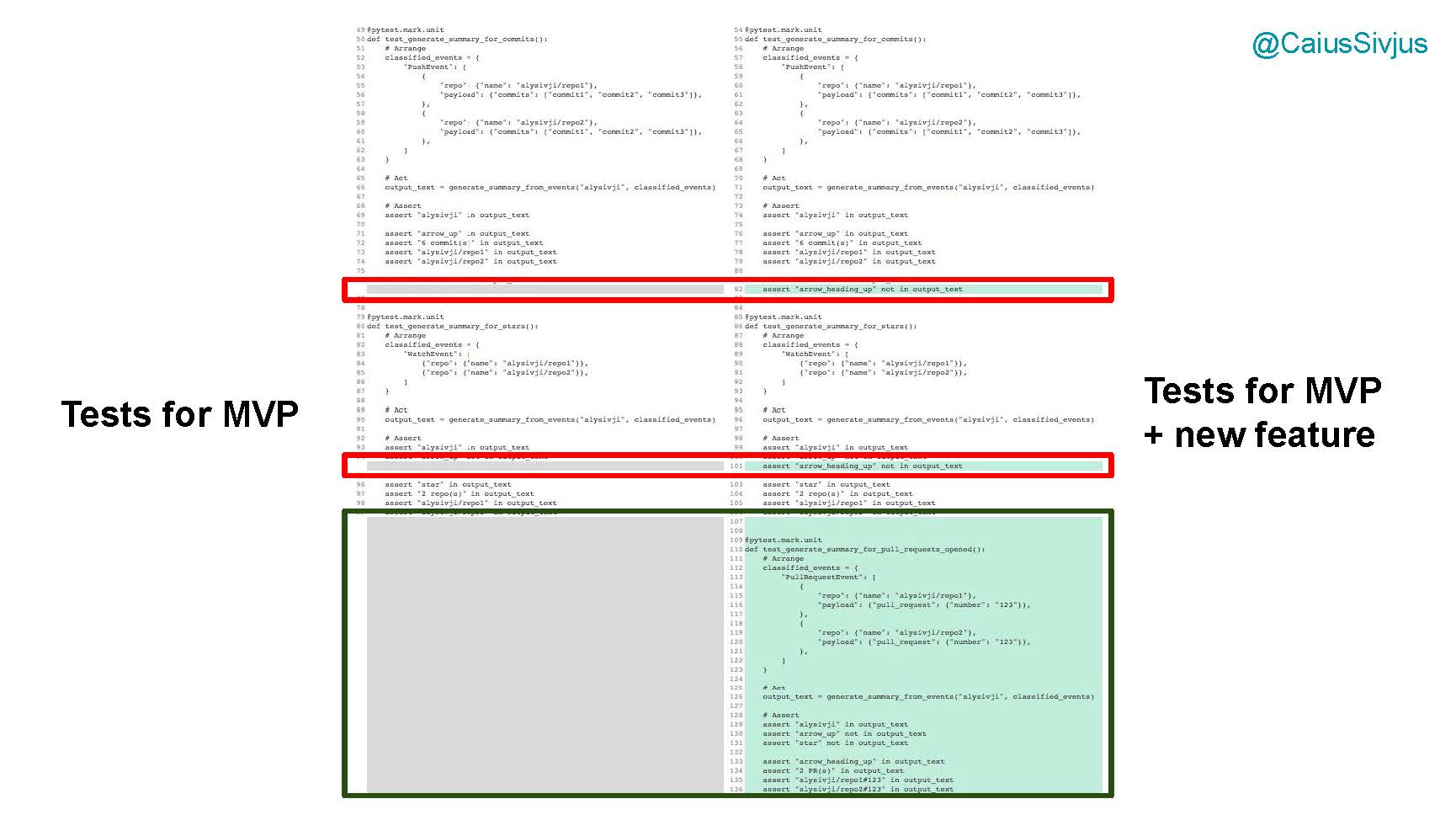
Функция выполняет много разных задач, генерируя резюме для разных видов событий. Поэтому при каждом добавлении нового функционала мы также увеличиваем код тестов. Для многозадачных функций также нужно усложнять тесты.
Абстракция более высокого порядка
Итак, если для добавления новых фич вам нужно модифицировать код во многих местах или менять готовые и работающие тесты, то у вас, возможно, не очень хороший код.
На самом деле, этот бот стал популярен, и пользователи хотели добавлять ему новые функции. Я вдруг обнаружил, что перегружаю дизайн программы, чтобы вместить весь этот функционал:

Примерно в то же время я начал книгу "Чистый код" (Clean Code) Роберта Мартина (Robert Martin). В ней много прекрасных советов по поводу того, как можно писать более качественный код. В ней рассматривается ряд хороших практик.
Среди прочего, книга рекомендует проводить рефакторинг кода с условными выражениями, используя полиморфные классы (polymorphic classes). Да, мне тоже не очень понятно.
Давайте немного отвлечемся и поговорим про объектно-ориентированное программирование (object-oriented programming) в Python. Это парадигма, построенная на объектах. Мы пытаемся моделировать вещи из окружающего мера в виде объектов. Когда мы структурируем свое решение, то в том числе создаем коллекцию взаимосвязанных объектов, которые контактируют друг с другом.
В объектно-ориентированном программировании (ООП) объекты объединяют в себе используемые определенным элементом данные и разрешенные для этого элемента действия.
В этой парадигме мы можем мыслить на более высоком уровне абстракции, создавая объекты с предопределенным содержанием (данные) и предопределенными умениями (поведение).
Это позволяет нам совершать действия с этими объектами для выполнения поставленной задачи. Такой подход отличается от последовательно-линейной системы.
Классы используются в ООП в качестве шаблона для создания объектов. Можно сказать, что мы инициализируем объекты из класса. В качестве аналогии представим себе формочку для печенья. Она — класс. Каждый экземпляр печенья, приготовленный с ее помощью, представляет собой объект.

Четыре главных принципа ООП:
- инкапсуляция, т.е. скрытие внутренней структуры (encapsulation),
- абстракция (abstraction),
- полиморфизм, т.е. способность объектов определять свое поведение в зависимости от вида получаемых данных (polymorphism),
- наследование (inheritance).
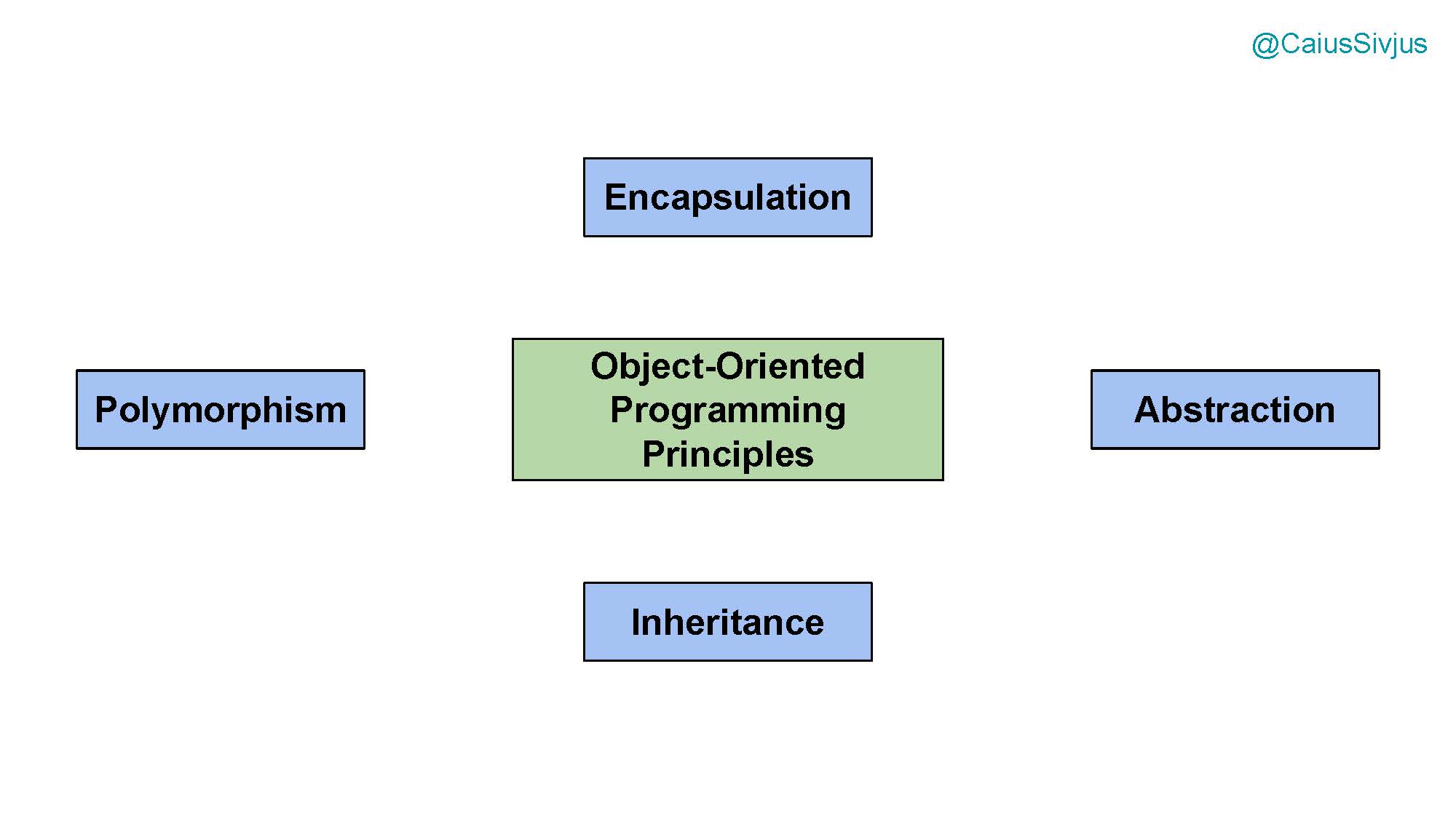
Инкапсуляция объединяет данные и поведение в один логический блок, который мы называем объектом. С ее помощью мы скрываем внутреннюю структуру объекта.
Абстракция позволяет нам скрывать внутреннюю реализацию конкретной программы в абстракции более высокого порядка. Также она помогает объектам контактировать друг с другом с помощью вызова открытых методов (public methods), скрывает сложность программы и изолирует сферу внесения изменений в код.
Последнее позволяет нам не трогать код для вызова объектов, когда необходимо изменить код для их создания. Задача кода для вызова объектов остается неизменной.
Наследование. Часто у нас есть объекты, которые почти похожи, но все-таки немного отличаются. С помощью наследования мы вносим общие данные и аналогичное поведение в базовый объект, а затем используем его для создания подчиненных объектов. Наследование позволяет избавиться от дублирования кода.
Подчиненные (дочерние) объекты могут перенимать данные и поведение базового объекта, а также замещать методы базового объекта своими, создавая свой собственный функционал, не похожий на реализацию родителя или других подчиненных объектов.
Полиморфизм создает одинаковый интерфейс для разных типов объектов. С помощью полиморфизма мы можем преобразовать блоки с условными выражениями в явно выраженные объекты.
Если посмотреть на нашу программу, в ней используется процедурная парадигма с условными выражениями. Она избирательно исполняет их в зависимости от ответа на вопрос, поставленный условным выражением. Если бы она была написана сквозь призму парадигмы ООП, то тип объекта сам бы определял поведение.
Я сделал диаграмму, подсмотренную в книге Мартина Фаулера (Martin Fowler) про рефакторинг кода. На ней видно, как можно преобразовать логику условных выражений в иерархию классов или объектов:
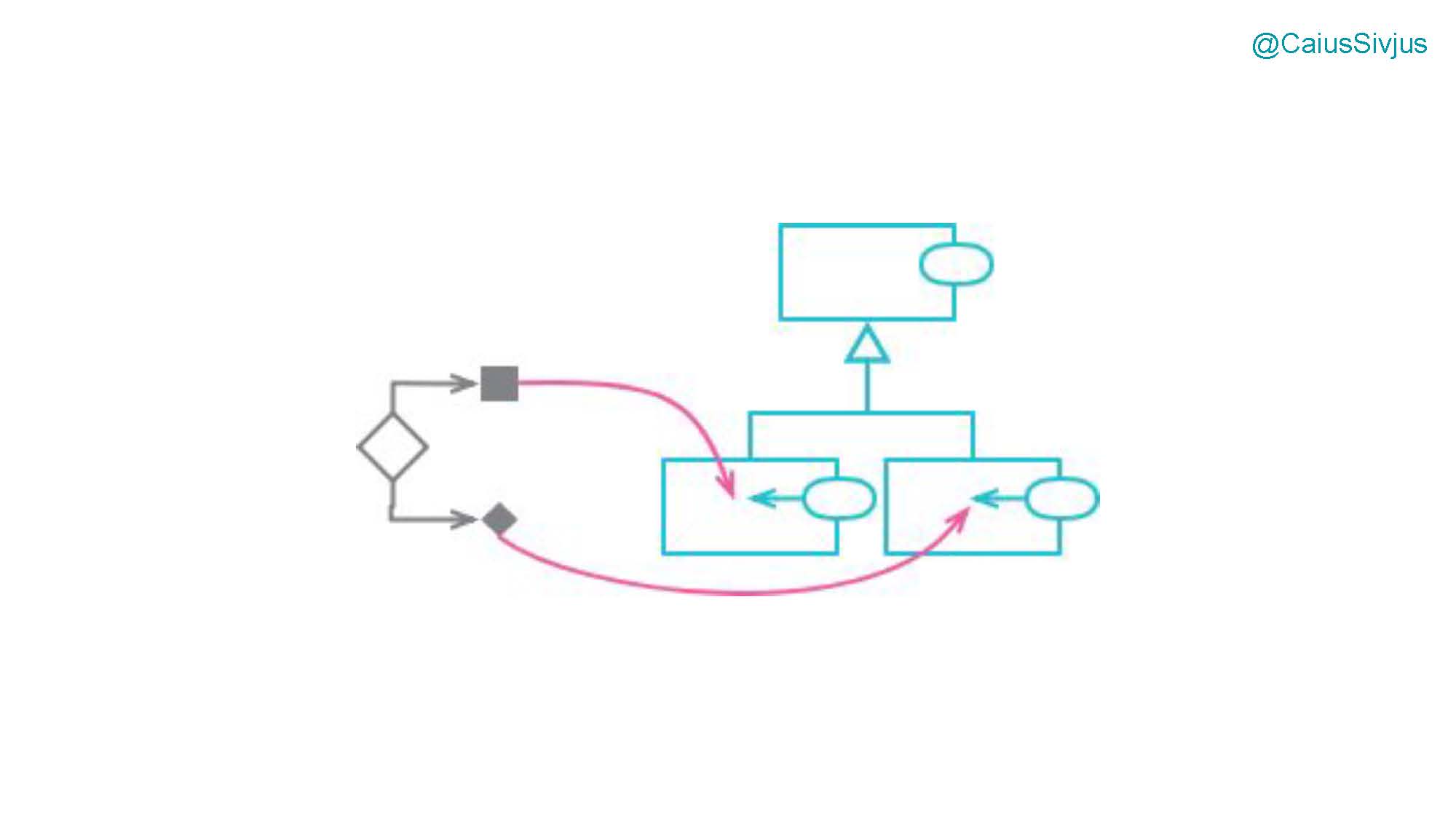
Рассмотрим полиморфизм подробнее на конкретном примере. Допустим у нас есть родительский класс (parent class) Animal:
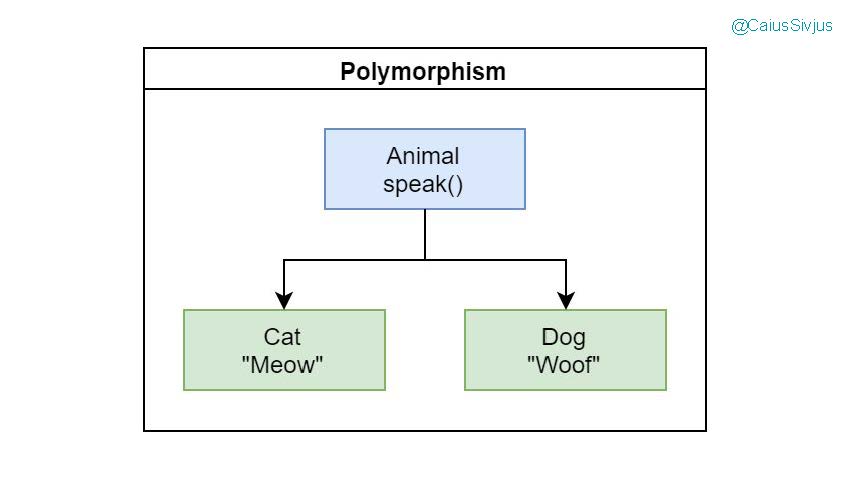
В нем реализован интерфейс для метода speak(). В разных дочерних объектах он инициирует разное поведение в зависимости от типа объекта. В базовом классе этот интерфейс на самом деле ничего не делает и в случае вызова выдает ошибку об отсутствии реализации (NotImplementedError):
class Animal:
def __init__(self, name):
self.name = name
def speak(self):
raise NotImplementedError
Когда мы создаем дочерний класс для кота и подать голос, то он исполняет свою реализацию, которая заменяет исходную версию метода speak() и говорит meow:
class Animal:
def __init__(self, name):
self.name = name
def speak(self):
raise NotImplementedError
class Cat(Animal):
def speak(self):
return "Meow!"
Собака же с помощью этого метода говорит woof:
class Animal:
def __init__(self, name):
self.name = name
def speak(self):
raise NotImplementedError
class Dog(Animal):
def speak(self):
return "Woof!"
Это и есть реализация той самой объектной взаимосвязи в Python. По этой системе мы можем создавать классы животных и дальше, и каждое из них будет говорить что-то свое, заменяя заимствованный в родительском классе метод speak() индивидуальной реализацией.
Теперь можно вернуться к нашему кейсу и приступить к замене условных выражений экземплярами полиморфизма. Когда мы создавали первый вариант единой логики, то занимались именно этим, желая приготовить что-то для своих пользователей.
Но сейчас у нас есть конкретная идея или проблема, которую надо решить, поэтому мы сосредоточимся на определенных деталях и создадим более качественное решение.
Давайте вернемся к нашему боту, которого мы недавно попытались разработать:

Сделаем шаг назад и посмотрим, что он пытается делать. У нас есть список всех событий пользователя, и мы объединяем их по виду события. Затем по каждому из них мы создаем некий текст резюме. Вполне подходит для создания типа "событие" (event). Возможно, список событий можно превратить в в базовый класс.

Пройдемся по этапам рефакторинга условных выражений с помощью двух полиморфных классов.
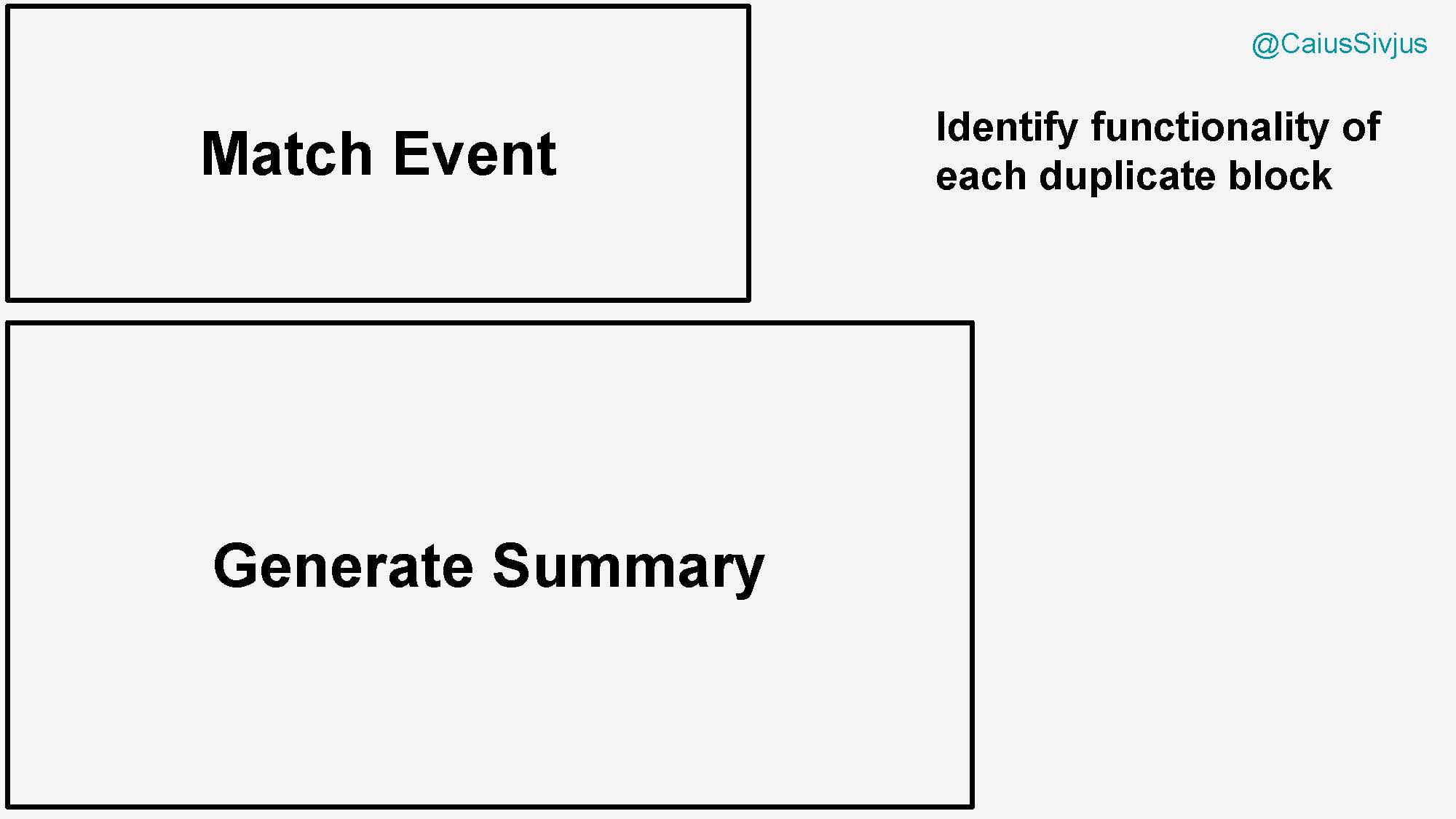
Сначала определим дублирующиеся блоки с оператором if. Затем мы разберемся, что делает каждый из них с точки зрения функционала.

Верхний блок пытается найти события, отвечающие условиям типа "событие":

Нижний блок пытается генерировать резюме для каждого из этих видов событий:
Теперь попробуем написать базовый класс EventList ("список событий"), включающий в себя определенные данные и действия. С точки зрения данных (data) мы хотим отслеживать все события, которые попадают в список. Что касается поведения (behavior), мы хотим получить возможность узнать размер списка и добавлять с конца (append) новые элементы.

Далее, у нас есть функция matches_event, которая возвращает True или False для события, которое отвечает или не отвечает условиям типа "событие". Еще есть функция generate_summary_text, которая генерирует текст резюме для определенного типа "событий":

Для этих функций в базовом классе, приведенном выше, предусмотрен базовый интерфейс, который выводит ошибку отсутствия реализации.
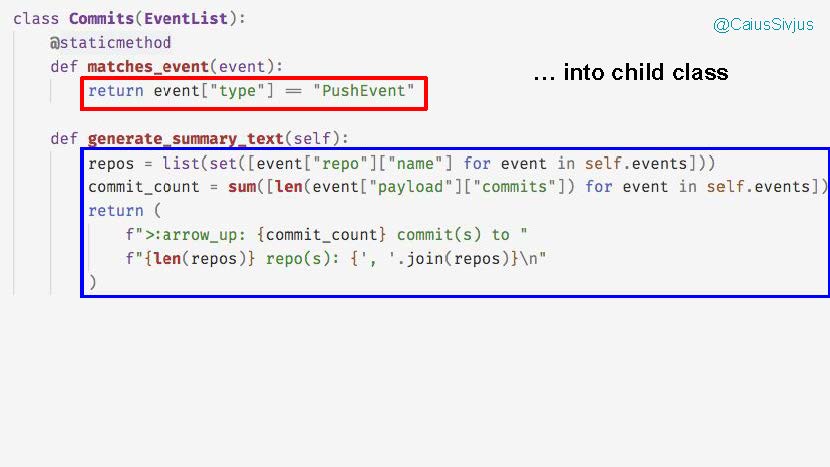
Теперь мы переходим к замене условных блоков дочерним классом Commits, который соотносится с этими двумя функциями для событий типа push в гитхабе.
Теперь посмотрим на функционал для извлечения событий по количеству звезд репозитория, который изначально был в функции extract_events_of_interest

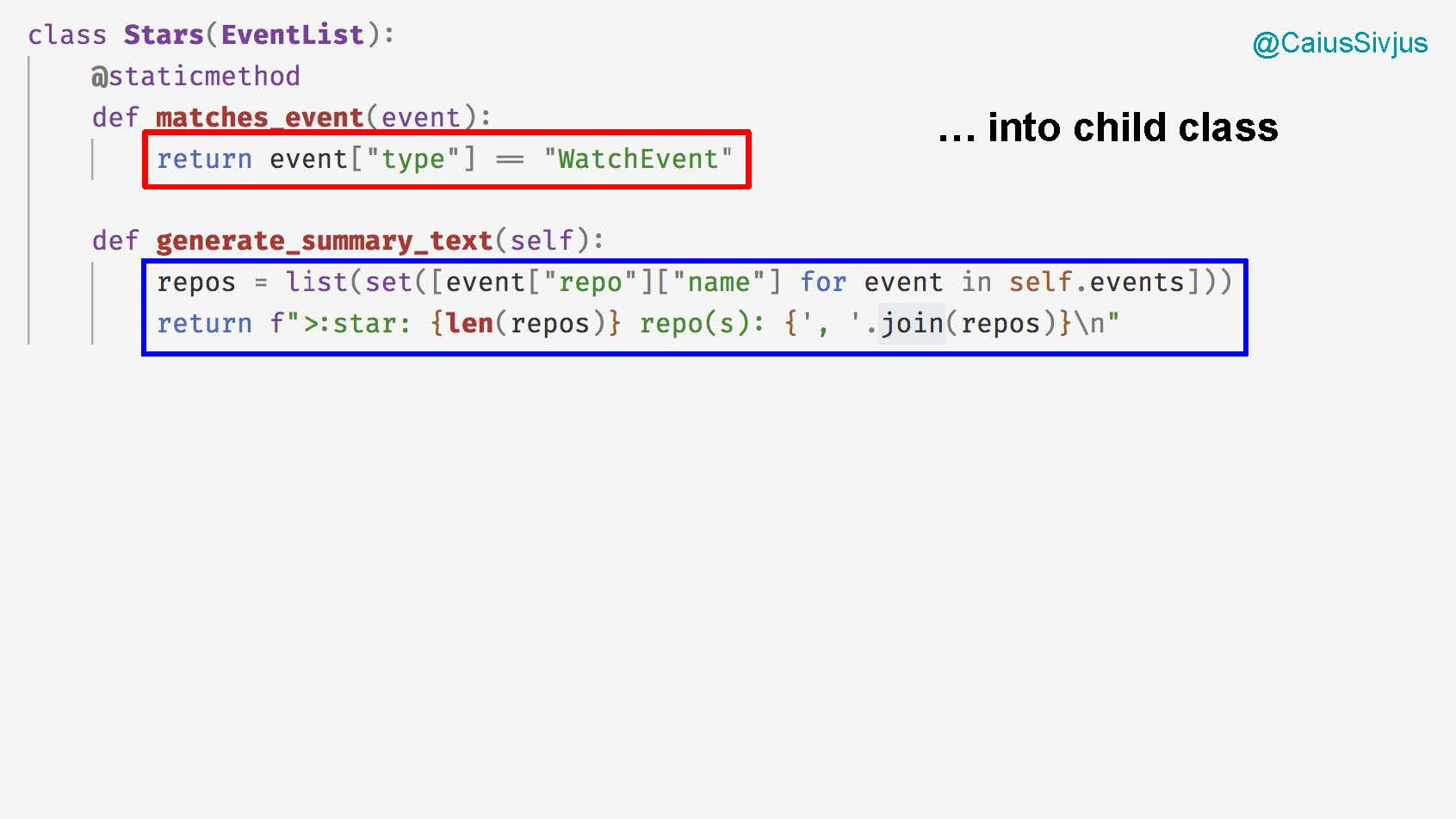
Для этого мы создаем класс Stars, который тоже станет дочерним классом для EventList со своими методами, которые возвращают события по типу и готовят для них текст резюме в зависимости от количества звезд:
Наконец, последний функционал был предусмотрен для событий типа "запрос на принятие изменений в гитхабе". Он был реализован в функции extract_events_of_interest и дополняющей ее функции generate_summary_from_events для написания текста к таким событиям:

Здесь мы тоже хотим создать дочерний класс под названием PullRequestsOpened с методом matches_event для поиска подходящих событий и методом generate_summary_text для подготовки текста:
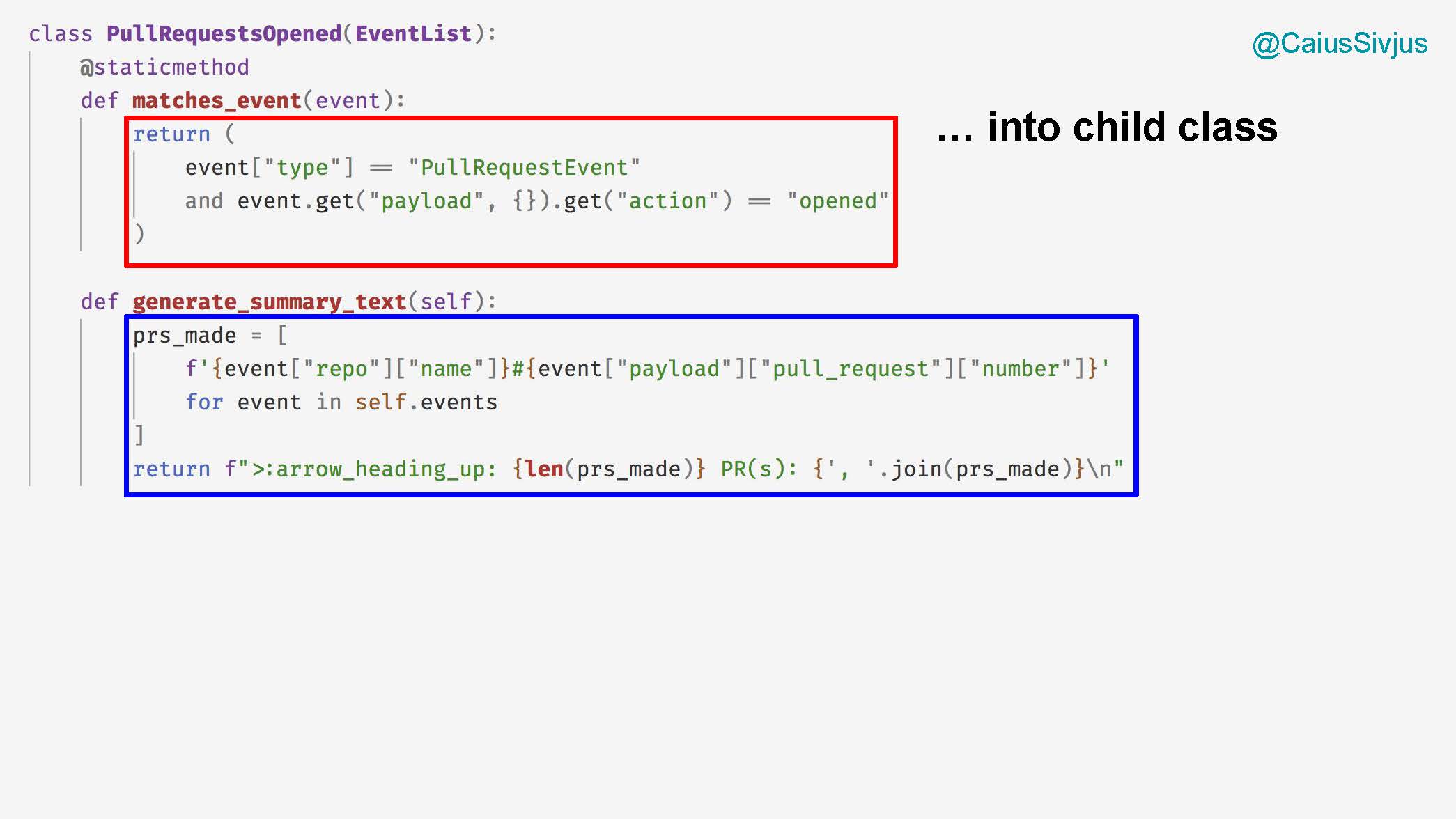
Еще я предлагаю создать специальный класс, который будет создавать общее резюме для конкретного пользователя. Для начала он принимает имя пользователя с гитхаба и список событий, а также классифицирует их по типам:

Далее мы увидим единственное место в новом коде, где используется два условных выражения. Сначала мы напишем метод classify_events для выделения нужных нам событий и их добавления в список. Если событие не отвечает условию, то мы пропускаем его и продолжаем как ни в чем ни бывало:
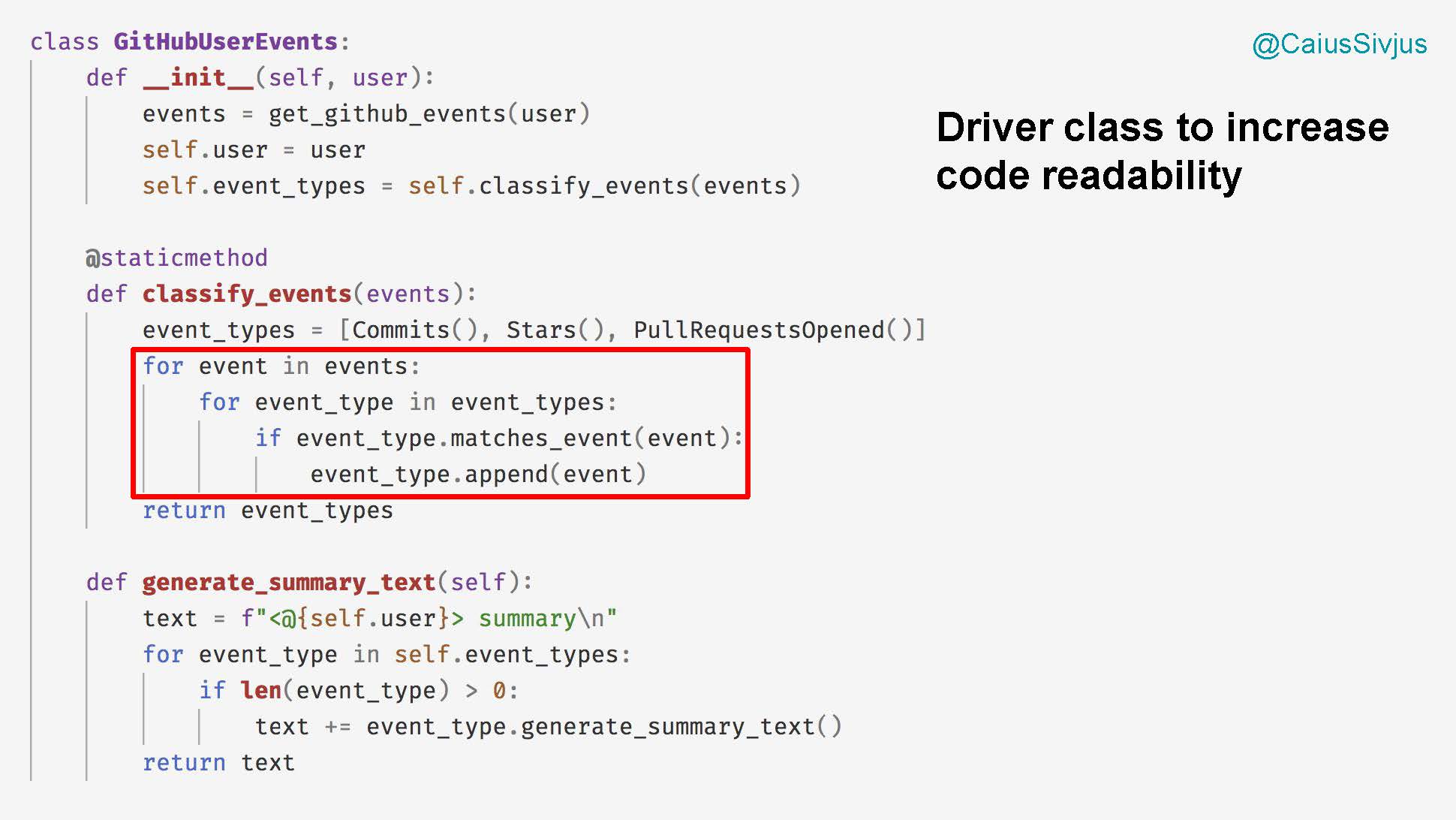
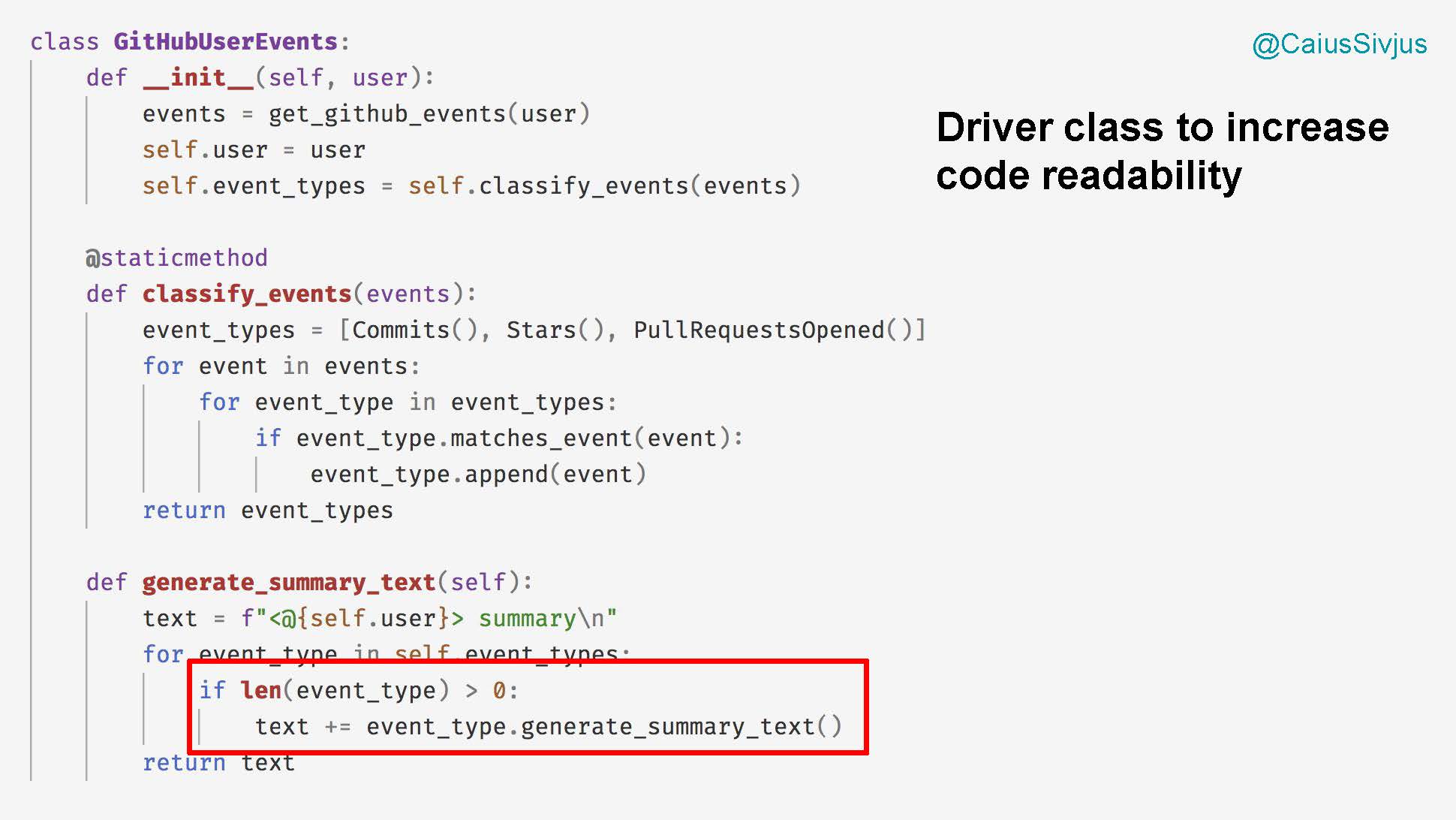
Второе условное выражение будет в методе generate_summary_text, которое исполняется, если у пользователя есть хотя бы одно событие:
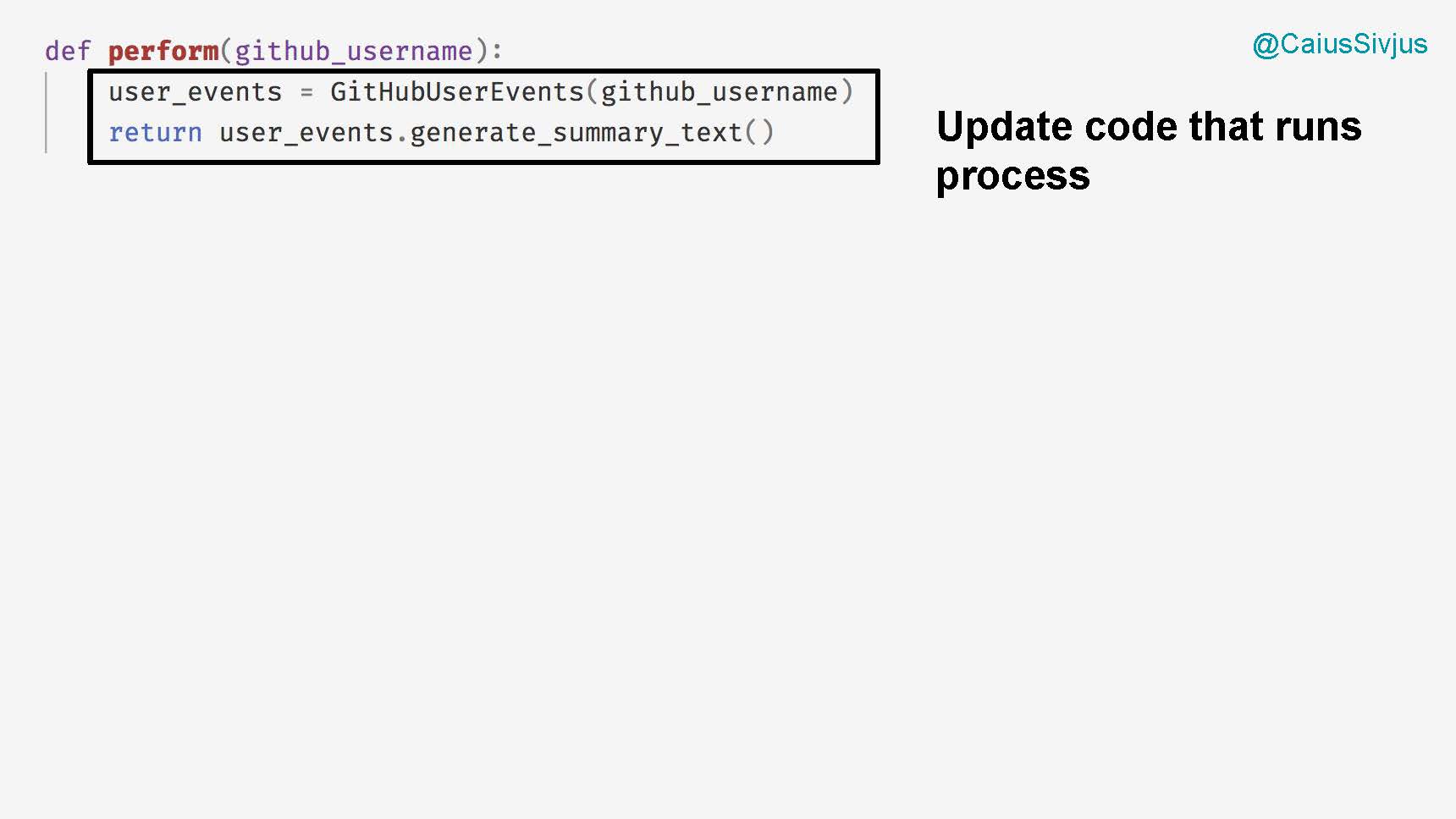
Мы завершим программу новой версией функции perform, которая отвечает за исполнение этой абстракции более высокого порядка:
Расширение функционала
Давайте поработаем с этой новой объектно-ориентированной схемой и посмотрим, насколько трудно окажется добавить новый тип в резюме событий гитхаба. Теперь мы будем отслеживать все события для пользователя и добавлять их в выходной результат.
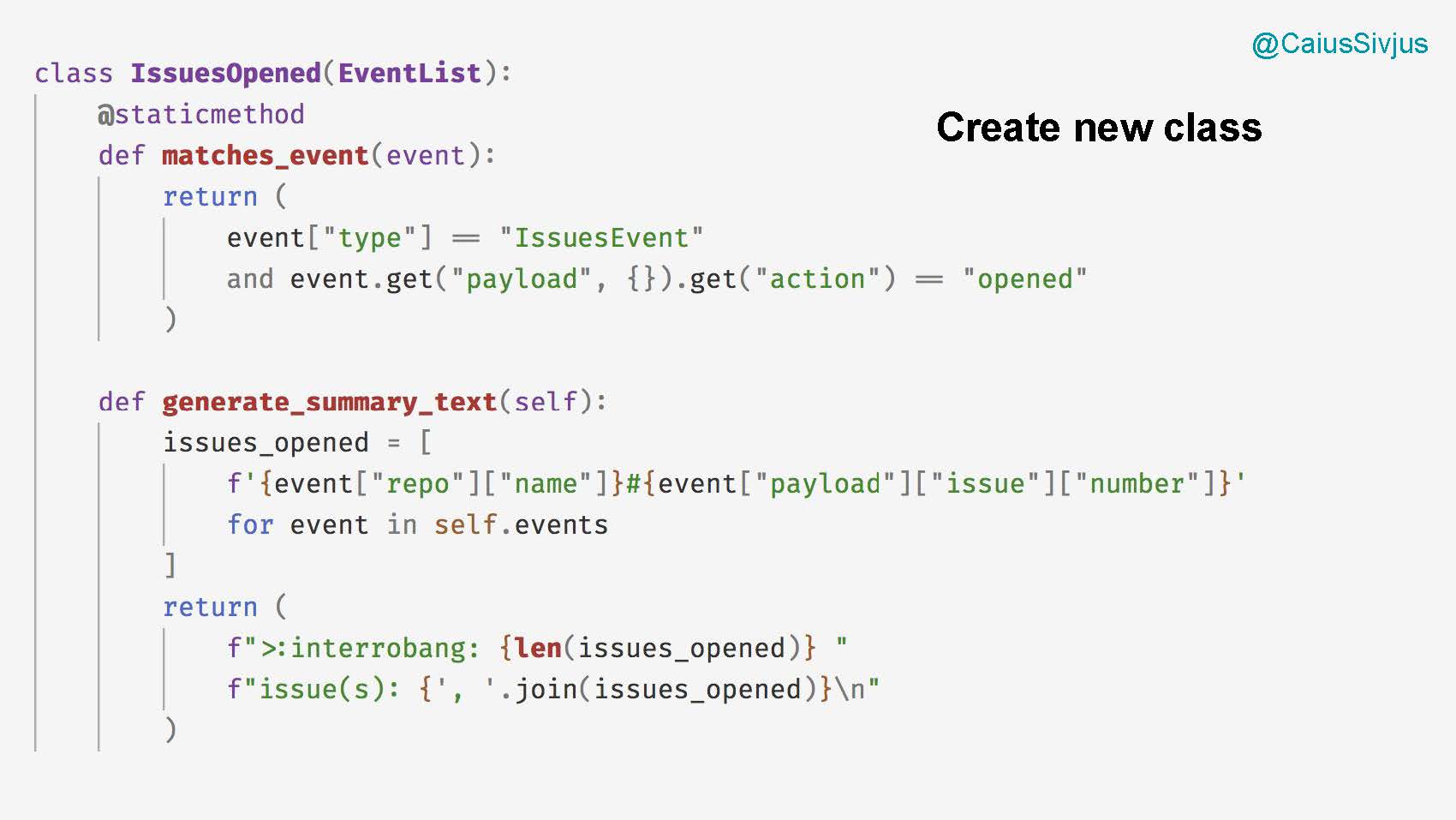
Создаем класс под названием IssuesOpened, он будет дочерним для класса EventList. В этом классе будет функция matches_event, выявляющая все события со статусом opened ("открыт"). Еще будет функция generate_summary_text для создания нужного нам текста:
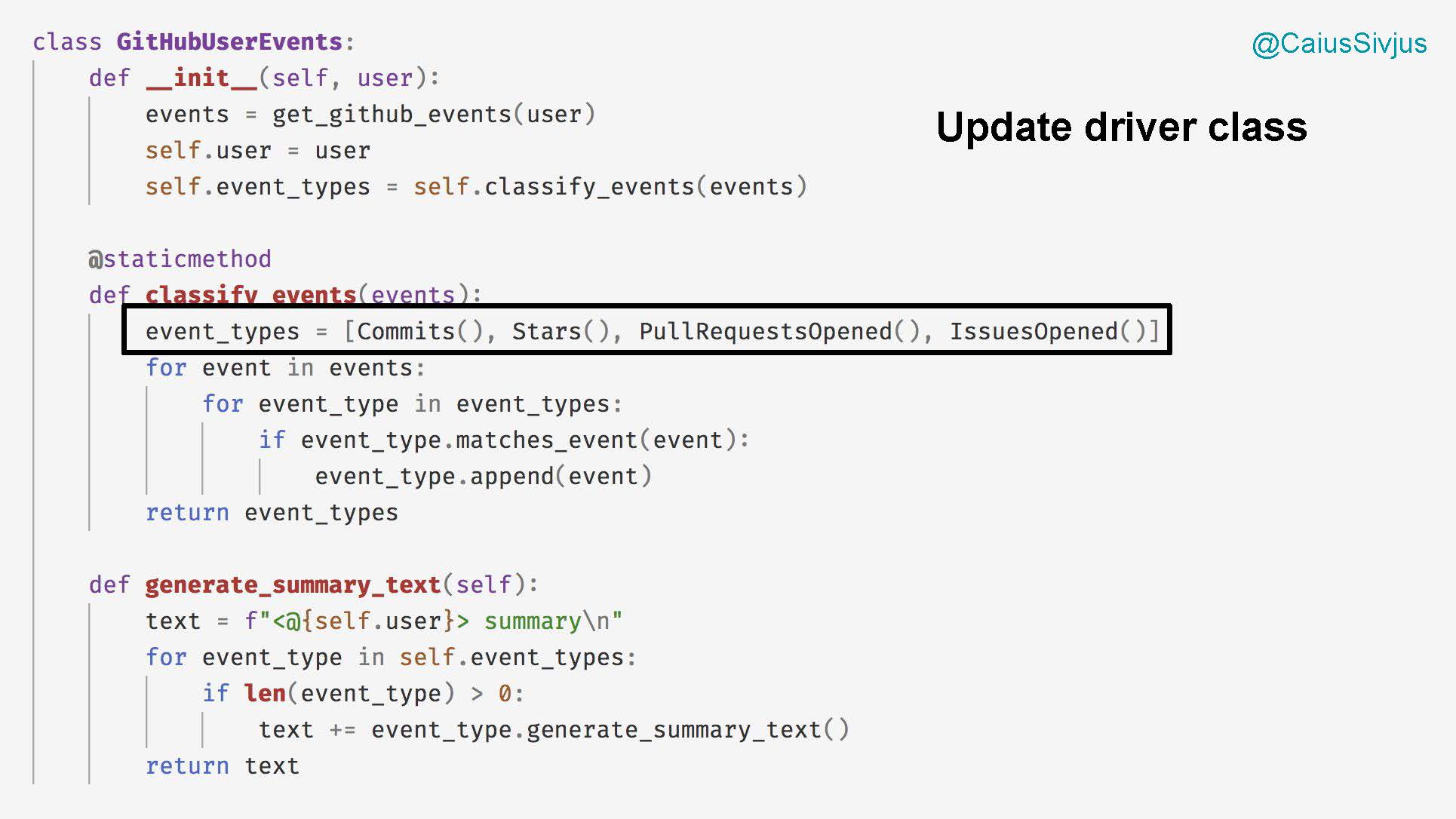
Теперь мы просто вернемся к объединяющему данные и действия классу GitHubUserEvents и обновим список событий:
С виду несложно.
Посмотрим на наши тесты и на то, как они будут отличаться по сравнению с первой реализацией:

Как видим, пришлось добавить новый тест, проверяющий новый функционал. Вспомним, что в предыдущей схеме нужно было модифицировать уже написанные тесты.
Так что, думаю, новая реализация немного лучше.
О чем следует помнить
Как всегда, в программировании необходимо учитывать несколько условий. Во-первых, мы немного усложнили схему программы, и каждому, кто к ней обращается, нужно иметь немного больше понимания в концепциях Python. Возможно, мы можем не захотеть такого усложнения за счет новой структуры.
Далее, можно прикинуть, насколько часто предполагается менять код. Если такие планы есть, то лучше уделить время рефакторингу кода, чтобы вывести его на более высокий уровень абстракции. В этом смысле мне нравится следовать правилу трех этапов, тоже взятому из книги Мартина Фаулера "Refactoring":
1. Когда вы делаете что-то в первый раз, то на самом деле просто учитесь решать проблему и выполнять задачу.
2. Во второй раз вы вздрагиваете и уже понимаете эту боль. Вы все еще учитесь, просто повторяйте и дублируйте свой код, на данном этапе это не проблема.
3. В третий раз вы беретесь за дело и снова ощущаете эту боль. Но на этот раз понимаете, что, возможно, есть смысл уделить время созданию более качественной абстракции.
Вспомним дзен Python:

Что касается наследования (inheritance), стараемся не создавать слишком глубокие уровни. Это усложняет код и лишает его гибкости. К тому же, вместо необходимости разобраться в нескольких уровнях условных выражений, нам придется разбираться в уровнях наследования классов. Получится, что один комплект проблем просто заменен на другой.
Есть такое мнение, что при написании объектно-ориентированного кода следует предпочитать не наследование, а композицию. Хотя, думаю, что наследование — полезный инструмент, если не создавать слишком глубокую иерархию.
Но выбирать неверное направление абстракции тоже неправильно. Лучше уж копировать и вставлять дублирующийся код. На эту тему есть отличное выступление Санди Метца (Sandi Metz) с конференции по Ruby.
Тесты. Не забываем про тесты. У меня получилось создать эту программу именно благодаря тестам, которые гарантировали, что все работает в соответствии с ожиданиями.
Заключение
Давайте кратко повторим изученный материал. Мы можем использовать выражения с оператором if для решения любых задач. Однако если их становится слишком много, то код станет трудно читать и еще труднее обновить.
Мы рассмотрели процесс рефакторинга дублирующихся условных выражений в полиморфные классы, состоящий из пяти этапов:
1. Определить дублирующиеся условные блоки.
2. Определить функционал каждого блока кода.
3. Создать базовый класс для моделирования.
4. Вывести функционал условных блоков в дочерние классы.
5. Обновить код для реализации процесса.
Мы помним, что нужно определиться с наличием реальной необходимости в рефакторинге.
Дополнительные материалы
Ссылки
Книги
Видео
Материал для выступления