Содержание
- Вступление
- Переменные в Си
- Объекты и ссылки в Python
- Подсчет ссылок
- Увеличение подсчета ссылок
- Уменьшение подсчета ссылок
- Элементы в каждом объекте Python
- Сбор мусора (garbage collection)
- Сбор мусора через подсчет ссылок (reference counting)
- Сбор мусора через прослеживание (tracing)
- Сбор мусора разных поколений (generational garbage collection)
- Объем памяти программы после очистки
- Оптимизация кода для эффективного использования памяти
- Глобальный блок интерпретатора (global interpreter lock)
- Заключение и дополнительные материалы
Вступление
Всем привет, я — профессиональный инженер-программист уже гораздо дольше десяти лет. Работала в компаниях, о которых вы, возможно, слышали, например HBO. Сейчас я работаю в Microsoft консультантом по облачным разработкам. Это означает, что моя цель в облегчении и развитии использования Python для разработчиков по всему миру.
Слайды для этого выступления доступны в сети, так что можно взять копию и следить за содержанием или отправить коллегам. Ссылки можно найти везде, полезных ресурсов тоже много. Я тоже отправила в твиттер ссылку на слайды, так что можно взять там.

Почему нам вообще нужно беспокоиться по поводу управления памятью. Понимание этого процесса помогает нам писать более эффективный код. Знание помогает решать проблемы низкой скорости, медленных программ. Оно помогает устранять неполадки и иногда помогает во время отладки.
Бывает, что по-настоящему хочется ответить на вопрос о том, почему программе нужно так много памяти, а потребление памяти растет с течением времени.
Сегодня я хочу рассказать вам об инструментах, которые помогут ответить на эти вопросы. Как бонус, мы научимся писать более эффективные программы, что поможет выглядеть умнее. Итак, чему мы научимся сегодня.
Возможно, вы уже интересовались этой темой раньше, но в ней очень легко утонуть в огромном объеме информации и новых терминов. Поэтому я хочу дать вам глоссарий и основные понять. Цель — сделать тему более легкой для понимания даже для того, кто едва приступил.
Данное выступление создаст для вас стартовую площадку для более глубокого погружения. К сожалению, мы не станем экспертами в управлении памятью после завершения. Небольшой дисклеймер: я буду говорить только про CPython. Так, слышу, кто-то давит смех. Ладно.
Переменные в Си
Итак, чтобы понять, каким образом работает управление памятью в Python, придется немного зайти в философию и спросить себя, что такое переменная (variable).

Посмотрим на этот пример, он очень упрощенный. Здесь изображены две переменные в том стиле, как принято в Си. Как видим, переменным а и b присваивается значение 5.

Как известно, в двоичном представлении 5 — это 101. Нам нужно продекларировать тип переменной (variable type) перед присваиванием. То есть, мы говорим, что число (integer) равно пяти. Зачем?
В Си значения живут в ячейке фиксированного объема (fixed size bucket). Сопоставление происходит один к одному. На слайде мы видим переменную с именем, адрес в памяти и хранящееся значение. Значение 101 копируется поверх снова и снова в каждую ячейку памяти, когда мы декларируем, что число равно пяти.
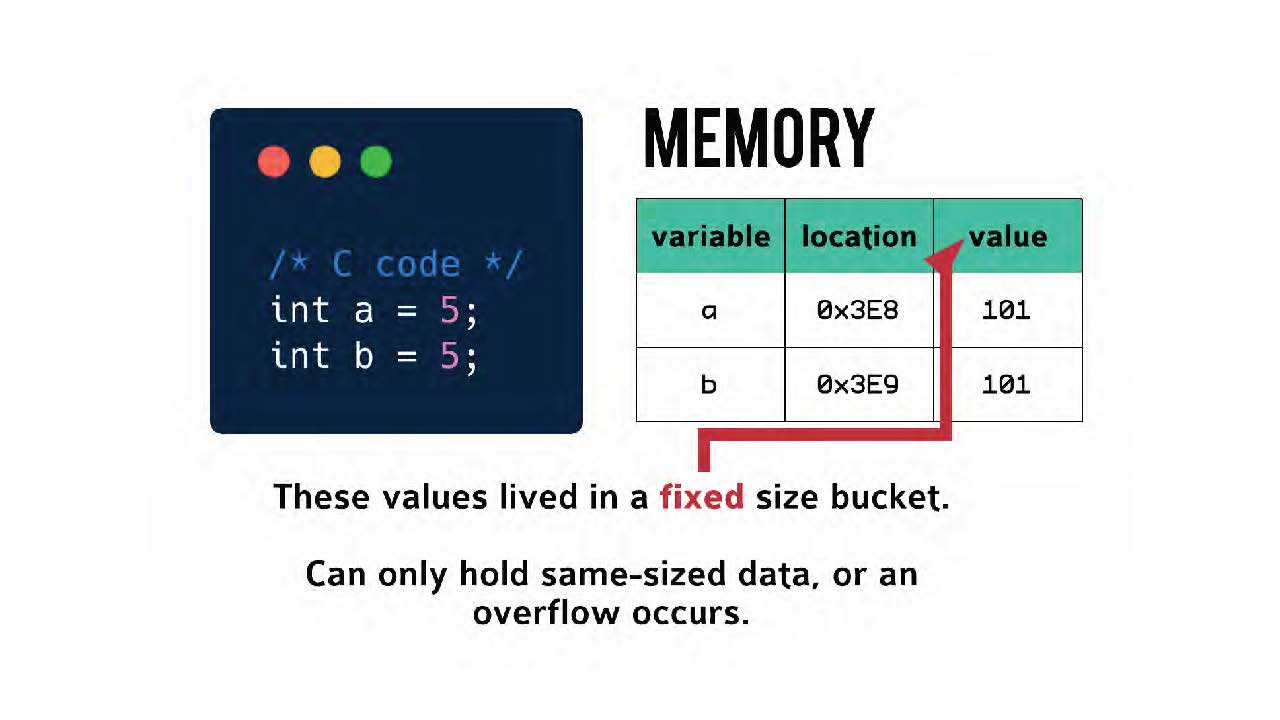
Именно поэтому нам нужно декларировать тип: чтобы компилятор знал, какого размера ячейку памяти нужно подготовить. Такие ячейки могут содержать данные только одного и того же размера. Иначе может произойти ошибка переполнения (overflow error).
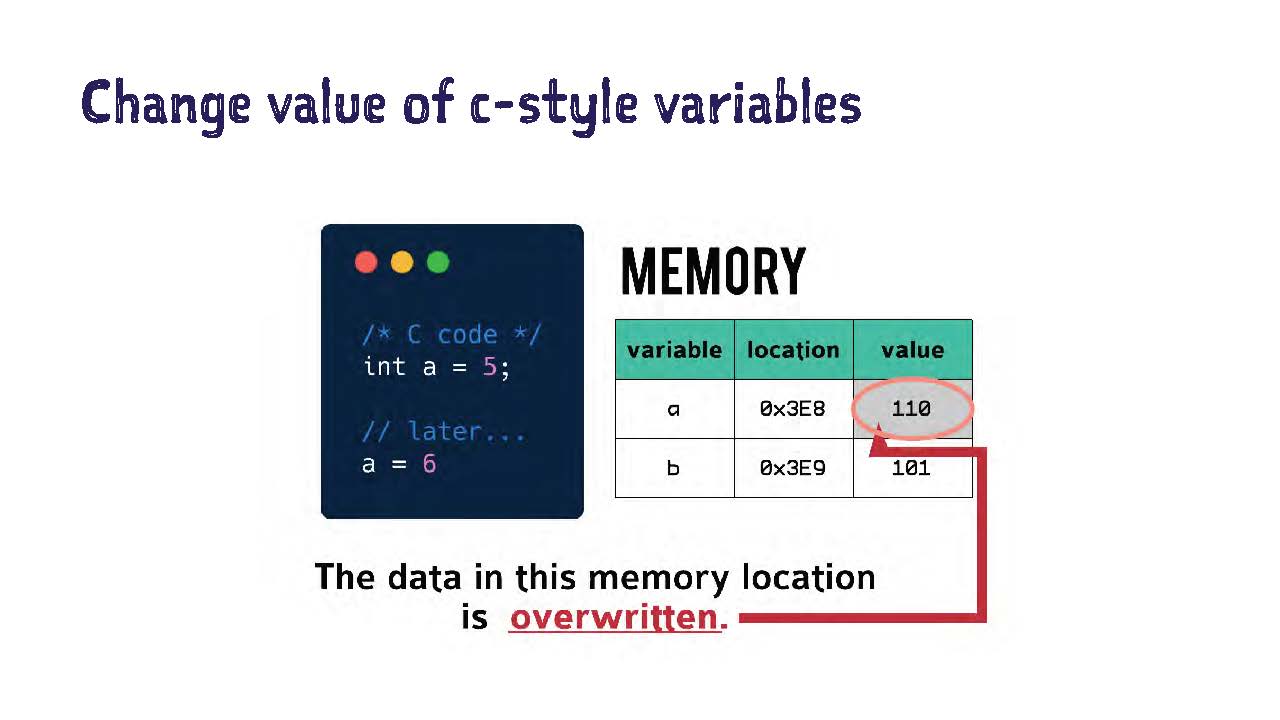
Что произойдет, если мы поменяем значение нашей переменной в Си. Допустим, поставим значение шесть при изменении значения этой переменной. В ячейке памяти значение перезаписывается (overwritten), и теперь в ней 110.
Объекты и ссылки в Python
В Python не переменные, а имена. Каким образом Python хранит объекты в памяти? Это цепочка из имен (names), ссылок (references) и объектов (objects).

Каждому объекту может быть присвоено много имен, например, А, B, X, Y и так далее. Все эти имена ссылаются на этот объект.
Представим себе две разные категории объектов. У нас есть простые объекты (числа и строки). Они простые в том, их значение хранится только в одном месте в памяти.
Еще у нас есть объекты-контейнеры (словари, списки и определенные пользователем классы). Они могут хранить ссылки на простые объекты и даже на другие контейнеры или объекты контейнерного типа.
Подсчет ссылок
Увеличение подсчета ссылок
Что такое ссылка (reference). Это имя или контейнерный объект, который указывает на другой объект. Мы заинтересованы в том, чтобы отслеживать количество ссылок на определенный объект. Это называется подсчетом ссылок (reference count).

Всем, кто следит за выступлением через телефон или ноутбук, рекомендую сейчас сосредоточиться, потому что это основной момент всего выступления.
Как осуществляется подсчет ссылок. Возьмем очень простой пример, пусть x будет равно 300. Теперь число ссылок на значение 300 увеличилось на одну.

Практика показывает, что по разным причинам подсчет ссылок на определенный объект в написанной на Python программе не всегда начинается с нуля.
После этого, когда в нашей программе уже есть x, равный 300, мы можем добавить y, который тоже будет равен 300.
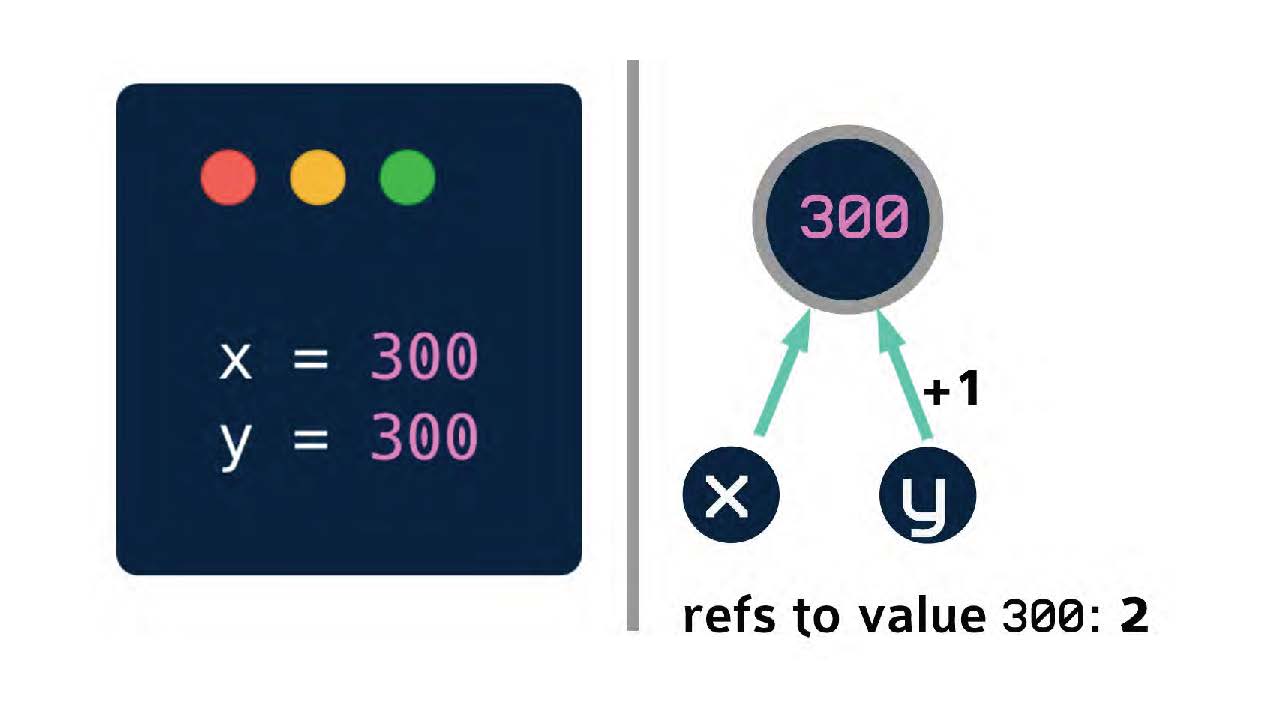
Вместо того, чтобы создать новую ячейку в памяти для этого значения 300, как это было в предыдущем примере с Си, просто добавляется еще одна ссылка на существующий объект. Теперь подсчет ссылок на значение 300 стало равно двум.
Еще пример. Появляется список z, один из контейнерных объектов. В списке мы даем ссылку на 300 еще два раза.
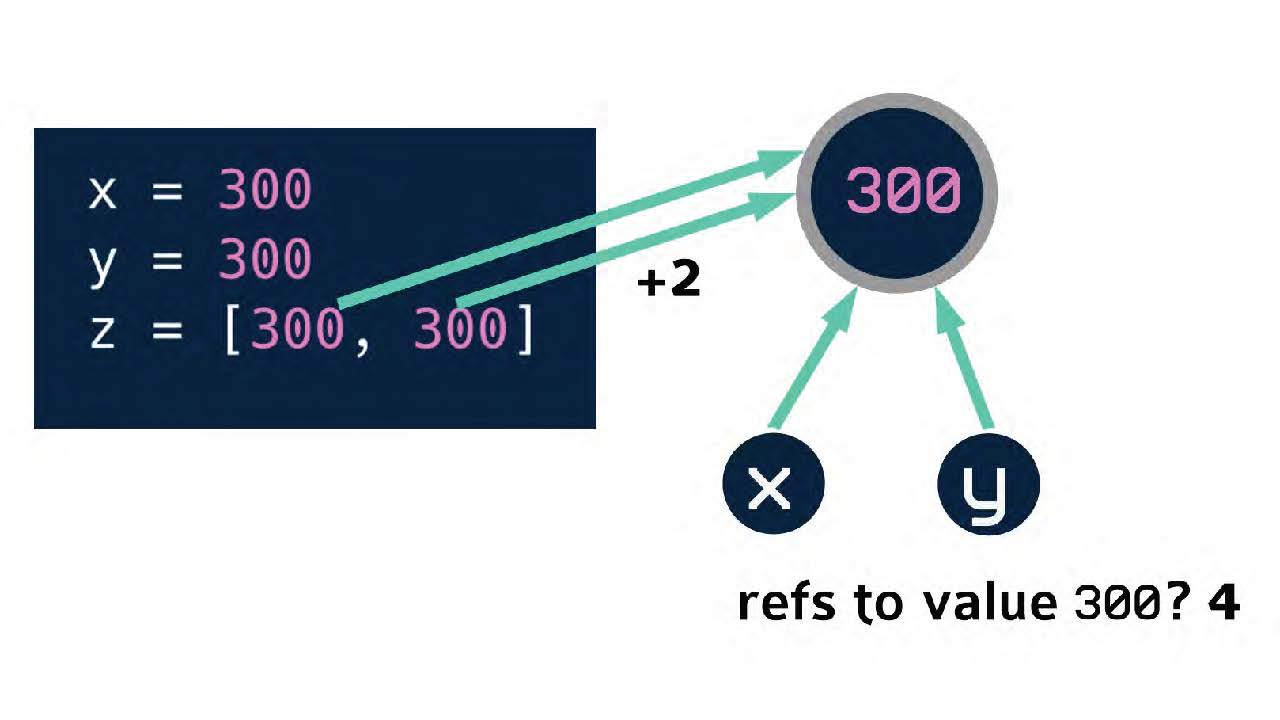
Как видим, ссылки не обязательно создавать индивидуально с помощью имени. С помощью декларации X, Y и Z мы мы увеличили подсчет ссылок на значение 300 до четырех в общей сложности.
Уменьшение подсчета ссылок
Теперь, когда мы разобрались, каким образом увеличивается подсчет ссылок, давайте разберемся, как можно его уменьшить. Есть несколько способов.
Первый: поменять ссылку на что-нибудь другое.

В этом примере я переведу x на True, а y — на None. Таким образом я удаляю две ссылки на значение 300 и снижаю его подсчет ссылок на два.
Второй: воспользоваться ключевым словом del

На этом примере я удаляю ссылку между x и 300, написав del x. Подсчет ссылок становится меньше на один.
Обращаю внимание на то, что это просто пример. Не нужно специально предусматривать в Python использование оператора del (del statement) в целях управления памятью (memory management).
Что конкретно делает del? Оно не удаляет объекты. Его наименование немного вводит в заблуждение. На самом деле оно удаляет имя как ссылку на объект, и это, в свою очередь, снижает подсчет ссылок на единицу.
Третий: выйти из области действия (scope)
У меня есть пример с очень простой функцией.
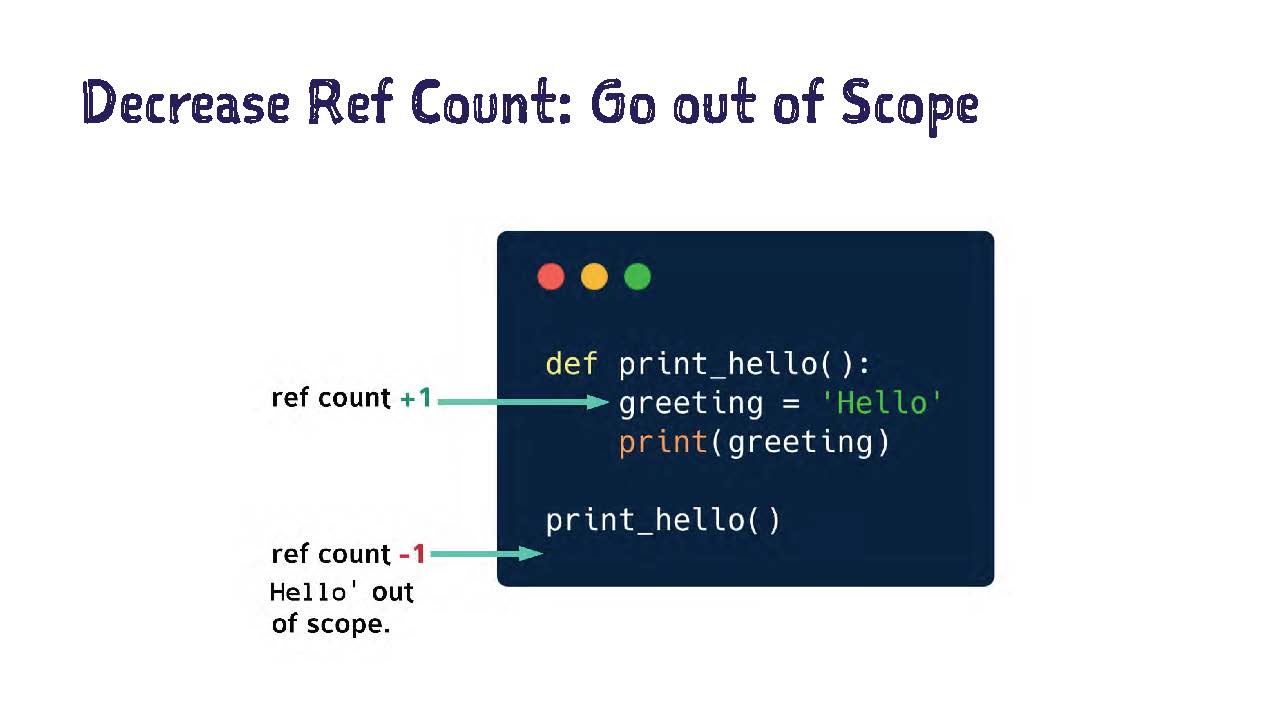
Она пишет hello. Я создаю переменную greeting, которая будет равна строке hello. Когда я вывожу на печать (print), то, благодаря запуску функции подсчет ссылок на слово hello повышается на единицу.
Когда эта функция закрывается, наша переменная greeting выходит из области действия (scope), и, когда значение выходит из области действия, то подсчет ссылок на него снижается на единицу.
Больше ссылок нет. Дальнейшее существование этого объекта нам больше не нужно, поэтому мы можем без вреда удалить его из памяти.
Здесь нам нужно проявлять осторожность и следить за различием между локальным и глобальным пространством имен (namespace). Если остающийся подсчет ссылок снижается после выхода объекта из области действия, то он попадает в глобальное пространство имен.
Получается, что объект никогда не выйдет за пределы области действия, и его подсчет ссылок может никогда не снизиться до нуля. Здесь важно следить, чтобы большие или комплексные объекты никогда не попадали в глобальное пространство имен, потому что это может сильно повредить внутренним процессам.
Элементы в каждом объекте Python
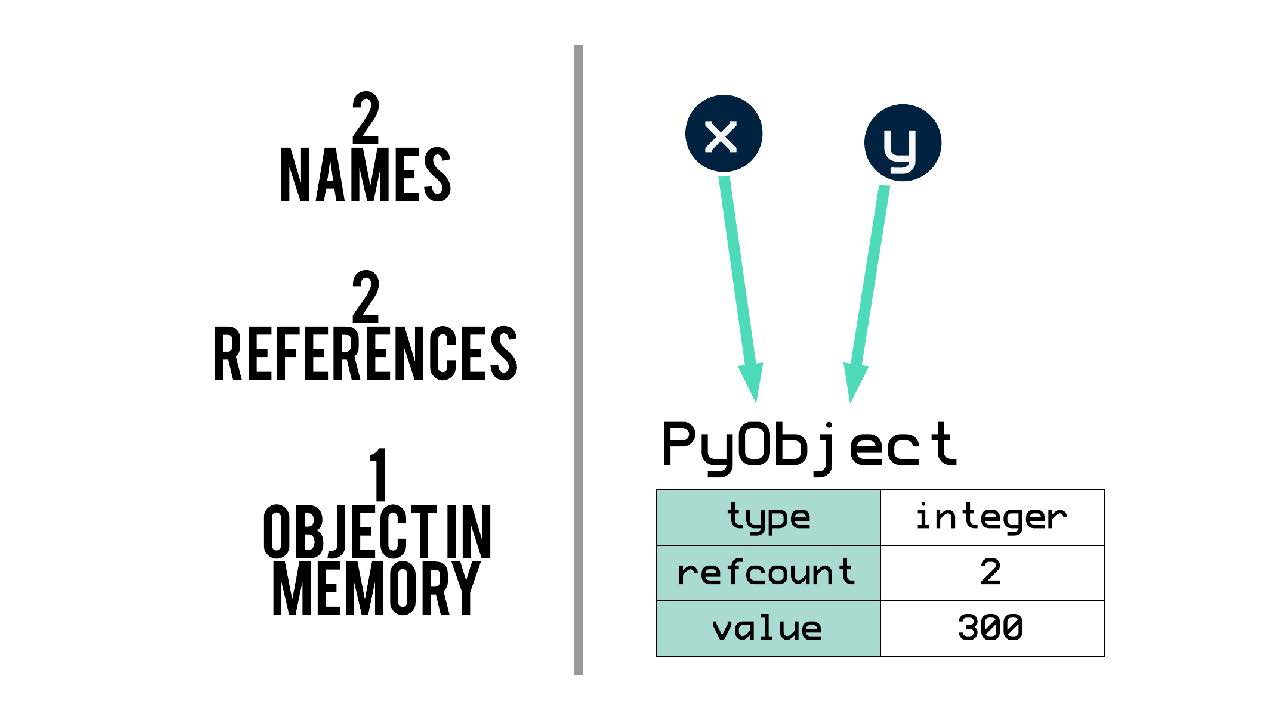
В Python каждый объект содержит в себе три элемента: тип (type), подсчет ссылок (reference count) и значение (value).

В предыдущих примерах у нас было два имени x и y, которые создавали две ссылки на один объект в памяти. Этот объект знает свой тип, то есть он знает, что является числом. Еще он знает, что на него есть две ссылки, и что его значение равно 300.
Давайте докажем, что так оно и есть. Если хотите попробовать сами, заверните код в функцию или попробуйте запустить его в файле.
Сначала я декларирую x и y, чтобы они оба были равны 300. Затем заглянем под капот с помощью функции-идентификатора id().

Она покажет нам ячейку и память объекта Python. При выводе на печать мы видим id для x и y. Значения совпадают.
Еще мы можем спросить у Python, содержат ли эти имена ссылки на один и тот же объект, с помощью ключевого слова is. Оно сравнивает два объекта и показывает, находятся ли они в одной и той же ячейке памяти (memory location).
Поэтому если я выведу на печать значение для выражения x is y, то получу True.
Все вышеприведенное вело нас к процессу сбора мусора/
Сбор мусора (garbage collection)

Что такое сбор мусора (garbage collection)? С его помощью программа автоматически освобождает память, когда занимаемое объектом пространство больше не используется.
Когда-то давно программистам приходилось вручную выделять (allocate) и освобождать (deallocate) память. Внимание, спойлер! Это было не очень... Если забудешь освободить память, то, в связи с постоянным уменьшением объема памяти, если произойдет переполнение памяти, программа вылетает.
Сбор мусора явился как спаситель. Этот процесс становится немного понятнее, если представить его как рециркуляцию памяти.
Есть два основных способа собрать мусор: подсчет ссылок (reference counting) и отслеживание (tracing). Можно сказать, что Python использует оба.
Сбор мусора через подсчет ссылок (reference counting)
Как работает сбор мусора через подсчет ссылок. Недавно мы видели, как можно добавлять и удалять ссылки. Подсчет ссылок повышается после присваивания (assignment) и уменьшается после удаления ссылки. Когда подсчет ссылок снижается до нуля, можно запускать процесс и удалять объект, если мы знаем, что больше не будем им пользоваться.
Это может вызвать интересный каскадный эффект, потому что при снижении подсчета ссылок для любых объектов, на которые ссылался удаленный объект, то, если их подсчет ссылок в результате снижается до нуля, то они точно так же могут быть удалены.
Это означает, что снижение одного подсчета ссылок до нуля может привести к удалению из памяти большого количества объектов.
Сбор мусора через подсчет ссылок имеет преимущества. Во-первых, его легко использовать. Еще, когда подсчет ссылок снижается до нуля, объект сразу же удаляется.
Но недостатки у него тоже есть. Занимается много пространства, потому что нужно хранить подсчет ссылок для всех объектов, и эти данные должны где-то жить. Также осложняется выполнение кода, потому что подсчет ссылок меняется при каждом присвоении.
К сожалению, еще есть два неприятных момента, связанных с подсчетом ссылок. Он не ориентирован на многопоточное исполнение (thread-safe). Что случится, если два потока (threads) одновременно попытаются повысить и понизить подсчет ссылок для одного объекта? Возможно, мы столкнемся с довольно большой проблемой.
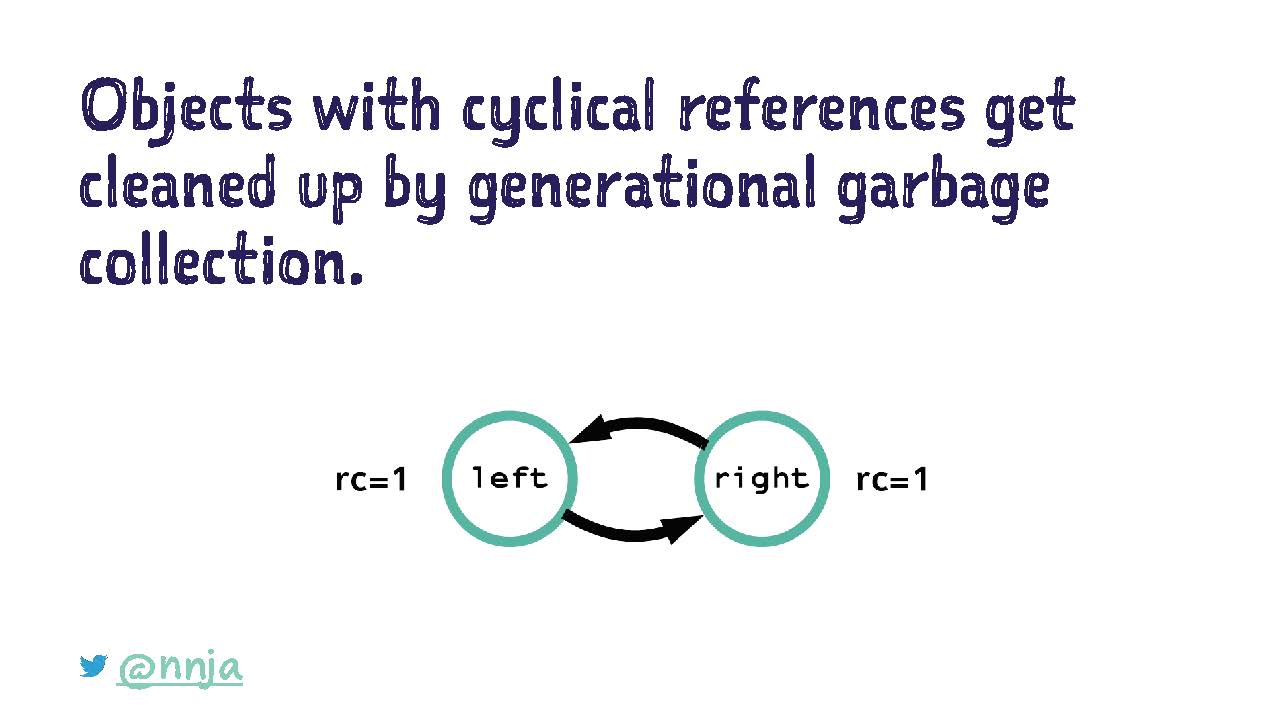
Во-вторых, сбор мусора через подсчет ссылок не находит циклические ссылки (cyclical references). Что такое циклическая ссылка. Давайте подумаем о ней с помощью примера.

Здесь у нас простой класс Note. В нем есть переменная value и ссылка на элемент child. Допустим, мы декларируем три элемента root, left и right.
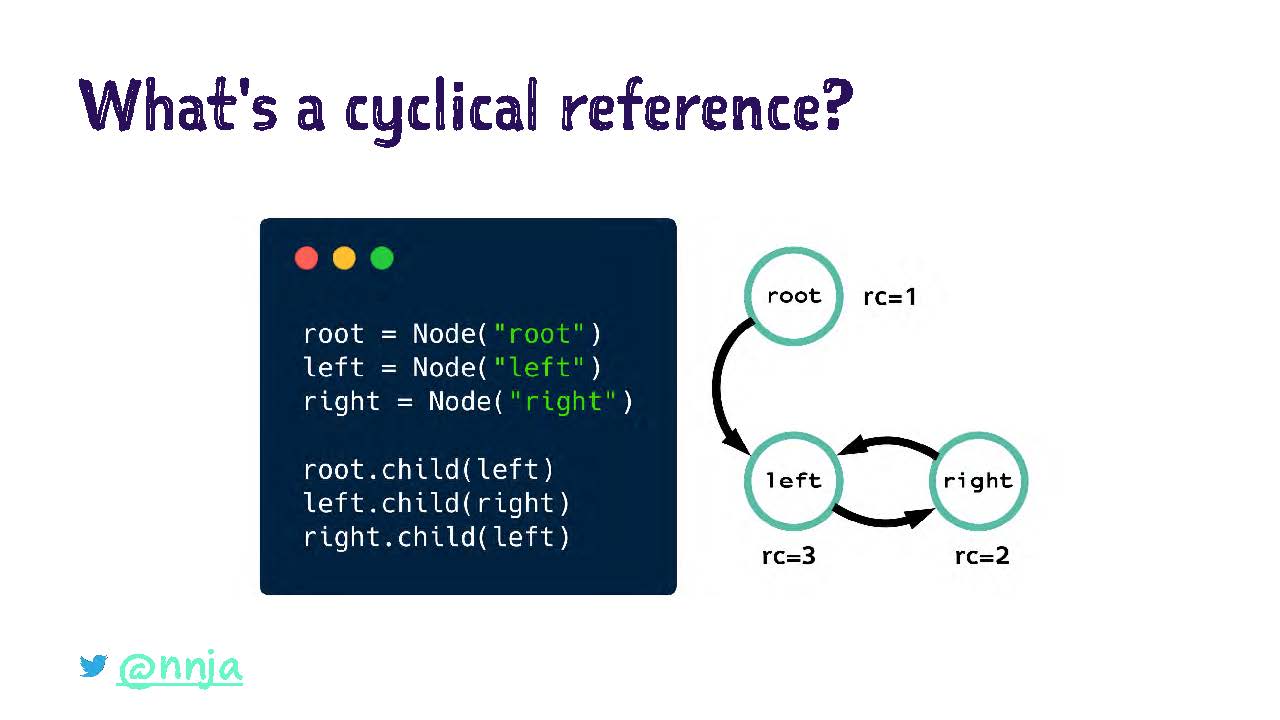
Затем мы создадим ссылку от элемента root к элементу left, от элемента left к элементу right и от элемента right обратно к элементу left. Что будет с подсчетом ссылок для этих объектов?
Подсчет ссылок для root — один, у него ссылка только под своим именем.
Подсчет ссылок для left — три, у него ссылки под своим именем, а также от root и right.
Подсчет ссылок для right — два, у него ссылки под своим именем и от left.
Цикличность появляется в случае, когда объекта показывают или ссылаются друг на друга, и больше никаких объектов нет. Что происходит, когда мы удаляем имена, которые являются ссылками на эти элементы.
Ссылка 39
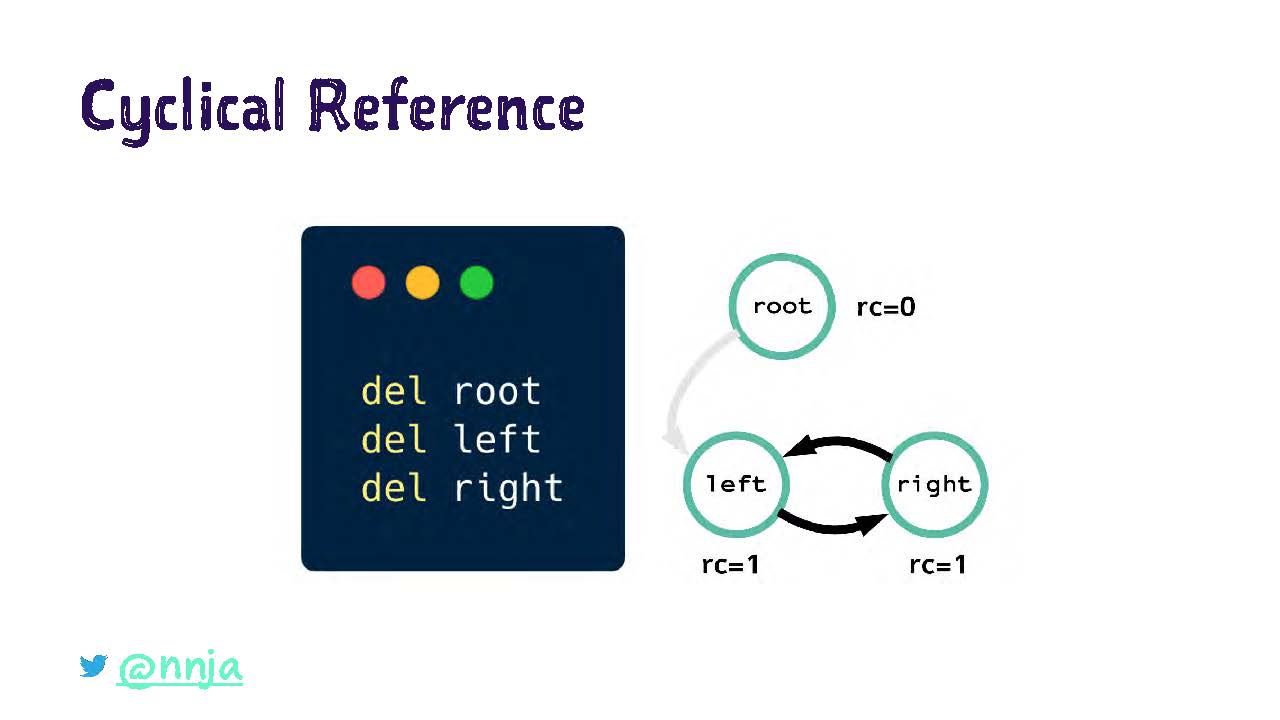
Мы вызываем оператора del на элементы root, left и right. Это означает, что имена root, left и right больше не ссылаются на новые элементы, но внутренние ссылки внутри объекта child еще существуют.
Ситуация сложилась следующая. Подсчет ссылок по элементу root равен нулю, а по элементам left и right — все еще одному, потому что эти элементы по-прежнему ссылаются друг на друга.
Сейчас эти объекты уже не доступны из программы, потому что эти ссылки потеряны для нее. Сбор мусора через подсчет ссылок самостоятельно не сможет удалить объекты, имеющие циклические ссылки.
Ранние версии Python имели только такой функционал сбора мусора (через подсчет ссылок), и это вызывало много проблем. Циклические ссылки создаются для многих объектов, например в графах (graphs), двусвязных списках (double-linked lists).
Уже тогда мы понимали, что нам нужно что-нибудь другое. Поэтому сегодня мы говорим о двух видах сбора мусора.
Сбор мусора через прослеживание (tracing)
Вторая стратегия сбора мусора называется прослеживанием. В нем обычно используется алгоритм под названием "пометка с очисткой" (mark-and-sweep).
Этот алгоритм запускается в случае, когда ряд объектов превышает определенный порог в памяти. Первая часть алгоритма называется пометка (marking). Она начинает с корня и перемещается по диаграмме ссылок, следуя по всем ссылкам и помечая доступные.
На примере, который показан на следующем слайде доступные объекты (reachable objects) помечены зеленым цветом, а не доступные остаются синими (они не помечаются).

После завершения маркировки начинается этап очистки (sweep), во время которого удаляются не доступные объекты, которые не были помечены.
Этот алгоритм ловит циклические ссылки. Они помечаются и очищаются аналогично двум элементам в нижнем левом углу.
Итак, что использует Python. Мы знаем, что в нем используется подсчет ссылок, но еще в нем используется стратегия под названием "сборка мусора разных поколений" (generational garbage collection). Это разновидность сбора мусора через прослеживание.
Сбор мусора разных поколений (generational garbage collection)
Нам нужна еще одна стратегия, потому что, как мы помним, подсчет ссылок не очищает эти висящие циклические ссылки.
Данный алгоритм сбора мусора основан на теории о том, что большинство объектов умирает в юности. Звучит очень грустно.
Часто бывает так, что объекты создаются только для хранения временных значений или для вызова функции (function call). Повторно они не используются.
Как же работает такой сбор мусора разных поколений. Python ведет список всех созданных объектов во время выполнения программы. На самом деле он веды три списка, поколения 0, 1 и 2.
Создаваемые объекты отправляются в поколение 0. Если объект выживает после сбора мусора, то он переводится в следующее поколение. Я изо всех сил постараюсь сейчас не пошутить по поводу Стартрека, давайте вести себя профессионально.
Каждый объект хранится только в одном поколении, и мы можем проводить оптимизацию через сбор молодых объектов из поколения 0 чаще, чем для более старых.
В поколении списков хранятся только контейнерные объекты (container objects) с подсчетом ссылок больше нуля. Этот процесс похож на алгоритм пометки и очистки, но вместо хранения списка со всеми объектами осуществляется только прослеживание объектов, потому что это только те типы объектов, в которых может появиться циклическая ссылка.
Здесь есть несколько хитросплетений между изменяемыми (mutable) и не изменяемыми (immutable) контейнерами, в которые я не буду углубляться. В целом, это означает, что отслеживается и сканируется меньше объектов, и выполнение сбора мусора занимает меньше времени.
Когда количество объектов в поколении достигает порога, Python выполняет алгоритм сбора мусора по этому поколению и всем поколениям моложе него. То есть, сбор мусора по поколению 2 также подразумевает, что мы соберем 0 и 1.
Что же происходит во время цикла сбора поколений. Сначала Python создает список всех объектов и запускает алгоритм для поиска ссылочных циклов. Прошу извинить, но во время этого выступления данная тема не будет раскрываться, но уделить ей время стоит.
Далее, если у объекта нет внешних ссылок, он попадает в список на отбраковку (discard list). После завершения этого цикла можно высвободить эти объекты.
Объекты из списка на отбраковку, которые уцелеют после цикла сбора мусора, переводятся в следующее поколение. Это означает, что объекты последнего поколения 2 сохраняются во время выполнения программы.
Базовая идея этого процесса в том, что когда подсчет ссылок по объекту достигает нуля, мы можем сразу его удалить. Но если есть объекты с циклами, то их нужно очищать. Придется подождать, пока выполнится сбор мусора разных поколений. Для этого нужно подождать выполнения критериев для сбора мусора.
Поэтому если ваша программа замедляется или достигла порога памяти, возможно, виновником являются циклические ссылки.
Если мы снова посмотрим на наши старые циклические ссылки по элементам left и right, то для них подсчет ссылок по-прежнему равен одному. Эти циклические ссылки будут очищены сбором мусора разных поколений.
Объем памяти программы после очистки
Теперь мы подошли к вопросу, который я слышала очень много раз. Почему объем памяти для программы Python не уменьшается после сбора мусора?
Здесь играют роль несколько факторов. Во-первых, память освобождается фрагментами. Не всегда бывает так, что она освобождается одним большим блоком. То есть, когда мы говорим о том, что происходит на самом деле?
Память освобождается и снова становится доступна для программы Python, ее можно занять другими объектами. Она не обязательно возвращается обратно в систему.
Оптимизация кода для эффективного использования памяти
Итак, небольшие советы по оптимизации кода, чтобы повысить эффективность использования памяти.
Стратегия первая: воспользоваться специальным методом __slots__.

Мы помним, что каждый экземпляр (instance) класса в Python содержит словарь (dictionary) с именами и значениями.
Например, можно создать пустой класс dog и присвоить какие-нибудь произвольные значения для экземпляров, для примера, Buddy.
Слай 57
Если я выведу на печать __dict__ по этому экземпляру класса, то мы увидим, что в нем есть ключ name и значение Buddy.
Но что случится, если мы попытаемся добавить имя к строке Hello. Например, попробуем добавить строку Fred.

Мы увидим ошибку, потому что объекты-строки (string object) не имеют атрибута name. Это все логично, ведь нам не нужно заниматься произвольными атрибутами во встроенных классах.
Мы можем использовать метод __slots__, чтобы эмулировать данные действия в своих классах. Это позволит нам не назначать дополнительные атрибуты для экземпляров.
Метод __slots__ на лету преобразовывает внутренние элементы объекта из словаря в кортеж (tuple). Насчет кортежей важно помнить, что они не изменяются, то есть их значения изменить нельзя.
Если я создам класс Point и сделаю декларацию специального метода __slots__ для x и y, то теперь мы сможем создать только те атрибуты, которые были предусмотрены заранее.

Что случится, если мы попытаемся присвоить имя нашему классу Point. Мы увидим один из этих известных атрибутов, а в классе нет внутреннего метода __dict__. Получается, что я не могу создавать произвольные значения.
Это важно, потому что если мы воспользуемся функцией getsizeof, то она вернет нам размеры внутренних элементов для встроенных типов данных (built-in data types).

Во внутренней части моего Python 3 размер слова составляет 232 байта, а размер кортежа всего лишь 40 байтов. Это не очень большая разница для одного экземпляра, но масштаб может значительно вырасти, когда экземпляров будет много.
Когда лучше использовать метод __slots__. Например, при создании большого количества экземпляров класса, если заранее известно, какими свойствами должен обладать класс.
Есть очень хороший пост в блоге компании, которая создавала миллионы экземпляров определенного класса. Они моментально снизили потребление памяти на 9 Гб с помощью __slots__.
Важно отметить следующее. Они рекомендуют не спешить с оптимизацией и повсеместным использованием __slots__, потому что это сильно влияет на обслуживание кода.
Слабые ссылки (weak references)
Еще одна стратегия оптимизации кода для эффективного потребления памяти предусматривает использование слабых ссылок.
Если на объект ведет только слабая ссылка, то ее не достаточно для его сохранения. Если на объект ведут только слабые ссылки, то он может быть очищен при сборе мусора.
В каких сценариях полезны слабые ссылки. Они помогают вести кэш или хранить сопоставления для очень больших и затратных объектов, которые занимают много пространства и памяти.
Глобальный блок интерпретатора (global interpreter lock)
Он не позволяет нескольким потокам (threads) выполнять код Python одновременно. Для каждого интерпретатора предусмотрен один блок. Внутри интерпретатора в единицу времени может работать только один поток.

Другими словами, если две программы Python запускаются на одном компьютере, то у них нет общего блока интерпретатора.
Зачем Python нужен блок интерпретатора. Он предотвращает параллельное изменение подсчетов ссылок. Если два потока одновременно попытаются увеличить и уменьшить подсчет ссылок по одному объекту, то эти операции могут быть выполнены в не подходящем порядке. Такая ситуация может создать большую проблему.
Какие есть преимущества и недостатки у глобального блока интерпретатора?
С хорошей стороны, сбор мусора через подсчет ссылок выполняется быстро, и его легко реализовать. С плохой — независимо от количества потоков в программе Python в каждый момент выполняется только один поток.
Если есть желание воспользоваться мощностями нескольких ядер, нужно прибегать к помощи многопроцессорного выполнения (multi-processing), а не многопоточного (multi-threading).
В каждом процессе будет свой глобальный блок интерпретатора. Распределение информации между процессами осуществляется по усмотрению разработчика.
Различие между потоками и процессами не будет раскрываться во время данного выступления, но я очень рекомендую почитать на эту тему.
Получается, что глобальный блок интерпретатора ограничивает Python. Может быть, удалим его? Это хороший вопрос, и он вызывал определенные споры в сообществе Python на ранних этапах развития.
В версии 1.5 был добавлен патч для удаления блока глобального интерпретатора. Внимание, спойлер! Все закончилось плохо. Многопоточные приложения ускорились, это хорошо. С другой стороны, однопоточные приложения замедлились примерно на 50%.
Если эта тема вас заинтересовала, то можно проследить судьбу проекта Gilectomy Ларри Гастингса (Larry Hastings). По разным причинам его разработка не продвигается, но можно найти его выступления на PyCon 2016 и 2017.
В общем и целом, глобальный блок интерпретатора останется. Со времен того патча исходный код Python стал гораздо сложнее.
Кстати, не во всех реализациях Python есть глобальный блок интерпретатора, например в JSON и ironpython его нет.
Заключение и дополнительные материалы
Что мы узнали сегодня:
- сбор мусора хорошо подходит для большинства случаев
- алгоритм сбора мусора более-менее не подвержен ошибкам
- с помощью сбора мусора устраняется или облегчается устранение большого количества ошибок
- для большинства приложений с ним проще и понятнее, чем делать сбор мусора вручную в Си
- сбор мусора нельзя называть волшебной палочкой
- с его участием заметно удлиняется время выполнения и увеличивается занимаемое пространство
Мы охватили базовые концепции, и теперь можно продолжать обучение и саморазвитие. Это поможет писать более качественный и быстрый код.
Если вы еще не перешли на Python 3, то знайте, что в нем более эффективная и качественная реализация глобального блока интерпретатора. Это одна из многих причин перейти.
Для научных приложений пользуйтесь numpy и pandas. Эти пакеты оптимизированы для работы с большими структурами числовых данных и не страдают от некоторых из этих проблем.
В данном выступлении не было охвачено много тем, поэтому я рекомендую ознакомиться с дополнительными ресурсами.