Глава 1 Моделирование предметной области бизнеса работодателя в Python
Содержание
- Введение
- Почему бы просто не загрузить все в электронную таблицу?
- Инварианты, ограничения и согласованность
- Инварианты, Параллелизм и блокировки
- Что такое Совокупность (Агрегация, Aggregate)?
- Выбирая Совокупность
- Одна совокупность = один репозиторий
- Что насчет производительности?
- Оптимистичный параллелизм с номерами версий
- Варианты реализации для номеров версий
- Тестируем наши правила о целостности данных
- Принудительное исполнение правил для параллелизма с помощью уровней локализации транзакций в базе данных
- Пример пессимистичного контроля параллелизма:
SELECT FOR UPDATE - Резюме
- Часть I: краткое повторение
В данной главе мы хотим вернуться к нашей модели предметной области (domain model), чтобы обсудить неизменные величины (инварианты, invariants) и ограничения (constraints), а также чтобы посмотреть, каким образом объекты нашей модели могут сохранять свою собственную внутреннюю согласованность, как концептуально, так и в постоянной памяти. Мы обсудим концепцию контура согласованности и покажем, каким образом явное обозначение этого контура поможет нам построить очень эффективное программное обеспечение без ущерба для удобства обслуживания.
Добавление совокупности продукта Product позволит предварительно наметить нашу цель: мы введем новый объект модели под названием Product, в который войдет несколько партий (batches), а старый сервис предметной области allocate() станет доступен как метод в Product
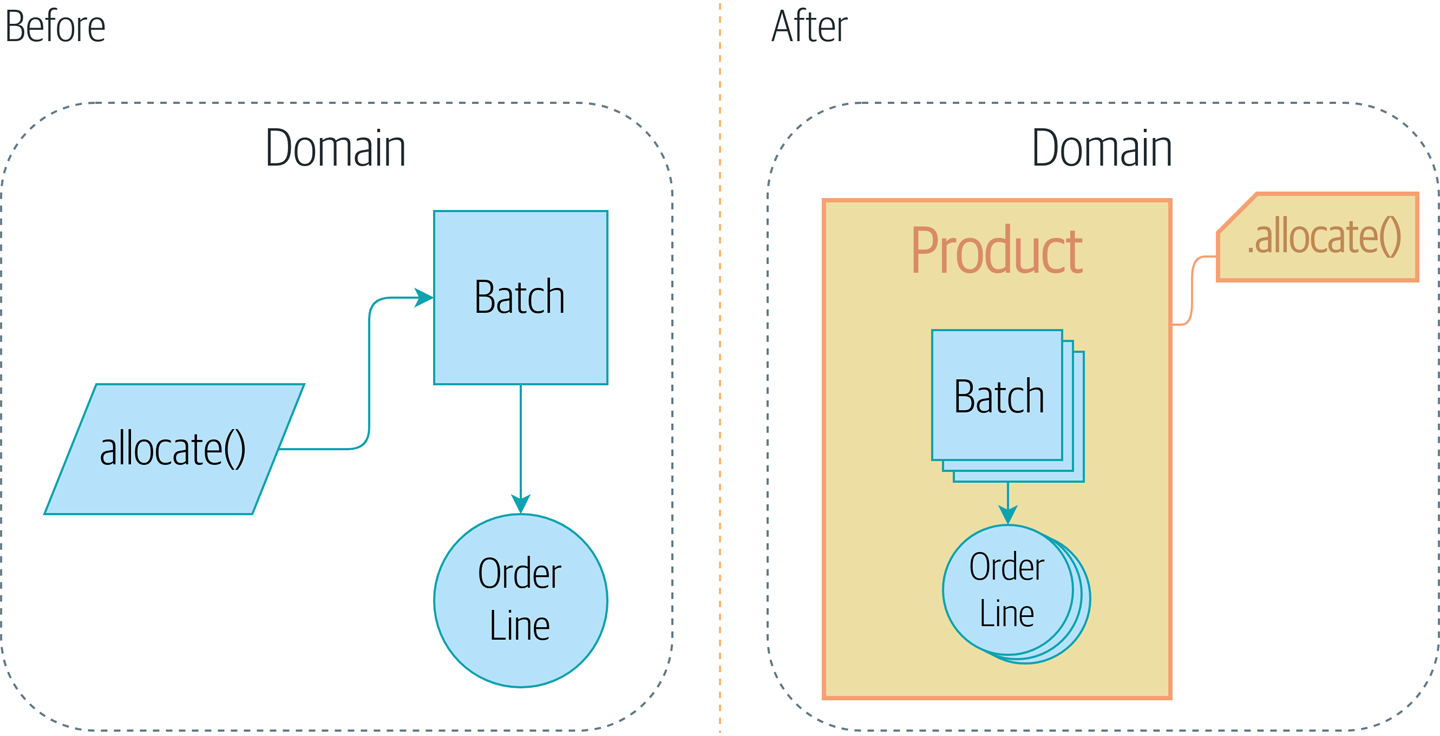
Рисунок 1. Добавление совокупности Product
Зачем? Давайте посмотрим.
Код из этой главы можно найти на ветви (branch) гитхаба <code>chapter_07_aggregate</code>:
git clone https://github.com/cosmicpython/code.git
cd code
git checkout chapter_07_aggregate
# или, чтобы писать код самостоятельно, выполните чекаут на предыдущей главе:
git checkout chapter_06_uowПочему бы просто не загрузить все в электронную таблицу?
И вообще, в чем смысл моделирования предметной области (domain model)? Какую фундаментальную проблему мы пытаемся решить?
Может, просто загрузим все в электронную таблицу? Многие из наших пользователей были бы в восторге. Пользователи из бизнеса любят электронные таблицы благодаря их простоте, изученности и невероятной эффективности.
На самом деле, огромное количество бизнес-процессов выполняется ручной пересылкой электронных таблиц туда-сюда по электронной почте. Данная архитектура "CSV по SMTP" характеризуется низким уровнем сложности на старте, но масштабируется она не очень хорошо, потому что трудно использовать логику и поддерживать целостность.
Кому можно просматривать данное конкретное поле? Кому можно его обновлять? Что случится, если мы попробуем заказать −350 стульев или 10 000 000 столов? Возможна ли отрицательная зарплата для работника?
Вот такие у системы ограничения. Значительная часть написанной нами логики предметной области существует для принудительного поддержания этих ограничений в целях дальнейшего существования системных инвариантов. Инварианты — это такие вещи, которые должны присутствовать при каждом завершении операции.
Инварианты, ограничения и согласованность
Эти два слова в какой-то степени взаимозаменяемые, хотя ограничением является правило, ограничивающее количество возможных состояний, в которые может перейти наша модель, а инвариант можно более точно обозначить как условие, которое всегда будет верным.
Если бы мы писали систему бронирования для отеля, у нас было бы ограничение, не допускающее дублирования броней. Таким образом будет поддерживаться инвариант о запрете бронирования одного номера более одного раза на один и тот же день.
Разумеется, иногда нам может понадобиться временно отойти от правил. Возможно, нам понадобится перетасовать номера в связи с VIP-бронированием. Пока мы перемещаем брони по памяти у нас могут быть двойные брони, но наша модель предметной области должна обеспечить, чтобы, когда мы закончим, у нас было итоговое единое состояние, в котором соблюдаются инварианты. Если мы не можем найти способ разместить всех своих гостей, мы должны вызвать ошибку и отказаться завершить операцию.
Давайте посмотрим на пару конкретных примеров, взятых из наших бизнес-требований. Начнем с этого:
Строка заказа может распределяться только на одну партию за раз.
— Бизнес
Это правило бизнеса, которое вводит инвариант. Инвариант заключается в том, что строка заказа распределяется на партии в количестве ноль или один, но никогда не в количестве более одного. Мы должны убедиться в том, что наш код никогда не будет случайно вызывать Batch.allocate() по двум разным партиям для одной и той же строки, а на данный момент ничто не создаёт перед нами явного препятствия, мешающего это сделать.
Инварианты, Параллелизм и блокировки
Давайте посмотрим ещё на одно правило нашего бизнеса:
Мы не можем распределять на партию, если доступное количество меньше, чем количество по строке заказа.
— Бизнес
Здесь ограничение заключается в том, что мы не можем распределять на партию больше запасов, чем имеется в наличии, чтобы наши продажи никогда не превышали запасы в результате распределения на двух заказчиков, например, одной и той же физической подушки. Каждый раз, когда мы обновляем состояние системы, наш код должен обеспечивать, чтобы мы не нарушали инвариант о том, что доступное количество должно быть больше нуля или равно ему.
В однопоточном приложении для одного пользователя нам сравнительно легко поддерживать данный инвариант. Мы просто распределяем запасы по одной строке за раз, и вызываем ошибку, если запасов в наличии нет.
Когда мы вводим идею параллелизма, все становится гораздо сложнее. Неожиданно может оказаться, что мы распределяем запасы для нескольких строк заказа одновременно. Возможно мы даже будем распределять строки заказа одновременно с обработкой изменений в самих партиях.
Обычно мы решаем данную проблему с помощью блокировок таблиц базы данных. Таким образом не допускается одновременное выполнение двух операций по одному ряду или по одной таблице.
Когда мы начнём думать о масштабировании своего приложения, мы поймём, что наша модель распределения строк против доступных партий не может масштабироваться. Если мы каждый час обрабатываем десятки тысяч заказов и сотни тысяч строк заказов, мы не сможем держать блокировку на всей таблице партий для каждого из них, так как получим взаимные блокировки (deadlocks) или, как минимум, проблемы с производительностью.
Что такое Совокупность (Агрегация, Aggregate)?
Хорошо. Если мы не можем блокировать всю базу данных каждый раз, когда захотим распределить строку заказа, что нам делать вместо этого? Мы хотим защитить инварианты нашей системы, но при этом позволить больше параллелизма. Поддержание наших инвариантов неизбежно означает недопущение параллельных записей. Если несколько пользователей смогут одновременно распределять товар DEADLY-SPOON, мы рискуем столкнуться с избыточным распределением.
С другой стороны, нет никаких причин, которые не позволяли бы нам распределять DEADLY-SPOON одновременно с FLIMSY-DESK. Нет никакого риска при одновременном распределении двух видов товара, ведь нет никаких инвариантов, охватывающих их обоих. Нам не нужно обеспечивать для них последовательность между собой.
Совокупность (Агрегация, Aggregate) — шаблон проектирования, созданный сообществом DDD (Domain-Driven Design) и помогающий нам снять данную точку напряжения. Совокупность — это просто объект предметной области (domain object), который содержит в себе другие объекты предметной области и позволяет нам воспринимать всю коллекцию как одну единицу.
Включённые в совокупность объекты можно менять только путём её полной загрузки и вызова методов по самой совокупности.
По мере того как модель будет усложняться и выращивать больше объектов вида Объект-сущность (Entity) и Объект-значение (Value), которые будут ссылаться друг на друга на переплетённой диаграмме, возможно, будет трудно следить за тем, кому что можно менять. Особенно если в нашей модели есть коллекции, а они есть (наши партии представляют собой коллекции), хорошей идеей будет назначить некоторые сущности единой точкой входа для изменения связанных с ними объектов. Благодаря этому система становится концептуально проще, и с ней проще работать, когда мы возлагаем на некоторые объекты ответственность за согласованность остальных.
Например, если мы строим сайт магазина, хорошей совокупностью может стать Корзина: она представляет собой коллекцию позиций, которую можно считать единым элементом. Важно отметить то, что мы хотим загрузить всю корзину из нашего хранилища данных как один блоб, иначе мы столкнёмся с риском странных ошибок параллелизма. Вместо этого мы хотим, чтобы каждое изменение в корзине происходило в рамках одной транзакции базы данных.
Мы не хотим изменять несколько корзин в рамках одной транзакции, потому что нет такого сценария использования, при котором происходит изменение корзин нескольких заказчиков одновременно. Каждая корзина представляет собой один контур согласованности (consistency boundary), ответственный за поддержание своих собственных инвариантов.
СОВОКУПНОСТЬ — это кластер связанных объектов, которых мы считаем одним элементом в целях изменения данных.
— Эрик Эванс
Синяя книга предметно-ориентированного проектирования
Если следовать словам Эванса, у нашей совокупности есть базовая сущность (Корзина), которая оформляет доступ к позициям. Каждая позиция обладает своей собственной идентичностью, однако другие части системы всегда будут обращаться только к Корзине как к неразделимому целому.
Аналогично тому, как мы используем начальные подчёркивания _leading_underscores для обозначения "внутренних" методов или функций, мы можем считать совокупности "публичными" классами нашей модели, а остальные Объекты-сущности и Объекты-значения — "внутренними".
Выбирая Совокупность
Какую совокупность нам следует использовать в своей системе? В какой-то степени выбор будет произвольным, но он важен. Совокупность будет той границей, на которой мы убеждаемся, что каждая операция завершается на фоне общей согласованности. Это помогает нам лучше понимать свое программное обеспечение и предотвращать странные состязания. Мы хотим очертить границу вокруг небольшого количества объектов (чем меньше, тем лучше для производительности), которые будут обязаны согласовываться друг с другом, и нам нужно назначить этой границе хорошее имя.
Объектом, которым мы манипулируем под поверхностью, является Batch (партия). Как мы назовем коллекцию партий? Как мы разделим все находящиеся в системе партии на отдельные острова согласованности?
В качестве контура мы можем использовать Shipment (поставку). Каждая поставка включает в себя несколько партий, и все они транспортируются на наш склад одновременно. С другой стороны, мы можем воспользоваться Warehouse (складом) как контуром: каждый склад включает в себя много партий, и одновременный подсчет всех запасов может иметь смысл.
Однако ни одна из этих концепций не подходит нам в полной мере. Мы должны иметь возможность распределять товары DEADLY-SPOON и FLIMSY-DESK одновременно, даже если они находятся на одном складе или в одной поставке. В этих концепциях не тот уровень модульности.
Когда мы распределяем строку заказа, нас интересуют только те партии, в которых учетный складской номер (SKU) совпадает со строкой заказа. Концепция наподобие GlobalSkuStock сработала бы: коллекция всех партий для определенного SKU.
Но это имя слишком громоздкое, поэтому после недолгих дискуссий по поводу SkuStock, Stock, ProductStock и т.д. мы решили назвать ее просто Product. В конце концов, именно к этой концепции мы пришли в первую очередь во время своего исследования языка предметной области еще в главе 1.
Поэтому план такой: когда мы хотим распределить строку заказа, вместе прошлого процесса: распределить по всем партиям с помощью сервиса предметной области, при этом мы просматриваем все объекты Batch по всему миру и передаем их сервису предметной области allocate()...
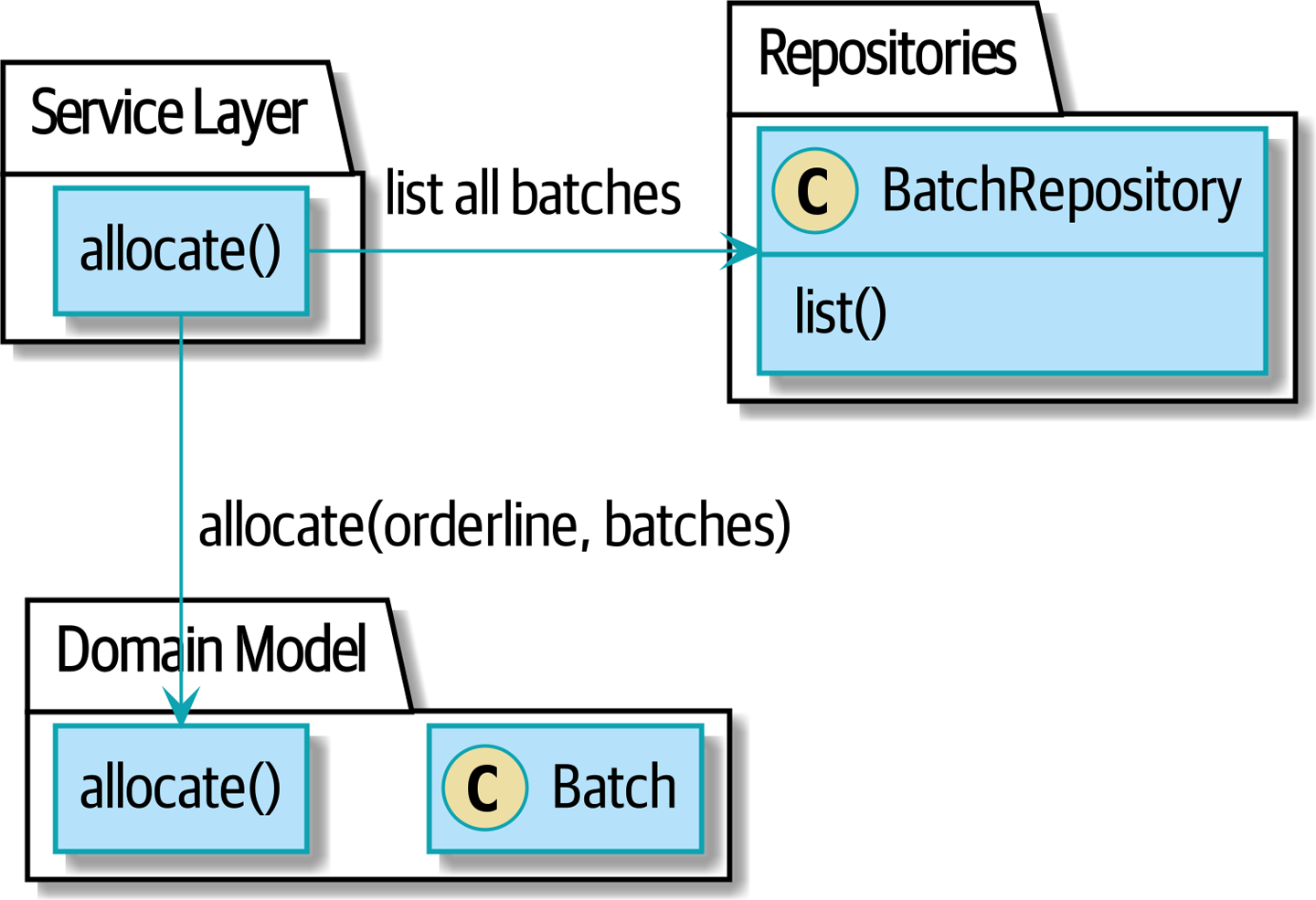
Рисунок 2. Прошлое: распределяем по всем партиям с помощью сервиса предметной области
... мы перейдем к будущему миру: просим Product распределить по своим партиям, в которых есть новый объект Product для конкретного SKU по строке нашего заказа, и тогда он будет отвечать за все партии того SKU, и мы сможем применить к нему метод .allocate().
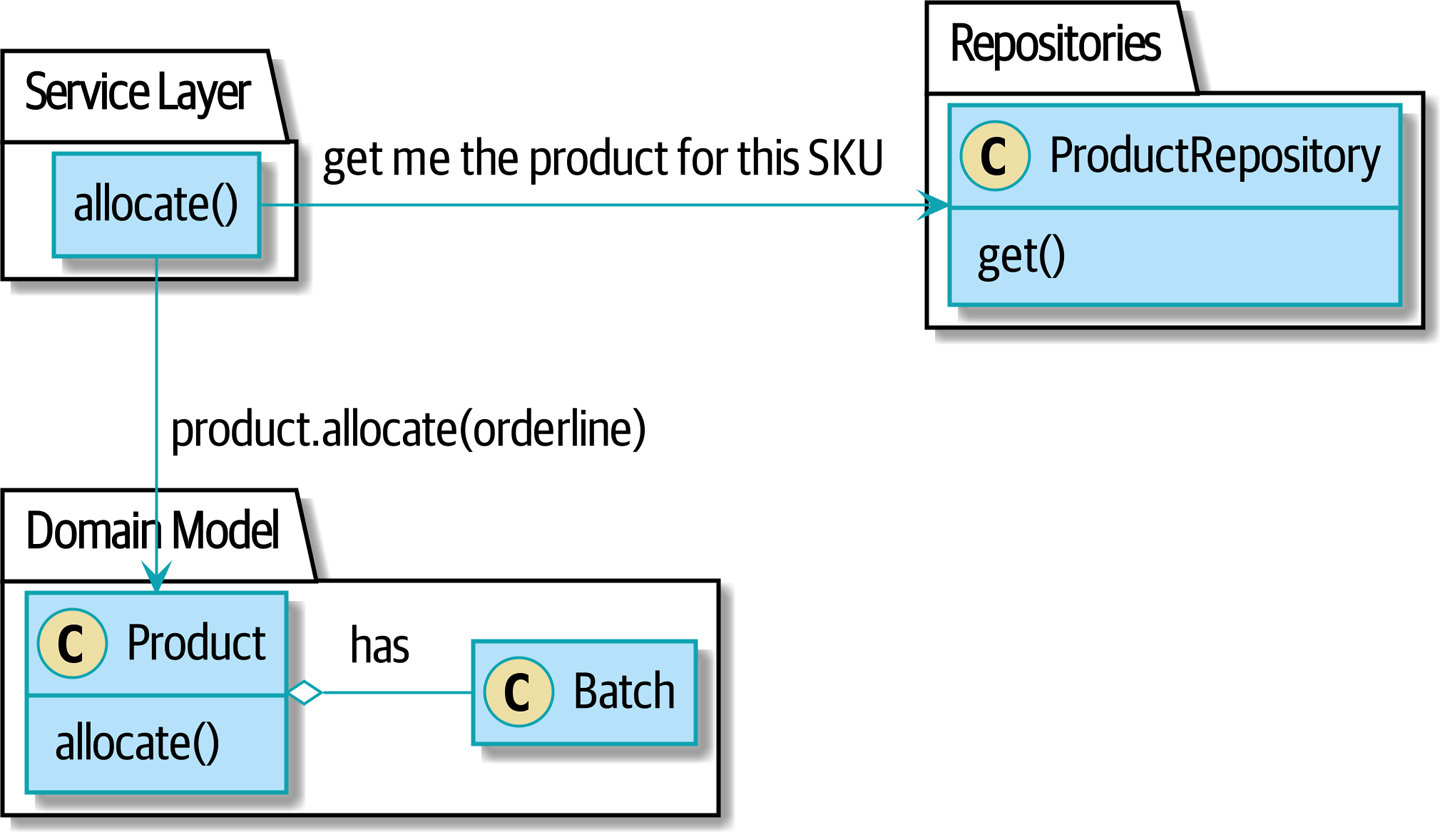
Рисунок 3. Будущее: просим Product распределить по своим партиям
Давайте посмотрим, как это выглядит в коде:
# Избранная нами совокупность, Product (src/allocation/domain/model.py)
class Product:
def __init__(self, sku: str, batches: List[Batch]):
self.sku = sku #(1)
self.batches = batches #(2)
def allocate(self, line: OrderLine) -> str: #(3)
try:
batch = next(
b for b in sorted(self.batches) if b.can_allocate(line)
)
batch.allocate(line)
return batch.reference
except StopIteration:
raise OutOfStock(f'Out of stock for sku {line.sku}')
1. Для Product главным идентификатором является sku.
2. Наш класс Product содержит в себе ссылку на коллекцию партий для этого SKU.
3. Наконец, мы можем превратить службу предметной области allocate() в метод для совокупности Product.
Примечание
Данный Product по своему виду, возможно, не будет соответствовать вашим ожиданиям от модели Product. Без цены, описания и габаритов. Наша служба распределения не интересуется этими вещами. В этом сила ограниченных контекстов; концепция продукта в одном приложении может сильно отличаться от другого. Более подробно этот вопрос рассматривается в следующей врезке.
Совокупности, Ограниченные контексты и микросервисы
Концепция ограниченных контекстов (bounded contexts) стала одним из самых важных нововведений Эванса и сообщества DDD.
По сути, это была реакция против попыток охватить весь бизнес одной моделью. Слово "заказчик" (customer) имеет разные значения для людей из продаж, обслуживания заказчиков, логистики, техподдержки и т.д. Атрибуты, необходимые в одном контексте, нерелевантны в другом. Еще хуже то, что концепции с одним и тем же именем могут иметь совершенно разные значения в разных контекстах. Поэтому, вместо попыток построить одну модель (или класс, или базу данных) для охвата всех возможных сценариев использования, лучше иметь несколько моделей, обозначить границы вокруг контура каждого контекста, а также уделить время организации прямого перевода между разными контекстами.
Данная концепция очень хорошо переводится в мир микросервисов, где каждый микросервис волен обладать своей собственной концепцией "заказчика" и своими правилами для организации ее перевода и получения между собой и другим микросервисом, с которым он интегрирован.
В нашем примере в сервисе распределения есть Product(sku, batches), а в "ecommerce" есть Product(sku, description, price, image_url, dimensions и т.д. ...). На практике должно быть так, чтобы наши модели предметной области включали в себя только те данные, которые нужны им для выполнения расчетов.
Неважно, есть у вас архитектура микросервисов или нет, главным соображением при выборе совокупностей также будет выбор контекста с границами, внутри которого они будут действовать. Ограничивая контекст, вы можете обходиться небольшим количеством совокупностей и держать их размер под контролем.
И вновь оказывается так, что мы вынуждены говорить о том, что не можем уделить этому вопросу столько внимания, сколько стоило бы, и мы можем только поощрять вас почитать о нем в другом месте. Ссылка на Фаулера в начале данной врезки — хорошая отправная точка, и одна (или, на самом деле, любая) из книг по DDD будет содержать одну или несколько глав об ограниченных контекстах.
Одна совокупность = один репозиторий
Обозначив конкретные Объекты-сущности как совокупности, мы должны применять правило о том, что только они будут Объектами-сущностями, публично доступными для внешнего мира. Другими словами, нам должны быть разрешены только те репозитории, которые возвращают совокупности.
Примечание
Правило о том, что репозитории должны возвращать только совокупности, является тем главным местом, в котором мы должны обеспечивать принудительную реализацию компромисса о том, что совокупности являются единственным способом попасть в нашу модель предметной области. Постарайтесь не нарушить ее!
В нашем случае мы переключимся с BatchRepository наProductRepository:
# Наши новые Единицы работы (Unit of Work) и репозитории (unit_of_work.py и repository.py)
class AbstractUnitOfWork(abc.ABC):
products: repository.AbstractProductRepository
...
class AbstractProductRepository(abc.ABC):
@abc.abstractmethod
def add(self, product):
...
@abc.abstractmethod
def get(self, sku) -> model.Product:
...На слое ORM потребуетя сделать несколько модификаций, чтобы правильные партии сразу загружались и связывались с объектами Product. Очень хорошо, что благодаря принципу шаблона Репозиторий нам пока не нужно беспокоиться об этом. Мы можем просто воспользоваться своим FakeRepository, а затем пройти сквозь новую модель, чтобы оказаться на сервисном уровне и посмотреть, как он выглядит с Product в качестве главной входной точки:
# Сервисный слой (src/allocation/service_layer/services.py)
def add_batch(
ref: str, sku: str, qty: int, eta: Optional[date],
uow: unit_of_work.AbstractUnitOfWork
):
with uow:
product = uow.products.get(sku=sku)
if product is None:
product = model.Product(sku, batches=[])
uow.products.add(product)
product.batches.append(model.Batch(ref, sku, qty, eta))
uow.commit()
def allocate(
orderid: str, sku: str, qty: int,
uow: unit_of_work.AbstractUnitOfWork
) -> str:
line = OrderLine(orderid, sku, qty)
with uow:
product = uow.products.get(sku=line.sku)
if product is None:
raise InvalidSku(f'Invalid sku {line.sku}')
batchref = product.allocate(line)
uow.commit()
return batchrefЧто насчет производительности?
Мы уже несколько раз упоминали, что моделируем с помощью совокупностей, потому что хотим создать высокопроизводительное программное обеспечение, но здесь мы загружаем все партии, хотя нам нужна всего одна. Возможно, вы сочтете это неэффективным, но есть несколько причин, почему в данном случае нам это подходит.
Во-первых, мы специально моделируем наши данные таким образом, чтобы мы могли сделать один запрос в базу данных и одно обновление для сохранения внесенных нами изменений. Часто бывает так, что такой подход гораздо производительнее по сравнению с системами, которые выдают множество нерегламентированных запросов. В системах, которые не моделируются по такому подходу, мы часто будем обнаруживать, что транзакции понемногу становятся все дольше и сложнее по мере эволюции программного обеспечения.
Во-вторых наши структуры данных будут минимальными с небольшимколичеством строк (strings) и чисел (integers) на каждом ряду. Мы легко можем загрузить десятки и даже сотни партий за несколько миллисекунд.
В-третьих, мы предполагаем, что у нас будет всего лишь 20 или примерно столько партий каждого продукта в конкретный момент времени. После того как определенная партия будет выбрана целиком, мы можем вычесть ее из своих расчетов. Это означает, что извлекаемый нами объем данных не должен со временем выйти из-под контроля.
Если бы мы все-таки предполагали наличие тысяч активных партий для одного продукта, у нас будет пара вариантов. С одной стороны, мы можем использовать отложенную загрузку (lazy-loading) партий в продукте. С точки зрения нашего кода ничто не будет меняться, но за кулисами SQLAlchemy будет пролистывать для нас данные. Благодаря этому будет больше запросов, каждый из которых извлекает меньше рядов. Поскольку нам нужно найти только одну партию с достаточным объемом запаса для нашего заказа, это может сработать довольно хорошо.
Упражнение для читателя
Вы только что увидели основные верхние слои кода, поэтому очень сложно быть не должно. Но мы хотели бы, чтобы вы реализовали совокупность Product, начиная с Batch. Точно так же, как мы.
Разумеется, вы можете сжульничать и скопировать/вставить предыдущие фрагменты. Но, даже если вы так и сделаете, все равно придется решить несколько проблем самостоятельно, например добавить модель в ORM и убедиться в том, что все подвижные части могут взаимодействовать друг с другом. Надеемся, это будет поучительно.
Код вы найдете на гитхабе. Мы поместили "жульническую" реализацию среди делегированных объектов готовой функции allocate(), поэтому оттуда вы сможете продвигаться в сторону чего-нибудь реального.
Паре тестов мы добавили маркер @pytest.skip(). После прочтения данной главы вернитесь к этим тестам, чтобы попробовать реализацию номеров версий. Бонусные баллы начисляются за умение заставить SQLAlchemy сделать это за вас по волшебству!
Если все остальное не получилось, мы просто поищем другую совокупность. Возможно, мы сможем разделить партии по регионам или складам. Возможно, мы сможем изменить структуру стратегии доступа к данным и построить ее вокруг концепции поставки. Шаблон Совокупность (Агрегация, Aggregate) предназначен для того, чтобы помочь справиться с некоторыми техническими ограничениями вокруг согласованности и производительности. Нет одной правильной совокупности, и нам должно быть несложно менять свою позицию, если мы обнаружим, что наши границы вредят производительности.
Оптимистичный параллелизм с номерами версий
У нас есть новая совокупность, то есть мы решили концептуальную проблему выбора того объекта, который будет нести ответственность за границы согласованности. Давайте ненадолго переключимся на разговор о том, каким образом обеспечить целостность данных на уровне базы данных.
Примечание
В данном разделе очень много деталей реализации. Например, некоторые из них касаются исключительно Postgres. Но на более общем уровне мы показываем один подход, с помощью которого можно решать проблемы параллелизма. Но это всего один подход. В данной сфере реальные требования сильно различаются между проектами. Не надейтесь, что сможете копировать и вставлять код отсюда в прозводство.
Мы не хотим держать блокировку на всей таблице парций, но как мы будем реализовывать удержание блокировки только на рядах для определенного SKU?
Один из вариантов ответа заключается в том, чтобы иметь в модели Product некий атрибут, действующий как маркер для изменения всего состояния, и использовать его в качестве единственного ресурса, за который будут сражаться параллельные работники. Если две транзакции одновременно считывают состояние партий, и обе хотят обновить таблицы распределения, мы вынуждаем их обеих также попробовать обновить version_number в таблице продуктов таким образом, чтобы только одна из них могла победить, и состояние партий оставалось согласованным.
Диаграмма последовательности действий: две транзакции пытаются осуществить параллельное обновление Product. На иллюстрации две параллельные транзакции выполняют свои операции считывания в одно и то же время, поэтому они видят Product с версией, например version=3. Они обе вызывают Product.allocate(), чтобы изменить состояние. Но мы настраиваем правила целостности нашей базы данных таким образом, чтобы только одна из них могла выполнить коммит нового Product с версией version=4, а второе обновление отклонялось.
Подсказка
Номера версий — это лишь один подход к внедрению оптимистической блокировки. Вы можете достичь того же самого, настроив уровень локализации транзакций в Postgres на SERIALIZABLE, но это часто приводит к очень сильному падению производительности. Кроме того, номера версий превращают подразумеваемые концепции в явно выраженные.
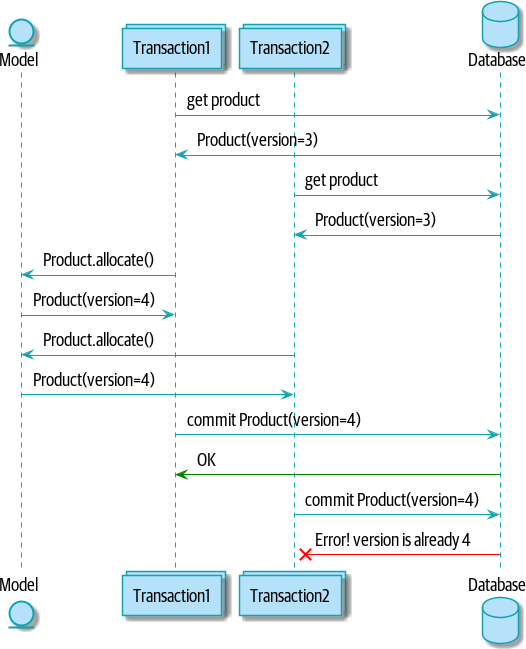
Рисунок 4. Диаграмма последовательности действий: две транзакции пытаются осуществить параллельное обновление Product
Оптимистичный контроль параллелизма и повторные попытки
Здесь мы реализовали то, что называют оптимистичным контролем параллелизма, потому что мы исходили из начального допущения о том, что все будет хорошо, если два пользователя захотят внести изменения в базу данных. Мы полагаем маловероятным, что они будут конфликтовать друг с другом, поэтому мы позволяем им продолжать и просто проверям, чтобы у нас была возможность заметить проблему.
Пессимистичный контроль параллелизма работает на основе допущения о том, что два пользователя будут создавать конфликты, и мы хотим предотвращать конфликты во всех случаях. Поэтому мы блокируем все, просто для безопасности. В нашем примере это будет означать блокирование всей таблицы с партиями или использование SELECT FOR UPDATE. То есть, мы притворяемся, будто исключили их, исходя из соображений производительности. Но в реальной жизни вы захотите сделать свои собственные оценки и измерения.
В ситуации пессимистичного блокирования вам не нужно думать по поводу обработки неудачных попыток, потому что база данных будет их предотвращать за вас (однако вам придется подумать о взаимных блокировках). В ситуации оптимистичного блокирования вам нужно явным образом обработать потенциальную возможность неудачных попыток в (надеемся, маловероятном) случае столкновения.
Обычно неудачная попытка устраняется повторным проведением неудавшейся операции с самого начала. Представьте себе, что у нас есть два заказчика: Гарри и Боб. Каждый совершает коммит заказа на SHINY-TABLE. Оба потока загружают продукт на версии 1 и распределяют запасы. База данных не позволяет проводить параллельное обновление, и заказ Боба завершается неудачей в виде ошибки. Когда мы повторно проводим операцию, заказ Боба загружает продукт на версии 2 и снова пытается осуществить распределение. Если в наличии достаточный объем запаса, все будет в порядке. В противном случае он получит ошибку исчерпания запаса OutOfStock. Многие операции можно выполнить повторно данным способом, если параллелизм создает проблему.
Более подробно о повторных попытках можно прочитать в главе 10 [recovering_from_errors] и [footguns].
Варианты реализации для номеров версий
По сути, существует три варианта реализации для номеров версий:
1. version_number живет в предметной области; мы добавляем этот объект в конструктор Product, а Product.allocate() отвечает за его прирастание.
2. Сервисный слой может это сделать! Строго говоря, номер версии не является заботой предметной области, поэтому сервисный слой должен предполагать, что репозиторий добавляет текущий номер версии к Product, и тогда сервисный слой будет осуществлять его приращение перед выполнением commit().
3. Вполне возможно, что это инфраструктурная задача, поэтому шаблон атомарных операций Unit of Work и репозиторий могут задействовать свое волшебство для ее выполнения. Репозиторий имеет доступ к номерам версий по всем извлекаемым им продуктам, и, когда Unit of Work выполняет коммит, он может осуществлять приращение номера версии для всех известных ему продуктов, предполагая при этом, что они изменились.
Вариант 3 не идеален, потому что нет способа выполнить задачу, не предполагая при этом, что все продукты изменились, поэтому мы будем вынуждены приращивать даже те номера версий, для которых это не нужно.[1]
Вариант 2 подразумевает совместную ответственность сервисного слоя и слоя предметной области за изменение состояния, поэтому данный вариант тоже немного беспорядочный.
В конечном счете, даже если номера версий не должны быть заботой предметной области, возможно, мы решим, что самым чистым компромиссом будет поместить их в предметную область:0
# Избранная нами совокупность <code>Product</code> (src/allocation/domain/model.py)
class Product:
def __init__(self, sku: str, batches: List[Batch], version_number: int = 0): #(1)
self.sku = sku
self.batches = batches
self.version_number = version_number #(1)
def allocate(self, line: OrderLine) -> str:
try:
batch = next(
b for b in sorted(self.batches) if b.can_allocate(line)
)
batch.allocate(line)
self.version_number += 1 #(1)
return batch.reference
except StopIteration:
raise OutOfStock(f'Out of stock for sku {line.sku}')1. Вот так!
Подсказка
Если такое внимание номерам версий удивляет вас, возможно, будет полезно вспомнить, что номер не имеет значения. Важно, что ряд в базе данных Product изменяется каждый раз, когда мы меняем совокупность Product. Вопрос о номере версии — это простой и понятный для людей способ смоделировать вещь, которая меняется при каждой записи, но по факту можно с легкостью каждый раз использовать случайный универсальный уникальный идентификатор.
Тестируем наши правила о целостности данных
Теперь нужно убедиться в том, что мы получим желаемое поведение: если у нас две параллельные попытки осуществить распределение d одном и том же продуктt Product, одна из них должна закончиться неудачей, потому что они не смогут обе обновить номер версии.
Во-первых, давайте подготовим симуляцию "медленной" транзакции с помощью функции, которая будет осуществлять распределение и после этого ненадолго заснет:[2]
# time.sleep может воспроизвести параллельное поведение (tests/integration/test_uow.py)
def try_to_allocate(orderid, sku, exceptions):
line = model.OrderLine(orderid, sku, 10)
try:
with unit_of_work.SqlAlchemyUnitOfWork() as uow:
product = uow.products.get(sku=sku)
product.allocate(line)
time.sleep(0.2)
uow.commit()
except Exception as e:
print(traceback.format_exc())
exceptions.append(e)Далее наш тест будет вызывать данное медленное распределение два раза параллельно с помощью потоков:
# Интеграционный тест (integration test) для параллельного поведения (tests/integration/test_uow.py)
def test_concurrent_updates_to_version_are_not_allowed(postgres_session_factory):
sku, batch = random_sku(), random_batchref()
session = postgres_session_factory()
insert_batch(session, batch, sku, 100, eta=None, product_version=1)
session.commit()
order1, order2 = random_orderid(1), random_orderid(2)
exceptions = [] # type: List[Exception]
try_to_allocate_order1 = lambda: try_to_allocate(order1, sku, exceptions)
try_to_allocate_order2 = lambda: try_to_allocate(order2, sku, exceptions)
thread1 = threading.Thread(target=try_to_allocate_order1) #(1)
thread2 = threading.Thread(target=try_to_allocate_order2) #(1)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
[[version]] = session.execute(
"SELECT version_number FROM products WHERE sku=:sku",
dict(sku=sku),
)
assert version == 2 #(2)
[exception] = exceptions
assert 'could not serialize access due to concurrent update' in str(exception) #(3)
orders = list(session.execute(
"SELECT orderid FROM allocations"
" JOIN batches ON allocations.batch_id = batches.id"
" JOIN order_lines ON allocations.orderline_id = order_lines.id"
" WHERE order_lines.sku=:sku",
dict(sku=sku),
))
assert len(orders) == 1 #(4)
with unit_of_work.SqlAlchemyUnitOfWork() as uow:
uow.session.execute('select 1')1. Мы запускаем два потока, которые будут надежно создавать нужный нам параллелизм: read1, read2, write1, write2.
2. Мы предполагаем, что номер версии прирастает только один раз.
3. Также мы можем проверить появление конкретного исключения, если захотим этого.
4. Далее перепроверим, что успешно проведено только одно распределение.
Принудительное исполнение правил для параллелизма с помощью уровней локализации транзакций в базе данных
Чтобы тест прошел успешно в этом виде, мы можем назначить уровень локализации транзакций на время сессии:
# Определяем уровень локализации для сессии (src/allocation/service_layer/unit_of_work.py)
DEFAULT_SESSION_FACTORY = sessionmaker(bind=create_engine(
config.get_postgres_uri(),
isolation_level="REPEATABLE READ",
))Подсказка
Уровни локализации транзакций — хитрая тема, поэтому будет не лишним уделить время документации Postgres.[3]
Пример пессимистичного контроля параллелизма: SELECT FOR UPDATE
Существует несколько способов решить этот вопрос, но мы покажем один. Благодаря SELECT FOR UPDATE возникает другое поведение. Двум параллельным транзакциям не будет разрешено читать одни и те же ряды одновременно:
SELECT FOR UPDATE — это средство выбора одного или нескольких рядов, которые будут использоваться для блокирования (причем это не обязательно будут те ряды, которые вы обновляете). Если две транзакции пытаются одновременно выполнить SELECT FOR UPDATE по одному ряду, одна из них победит, а второй придется подождать снятия блокировки. Это пример пессимистичного контроля параллелизма.
Вот так можно воспользоваться SQLAlchemy DSL, чтобы предусмотреть FOR UPDATE в момент запроса:
# SQLAlchemy with_for_update (src/allocation/adapters/repository.py)
def get(self, sku):
return self.session.query(model.Product) \
.filter_by(sku=sku) \
.with_for_update() \
.first()В результате шаблон параллелизма уже не будет таким:
read1, read2, write1, write2(fail)и станет таким:
read1, write1, read2, write2(succeed)Некоторые называют это режимом неудачного "чтения-изменения-записи". Можно почитать хороший обзор "PostgreSQL Anti-Patterns: Read-Modify-Write Cycles".
На самом деле, у нас нет возможности обсуждать все компромиссы между REPEATABLE READ и SELECT FOR UPDATE, а также сравнивать оптимистичную и пессимистичную блокировку в целом. Однако, если у вас есть тест, похожий на наш, вы можете обозначить нужное вам поведение и посмотреть, как оно изменится. Также вы можете использовать тест в качестве основы для нескольких экспериментов с производительностью.
Резюме
Выбор конкретного варианта для контроля параллелизма будет сильно варьироваться в силу обстоятельств, на фоне которых работает бизнес, и выбранных технологий хранения, но мы хотим вернуть данную главу к концептуальной идее совокупности: мы прямо моделируем один объект как главую входную точку в какое-нибудь подмножество своей модели. Причем данный объект несет ответственность за принудительное соблюдение инвариантов и правил бизнеса, которые распространяются на все эти объекты.
Очень важно правильно выбрать совокупность, и это решение вы можете со временем пересмотреть. По этой теме можно почитать во всевозможных книгах про DDD. Также мы рекомендуем эти три доступные онлайн работы об эффективном проектировании совокупности, которые подготовил Вон Вернон (Vaughn Vernon) (автор "Красной книги").
В таблице "Совокупности: компромиссы" есть несколько мыслей по поводу компромиссов при реализации шаблона Совокупность (Агрегация, Aggregate).
Таблица 1. Совокупности: компромиссы
|
За |
Против |
|
· Возможно, в Python нет "официальных" внутренних и публичных методов, но у нас есть общая договоренность по поводу подчеркиваний, потому что часто бывает так, что полезно отметить объекты для "внутреннего" пользования и "внешний код". Выбор совокупностей станет просто следующим уровнем сложности: у вас есть возможность решить, какие классы вашей модели предметной области будут публичными, а какие — нет. · Моделирование наших операций внутри прямо обозначенного контура согласованности помогает нам избегать проблем с производительностью при использовании ORM. · Если возложить на совокупность единоличную ответственность за изменение состояний в подчиненных моделях, то работать с системой будет проще, а еще будет проще контролировать инварианты. |
· Еще одна новая концепция, которую придется освоить разработчикам-новичкам. Мозг и без этого перегружен попыткой объяснить разницу между Объектами-сущностями и Объектами-значениями. Теперь еще добавляется третий вид объектов в модели предметной области? · Строгое соблюдение правила о том, что мы будем менять только одну совокупность за раз — сильный культурный сдвиг. · Иногда бывает сложно организовать согласованность в конечном счете между совокупностями. |
Совокупности и согласованность: краткое повторение
Совокупности будут вашей входной точкой в модель предметной области
Ограничивая количество способов изменения объектов, мы упрощаем работу с системой.
Совокупности несут ответственность за контур согласованности
Задача совокупности в том, чтобы управлять правилами нашего бизнеса в отношении инвариантов, потому что они распространяются на группу взаимосвязанных объектов. Совокупность как раз должна проверять, чтобы входящие в нее объекты согласовывались друг с другом и с нашими правилами, а также отвергать изменения, которые будут нарушать правила.
Проблемы совокупностей и параллелизма идут рука об руку
Размышяя о том, каким образом реализовать данные проверки согласованности, мы в итоге будем думать про транзакции и блокировки. Выбор правильной совокупности — это вопрос производительности и концептуальной организации вашей предметной области.
Часть I: краткое повторение
Вы помните диаграмму компонентов для нашего приложения по состоянию на конец Части I? Эту диаграмму мы показывали в начале Части I, чтобы предварительно показать, куда мы движемся?
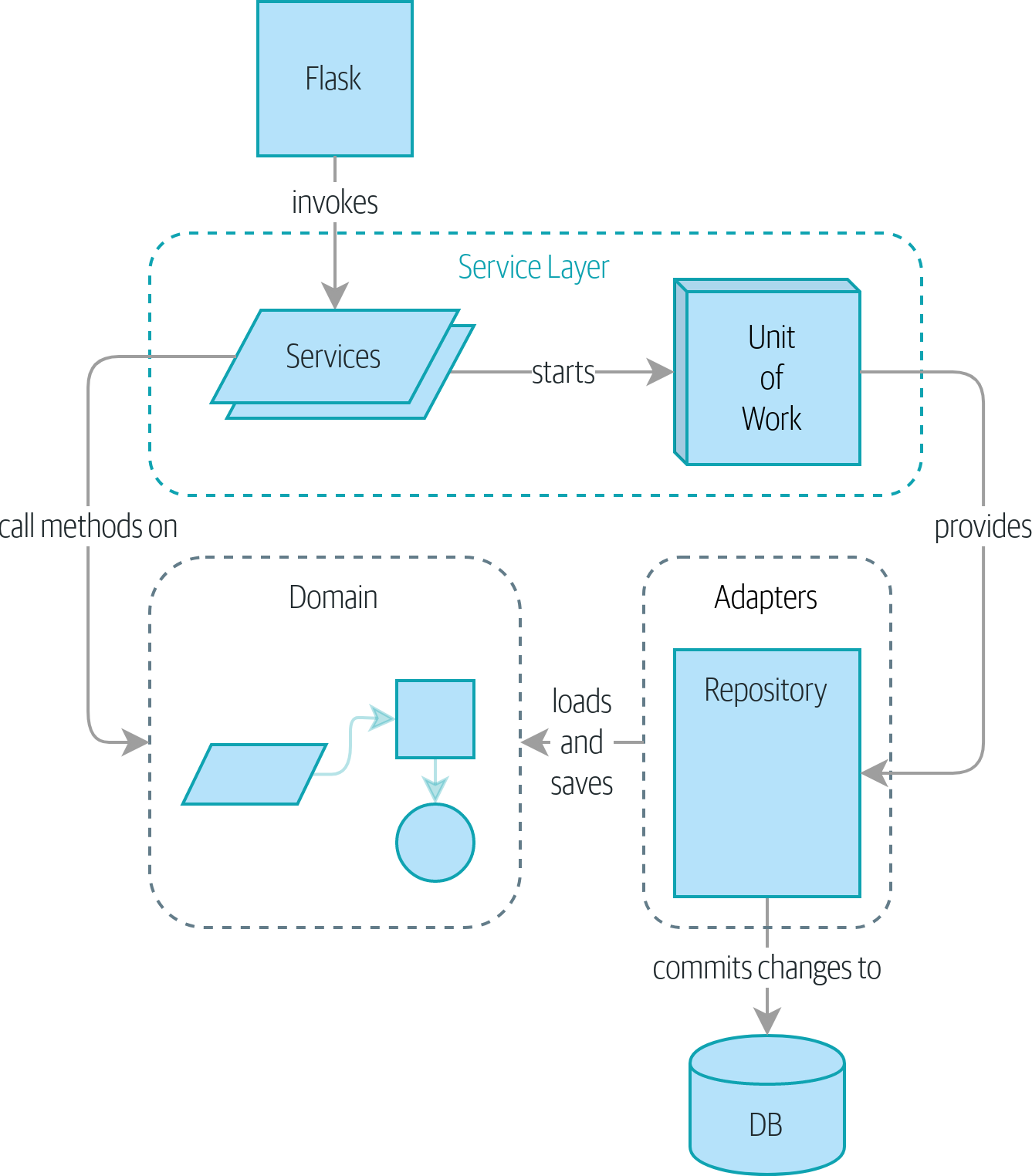
Рисунок 5. Диаграмма компонентов для нашего приложения по состоянию на конец Части I
Вот здесь мы и оказались в конце Части I. Чего мы достигли? Мы посмотрели, как построить модель предметной области, которую реализует набор блочных тестов высокого уровня. Наши тесты — это живая документация: в изящном и читаемом коде они описывают поведение нашей системы, правила, которые мы согласовали с владельцами нашего бизнеса. Когда требования нашего бизнеса меняются, у нас есть уверенность в том, что наши тесты помогут подтвердить новую функциональность. Когда в проект придут новые разработчики, они смогут прочитать наши тесты и поймут, как все работает.
Мы разделили инфраструктурные части нашей системы, например базу данных и обработчиков API, чтобы иметь возможность подключить их с внешей стороны нашего приложения. Это поможет нам сохранять хороший уровень организации в кодовой базе и не позволит нарастить огромный шар грязи.
С помощью принципа разворота зависимости (dependency inversion) и шаблонов проектирования, например Репозиторий (Repository) и Единица Работы (Unit of Work), вдохновением для которых были шаблоны о портах и адаптерах, мы смогли реализовать TDD (разработку на основе тестирования) на высоких и низких уровнях одновременно, а также сохранили здоровую пирамиду тестов. Мы можем тестировать свою системы от края до края, при этом потребность в интеграционных и сквозных тестах сохраняется на минимальном уровне.
Наконец, мы обсудили идею границ согласованности. Мы не хотим блокировать всю систему каждый раз, когда происходит изменение, поэтому нам нужно выбирать, какие части будут согласовываться друг с другом.
Если система маленькая, это будет все, что вам нужно, и вы можете поиграться с идеями проектирования на основе предметной области. Теперь у вас есть инструменты, которые позволят строить модели предметной области, не знающие о существовании базы данных. Причем данные модели будут отражать единый язык экспертов вашего бизнеса. Ура!
Примечание
Рискуя погрузиться в детали, хотим отметить, что мы очень старались подчеркнуть, что использование каждого шаблона имеет свою цену. Каждый слой непрямой связи вынуждает мириться со сложностью и дублированием нашего кода, а также озадачит программистов, которые никогда до этого не видели такие шаблоны. Если у вас простое приложение, которое оборачивает базу данных по принципу CRUD (создание, чтение, обновление, удаление), и, скорее всего, в обозримом будущем оно не выйдет за эти пределы, все эти шаблоны вам не нужны. Не стесняйтесь и пользуйтесь Django. Избавьте себя от множества проблем.
В Части II увеличим масштаб и поговорим на более крупную тему: если совокупности будут границами, а менять можно только одну за раз, как мы будем моделировать процессы, пересекающие границы согласованности?
1. Возможно, у нас получится частично задействовать магию ORM/SQLAlchemy, чтобы получать уведомления о грязных объектах, но как это будет работать в обычной ситуации, например с CsvRepository?
2. time.sleep() хорошо работает в нашем примере, но это не самый надежный/эффективный способ воспроизводить баги параллелизма. Подумайте по поводу семафоров или других таких же примитивов синхронизации, которые используются вашими потоками, чтобы гарантировать поведение более уверенно.
3. Если вы не пользуетесь Postgres, вам придется почитать другую документацию. Досадно, что среди баз данных понятия сильно различаются. Например, SERIALIZABLE в Oracle — это то же самое, что REPEATABLE READ в Postgres.