Содержание
- Вступление
- Функции
- Взаимосовместимость (concurrency)
- Реализация взаимосовместимости
- Кооперативная многозадачность (cooperative multitasking)
- Генераторы (Generators)
- Сопрограммы (coroutines)
- Пример программы с кооперативной многозадачностью
- Сопрограммы со стандартной библиотекой Python
- Заключение
Вступление
Всем привет, я работаю с Лизой, с которой вы все познакомились вчера утром. У нас своя внутренняя команда разработчиков на Python, и мы стремимся сосредоточиться на создании инструментов и инфраструктуры для Python в Facebook. Также я стараюсь копаться во многих моментах, которые не обязательно всем интересны, но интересны мне лично. Мне нравится все узнавать.
Итак, 10 лет назад я получил степень инженера ПО в школе, которая была слишком дорогой и находилась в северной части штата Нью-Йорк, где было слишком холодно. Было много снега, поэтому, естественно, мне нравилось задавать вопросы, например, зачем я сюда приехал и сколько я должен.
Одна из причин, почему я люблю Python — это легкость поиска ответов на вопросы о том, как и почему все работает.
Итак, сопрограммы (coroutines). Это основа асинхронного программирования на Python и фундаментальный стройматериал инфраструктуры асинхронного ввода-вывода (async i/o). Но эти моменты тоже могут оказаться окружены большой тайной.
Что такое сопрограммы, как они работают, почему они так важны. Я сейчас дам небольшой спойлер насчет финального ответа. Давайте посмотрим, что говорит источник всей правды и знаний в Интернете.
Википедия пишет, что сопрограммы – компоненты компьютерной программы, которые обобщают подпрограммы для реализации не вытесняющей многозадачности (non pre-emptive multitasking), позволяя приостанавливать и возобновлять исполнение.
Если среди слушателей есть роботы, то они наверное будут удовлетворены этим ответом. Постичь смысл этой фразы невозможно.
Давайте попробуем разбить ее на понятные человеку элементы. Сопрограмма – особый вид функции, которая реализует взаимосовместимость через кооперативную многозадачность. Мы изучим, откуда взялись сопрограммы, и разберемся, как они работают и зачем они нам нужны.
Придется охватить много важных концепций. Поэтому я сосредоточусь на базовых идеях, а затем на том, что лежит в их основе, и как это все соотносится с Python.
Функции
Начнем с самого начала. Что такое функция. На этот раз не буду тратить ваше время на то самое единственное правильное определение, так как мы все здесь сегодня люди, за исключением, может быть, вчерашнего бота skull.
Функция — последовательность инструкций, которая принимает входные данные и возвращает выходные данные. Практически любая полезная функция на любом языке программирования представляет собой фундаментальный строительный блок. Она позволяет организовать код во многоразовые компоненты, которые принимают входные данные, что-то делают с ними и выдают выходные данные.
def square(x: int) -> int:
return x * x
def main():
x = square(4)
print(x) # 16Мы можем исполнить функцию main(), и рабочая среда (runtime) проходит через все операторы, а дойдя до вызова функции, приостанавливает исполнение текущей функции, направляет входные данные вызываемой функции, исполняет тело данной функции, затем направляет выходные данные обратно вызывающему объекту и возобновляет исполнение исходной функции с того места, на котором вышла.
На данный момент все кажется достаточно простым, но есть много деталей, которые мы принимаем как должное. Можно пойти глубже.
Как вы, наверное, знаете, CPython использует виртуальную машину для исполнения наших программ. В нем есть замечательная утилита позволяющая заглянуть под покровы. Модуль dis, сокращенно от «дизассемблировать», может дать нам понятный для человека список скомпилированного байткода для каждой функции.
from dis import dis
print("square:")
dis(square)
print("main:")
dis(main)Данный байткод представляет собой точные инструкции, используемые виртуальной машиной или рабочей средой для исполнения нашего кода Python.
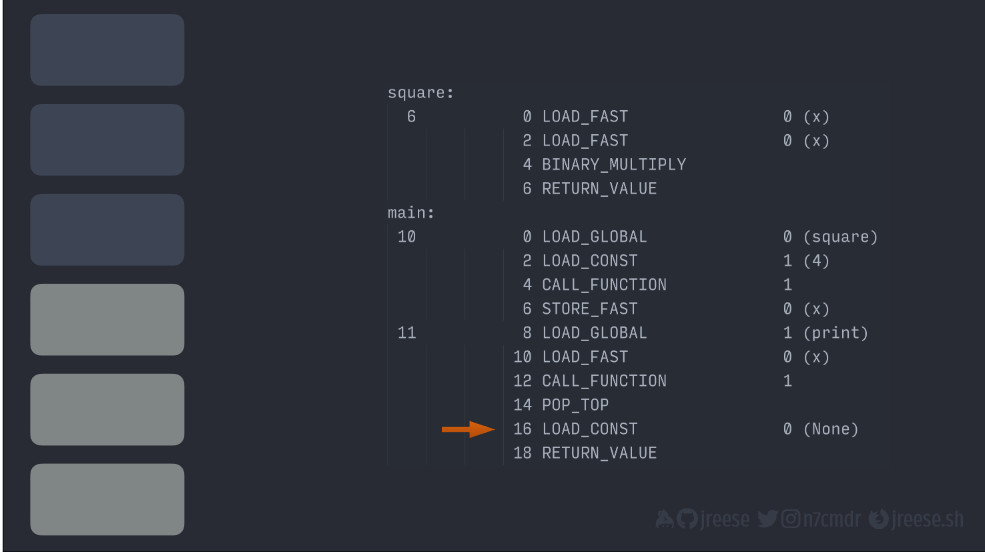
square:
6 0 LOAD_FAST 0 (x)
2 LOAD_FAST 0 (x)
4 BINARY_MULTIPLY
6 RETURN_VALUE
main:
10 0 LOAD_GLOBAL 0 (square)
2 LOAD_CONST 1 (4)
4 CALL_FUNCTION 1
6 STORE_FAST 0 (x)
11 8 LOAD_GLOBAL 1 (print)
10 LOAD_FAST 0 (x)
12 CALL_FUNCTION 1
14 POP_TOP
16 LOAD_CONST 0 (None)
18 RETURN_VALUEЭто выходные данные, которые мы получаем при дизассемблировании функций square() и main().
В данном виде уже выглядит сложнее, но если мы продолжим задавать вопросы и копать глубже, все начнет обретать смысл. Нам просто нужно понять контекст того, как функционирует рабочая среда.
Как вы, наверное, тоже знаете, рабочая среда CPython использует виртуальную машину на основе стека для исполнения инструкций. Нет регистров, которые можно встретить или использовать в программировании на ассемблере.
Если инструкциям нужны какие-то фрагменты данных, то эти данные нужно сначала поместить в стек. Сам по себе, стек – просто линейный блок памяти, содержащий данные или ссылки на них. Рабочая среда использует так называемый указатель стека, чтобы отслеживать местонахождеине вершины стека при исполнении инструкций.
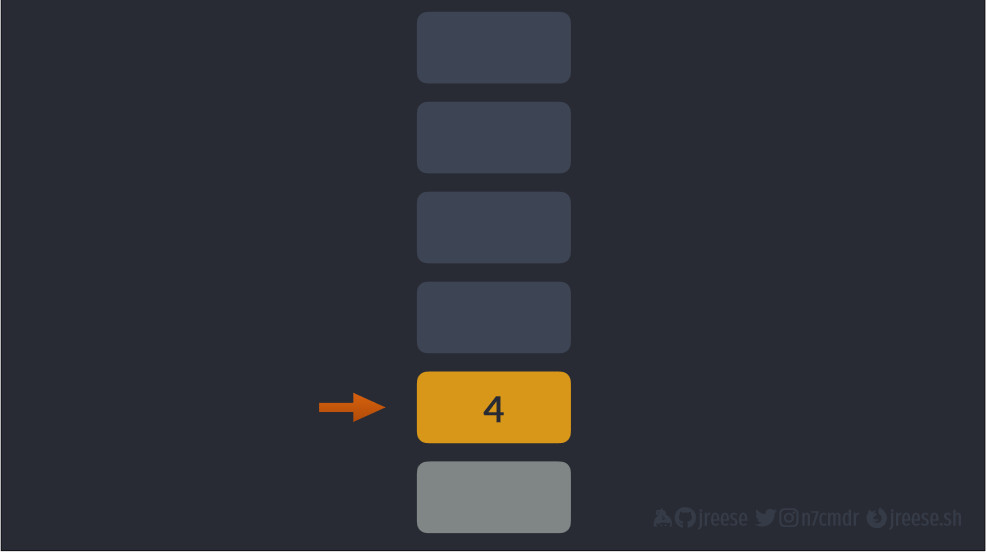
Можно помещать данные на вершину стека. Например, у инструкции LOAD_FAST задача одна: поместить одно значение в стек. Каждый раз, когда это происходит, указатель вершины стека поднимается, чтобы указывать на новую вершину стека.
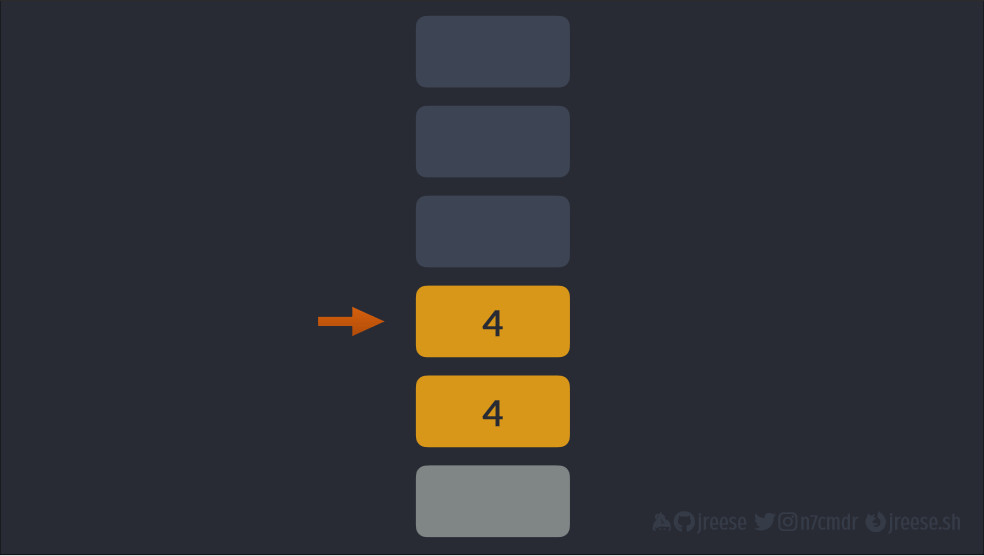
Другие инструкции могут затем потреблять (consume) или извлекать (pop) элементы из стека и даже добавлять новые элементы на вершину.
В то же время, например, математическая операция, скажем, умножение, извлекает из стека два верхних элемента. В результате указатель стека сбрасывается.
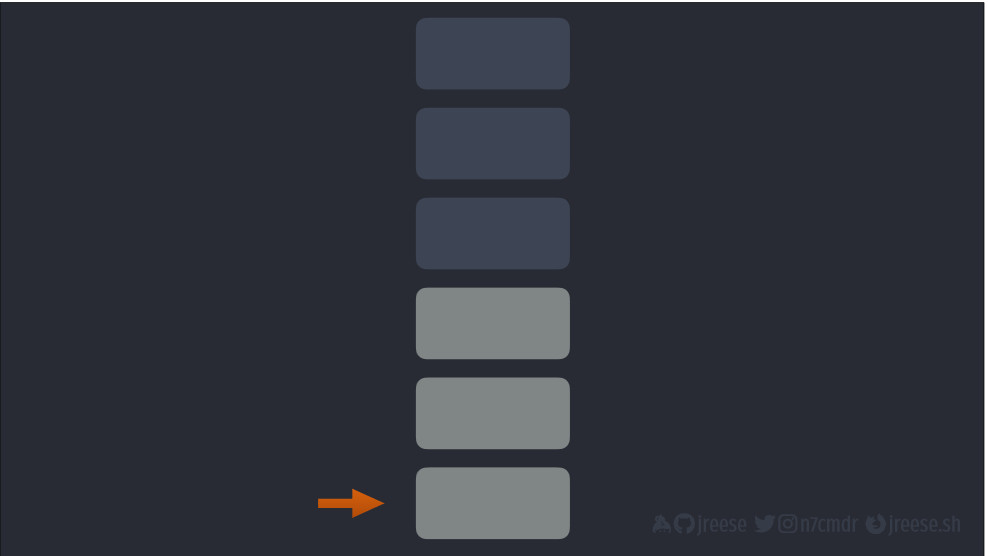
Затем она исполняет вычисление и помещает полученное значение обратно в стек для использования в будущих инструкциях.
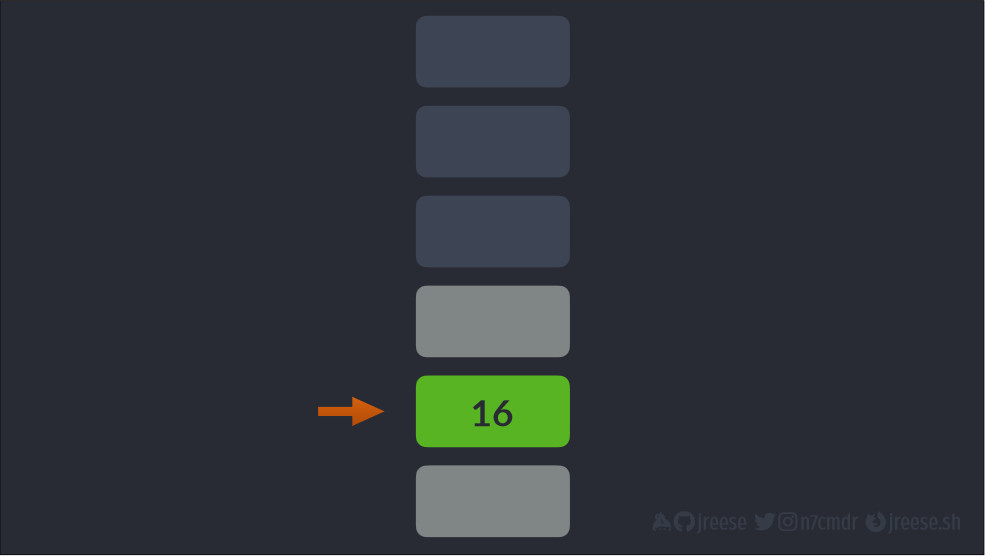
Но не все живет только в стеке. Данные, которые переживают создавшую их функцию, должны храниться в другом месте, чтобы не исчезнуть после возврата из функции.
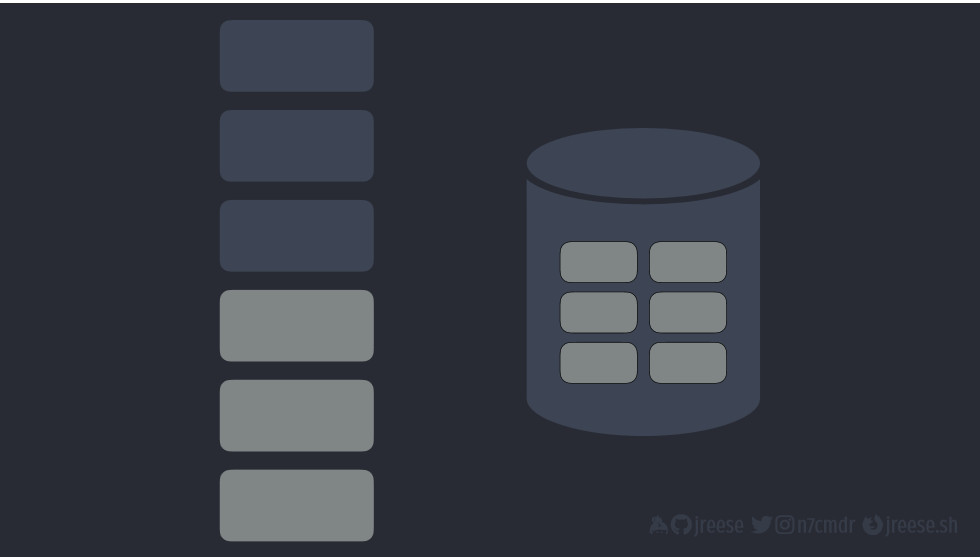
Поэтому, как и большинство языков, Python использует динамическую память (heap, "куча") для хранения объектов в долговременной памяти. В отличие от стека, это просто неупорядоченное пространство, в котором объекты могут быть выделены и освобождены в любой момент во время исполнения.
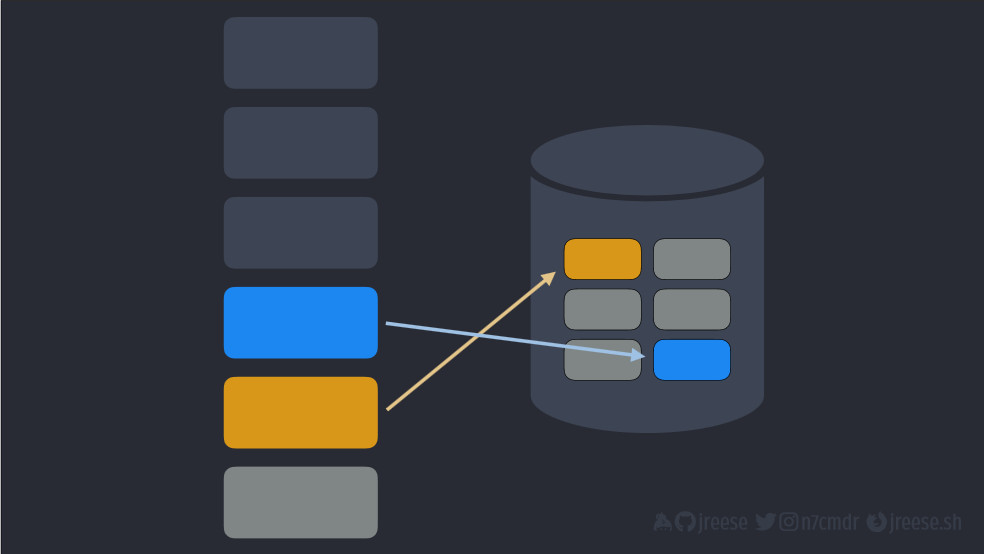
Часто элементы в стеке представляют собой просто ссылки на реальные объекты в куче. Но, опять-таки, сейчас нам менее важны конкретные детали, данная связь, чем понимание того, что она существуют.
Если мы вернемся к вышеприведенным дизассемблированным инструкциям, то сможем разобраться в том, что происходит при исполнении функции main().
square:
6 0 LOAD_FAST 0 (x)
2 LOAD_FAST 0 (x)
4 BINARY_MULTIPLY
6 RETURN_VALUE
main:
10 0 LOAD_GLOBAL 0 (square)
2 LOAD_CONST 1 (4)
4 CALL_FUNCTION 1
6 STORE_FAST 0 (x)
11 8 LOAD_GLOBAL 1 (print)
10 LOAD_FAST 0 (x)
12 CALL_FUNCTION 1
14 POP_TOP
16 LOAD_CONST 0 (None)
18 RETURN_VALUEКаждая строка представляет собой одну инструкцию для виртуальной машины CPython. Этот процесс немного похоже на инструкции в ассемблерном коде, но он разработан для идеализированной, но не настоящей архитектуры ЦП.
Если мы посмотрим на отдельную инструкцию, то увидим четыре части информации:
10 0 LOAD_GLOBAL 0 (square)- номер строки исходного кода (10), которая отображается группой инструкций;
- адрес инструкции (0) относительно вершины класса функции или модуля в зависимости от того, что дизассемблировано;
- код операции (LOAD_GLOBAL), который представляет собой конкретную операцию виртуальной машины на исполнение;
- числовой параметр (0 (square)) для операции, часто в виде исходного значения или индекса в некотором наборе данных, например в списке глобальных или локальных переменных; значение в скобках нужно только для того, чтобы мы, люди, знали, что представляет собой данный параметр.
Если сравнить это с нашим исходным кодом, то можно увидеть, как все это связано с функциональностью.
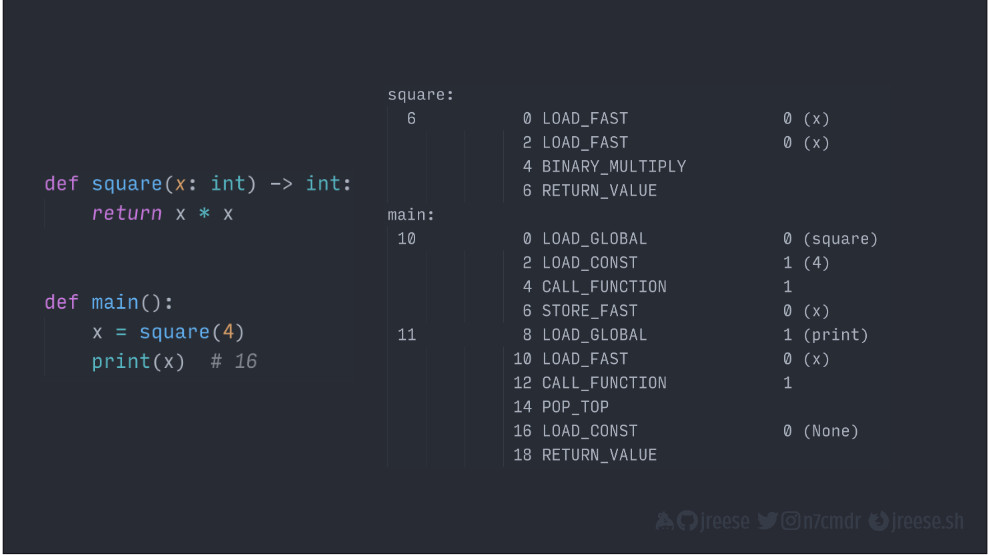
Эти инструкции исполняют умножение и возвращают результат:
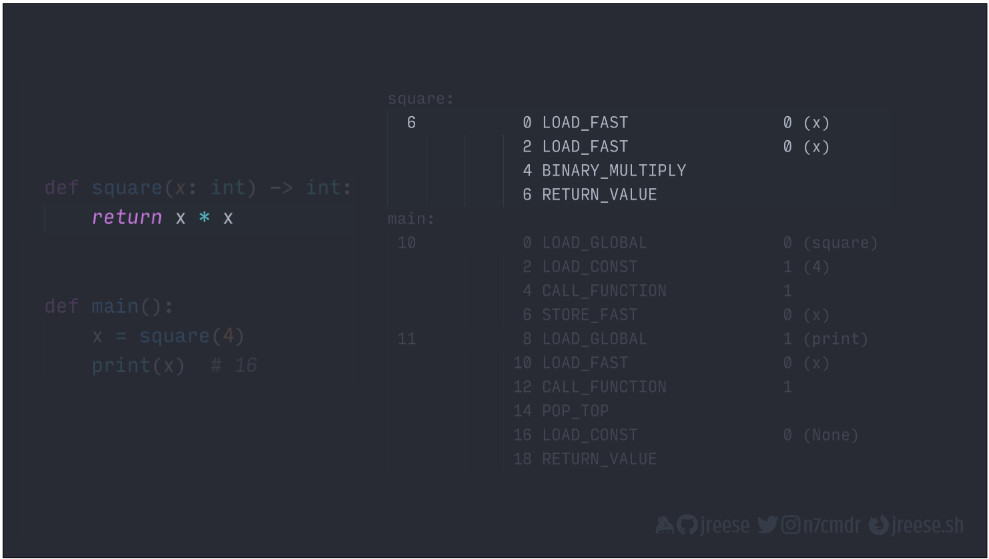
Эти инструкции вызывают функцию square() и сохраняют результат в X:

Эти выводят значение, хранящееся в X:
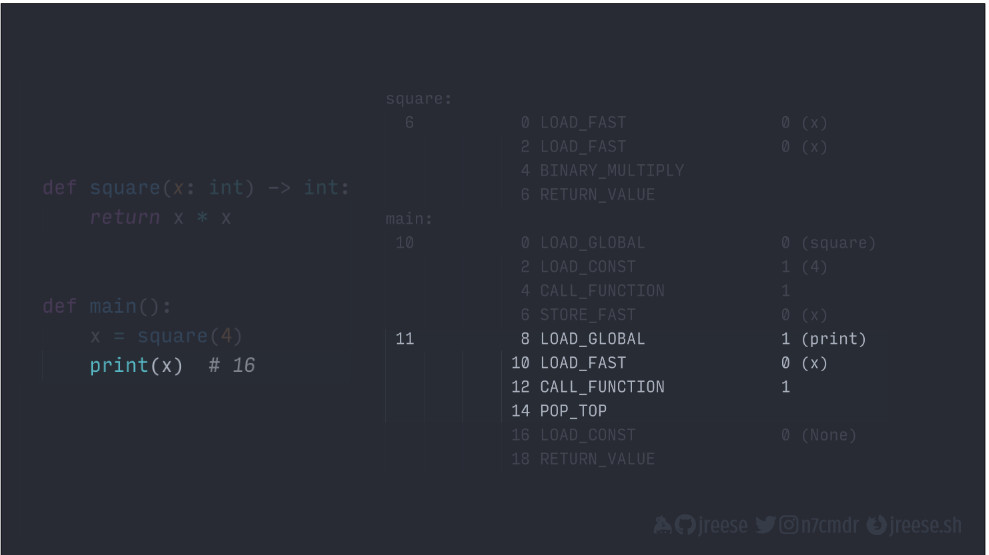
Наконец, эти последние две инструкции представляют собой неявный оператор возврата:
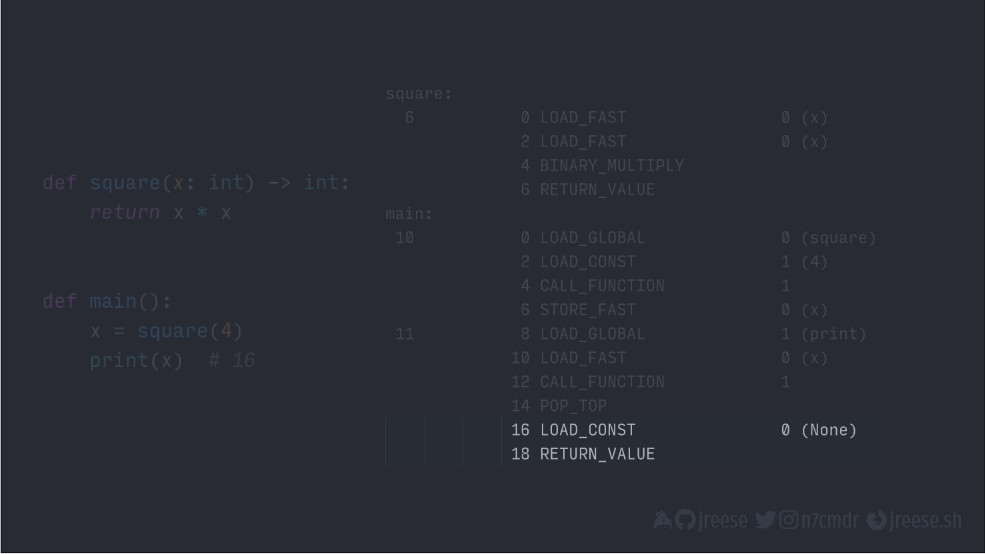
Теперь перейдем к тому, что при исполнении кода рабочей среде нужно отслеживать свое положение в наборе инструкций. Каждой инструкции выделяется заранее определенный зафиксированный объем памяти. Следовательно, у нее свой адрес в памяти. Рабочая среда будет просто отслеживать адрес в памяти для следующей инструкции, которую она должна исполнить.

Это — указатель инструкции.
Каждый раз, когда рабочая среда исполняет инструкцию, она автоматически переводит указатель инструкции на следующий шаг. Затем специальные инструкции могут менять указатель инструкции, позволяя рабочей среде переключаться между различными разделами кода.
Именно это лежит в основе управления последовательностью операций (flow control), в том числе условными блоками if-else, циклами for и while, а также вызовами функций.
Теперь давайте вернемся к прошлому стеку и концептуально рассмотрим, как все это может исполняться рабочей средой.

Сначала мы добавляем ссылку на функцию square(), которую мы хотим вызвать. Она находится в глобальном контексте (global scope).

Далее после каждой операции мы поднимаем указатель инструкции. Мы загружаем постоянное значение параметра (LOAD_CONST), который мы передаем нашей функции square().
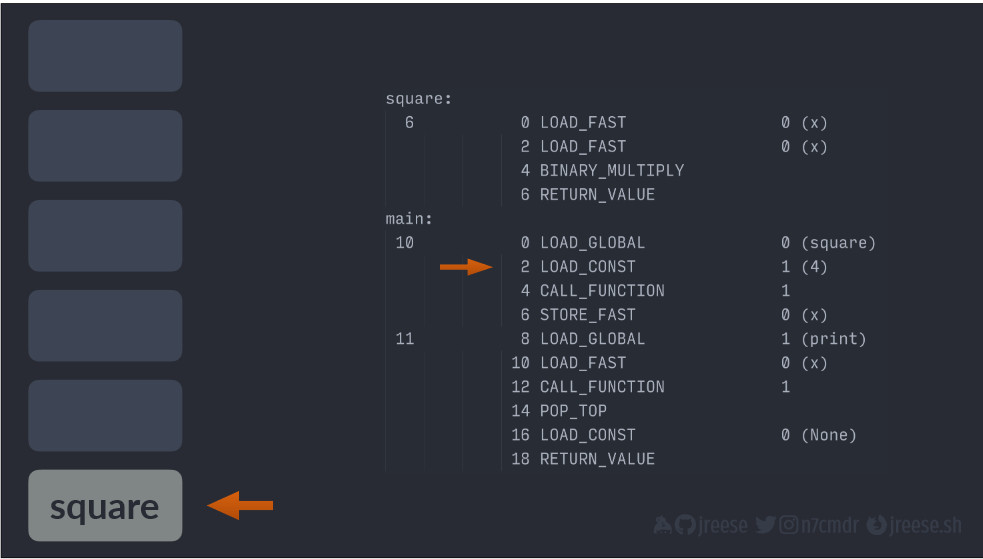
Теперь мы можем запустить операцию для реального вызова функции. Параметром данной инструкции является количество передаваемых нами аргументов, чтобы операция вызова функции (CALL_FUNCTION), знала, что нужно потребить данное количество элементов из стека, прежде чем искать функцию для вызова.

Параметры, которые она потребляет, будут затем использоваться для создания набора локальных переменных, доступных внутри данной функции.
После извлечения аргументов функции из стека и повышения указателя инструкции операция вызова функции теперь может извлечь саму ссылку на функцию и использовать значение для обновления позиции указателя инструкции, перемещая его в первый адрес данной функции, сохраняя при этом предыдущее значение указателя инструкции на стеке, чтобы мы знали, куда вернуться позже.
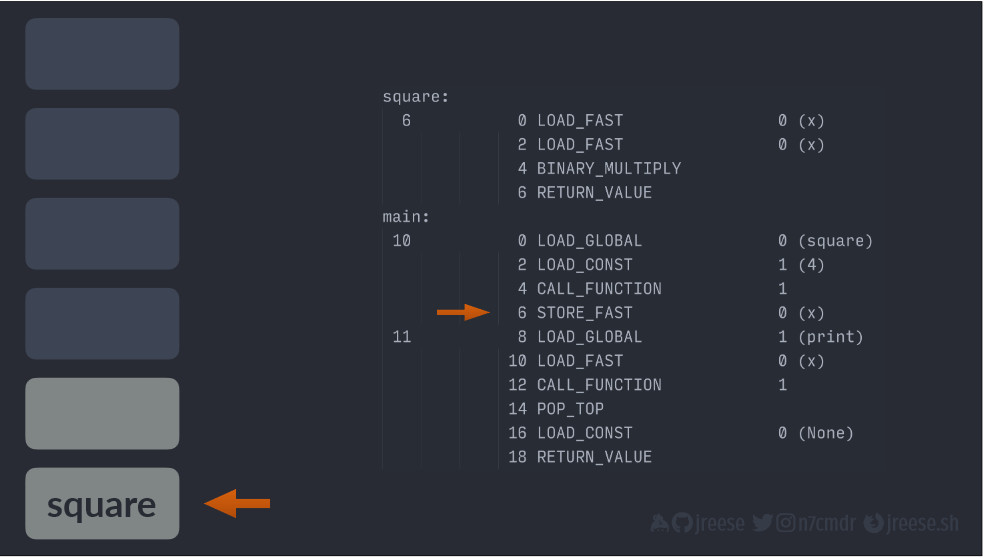
Теперь наше исполнение находится в функции square():

Первым делом мы загружаем X в стек, и, поскольку мы умножаем X на самого себя, то мы загружаем X в стек и второй раз.

Теперь мы можем по-настоящему умножить два значения между собой, и благодаря этому обе стороны умножения будут извлечены из стека. Четыре будет умножено на четыре, а полученное значение будет сохранено обратно в стек.

Теперь у нас есть результат, и мы готовы вернуть его вызывающему объекту.

Операция возврата значения извлекает результат из стека, затем восстанавливает указатель инструкции со следующим значением в стеке:

Далее она снова добавляет фактический результат обратно в стек:
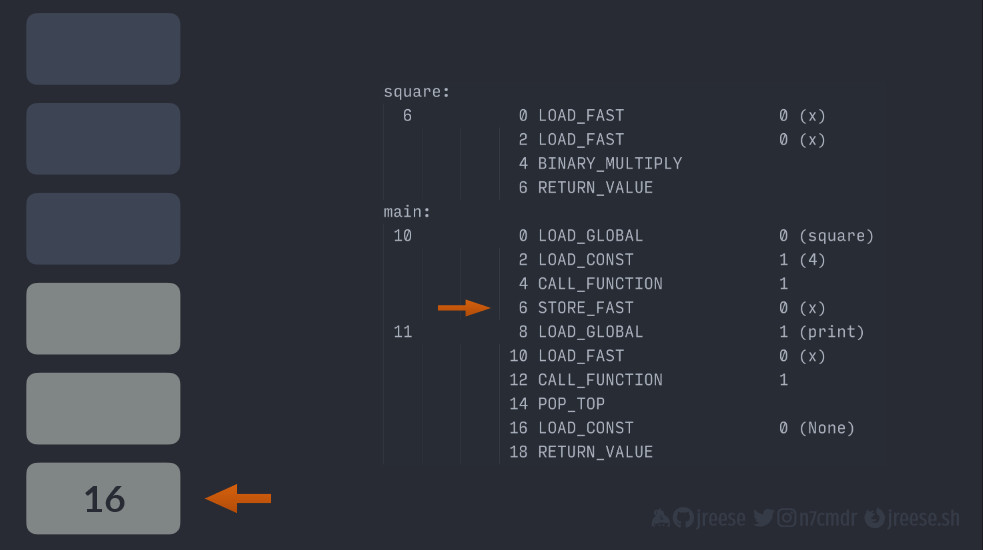
Мы вернулись к нашей функции main() с того места, на котором остановились, но с результатом функции square(), который остается на верхушке стека. Мы можем сохранить данное значение в локальной переменнойX.
Следующая строка кода должна вывести значение X. Поэтому мы добавляем ссылку на функцию print():

А затем ссылку на X благодаря стеку. Теперь мы снова исполняем операцию вызова функции (CALL_FUNCTION), и снова это будет с одним параметром, равным единице, так как в наличии только один аргумент.
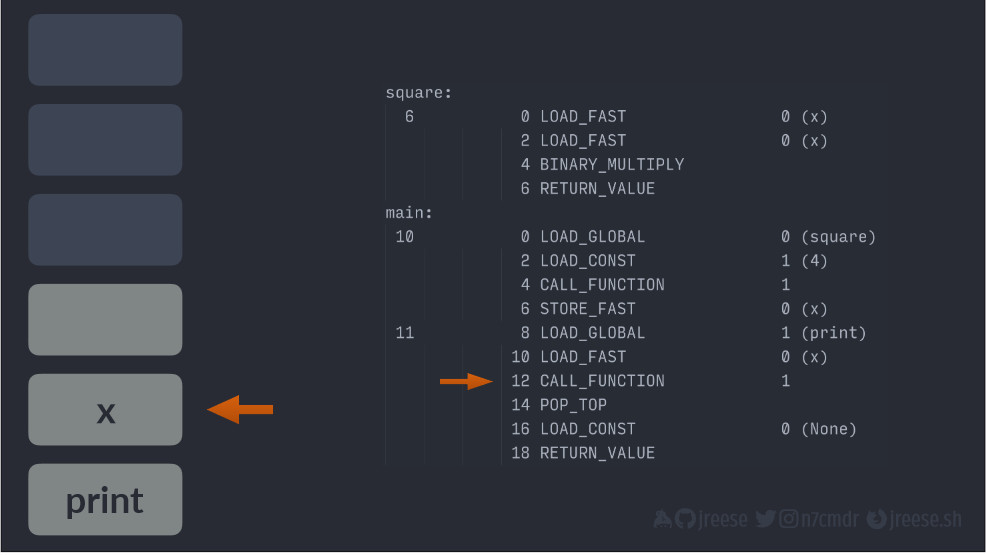
Благодаря этому ссылка на X будет потреблена и помещена в локальный контекст print. Затем снова ссылка на функцию извлекается, указатель инструкции обновляется, а в стеке сохраняется закладка для возврата из окна.
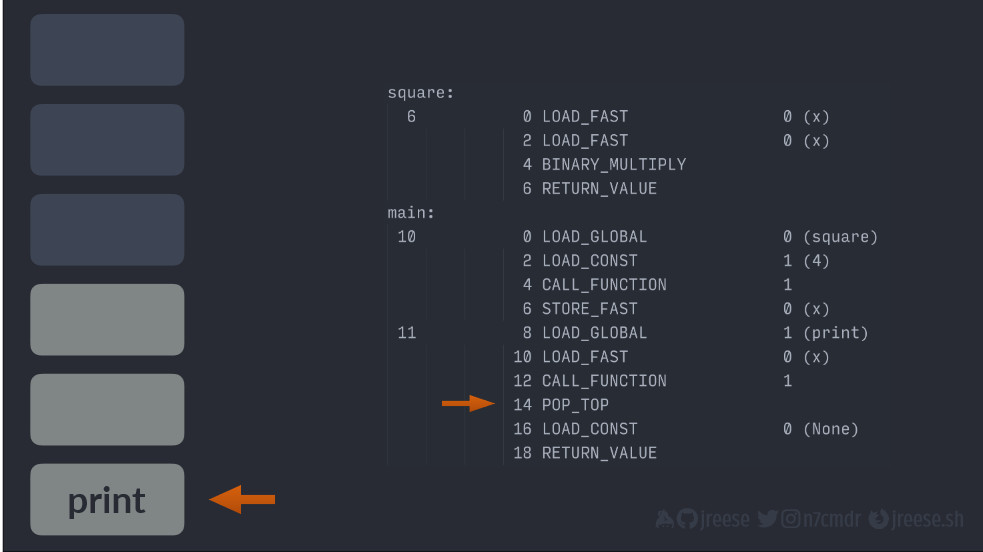
Теперь такой момент. Поскольку функция print() реализована на C, нет байт-кода, за которым мы могли бы следовать. По сути, исполнение будет происходить за пределами обычной виртуальной машины, но результаты все так же будут переноситься в стек при возврате.
Кроме того, поскольку у нас функция print(), при возврате мы получаем None.

Указатель инструкции снова там, где мы остановились. Но, так как мы не присваиваем никаких значений, следующая инструкция просто извлекает значение из стека и отбрасывает его.

Теперь, когда функция main() завершена, мы можем подготовиться к возврату неявного значения None, которое присваивается постоянной величине (LOAD_CONST), помещенной обратно в стек.
Получилось немного забавно, так как мы только что извлекли None из стека, но в ходе компиляции байт-кода не было возможности узнать это или рассчитывать на возможность повторного использования величины.
Наконец, мы можем вернуть управление той инструкции, которая находится в стеке под возвращаемым значением, и функция main() будет завершена.

На самом деле, наш стек – не просто горстка значений, а потенциально сотни или тысячи элементов в зависимости от того, насколько глубоким будет стек вызовов и насколько сложными становятся сигнатуры функций.
Сложные функции вполне могут содержать десятки или сотни инструкций. Приложение или сервис как единое целое может выходить за пределы сотни тысяч инструкций и иметь огромные стеки. При этом рабочая среда CPython должна все отслеживать.
Думаю, что для одних выходных байт-кода хватит, так что давайте поговорим о взаимосовместимости.
Взаимосовместимость (concurrency)
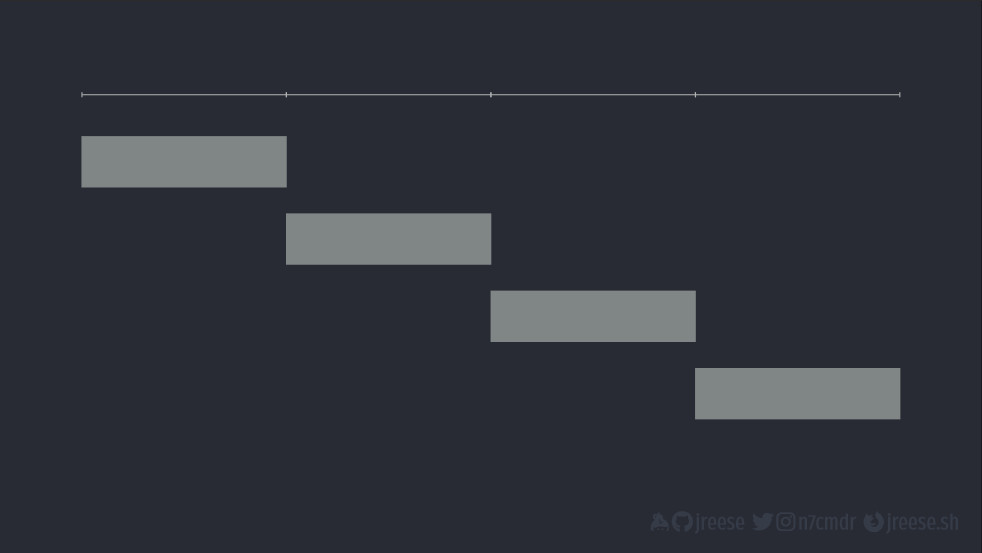
Это простая идея, но ее часто путают с другими концепциями. На самом базовом уровне взаимосовместимость заключается в исполнении нескольких задач. Задача может быть, в принцие, чем угодно. Изобразим задачу в виде полоски.

Представьте, что, исполняя задачу, мы двигались слева направо.
Но ни у кого никогда не бывает только одной задачи. У нас будет несколько задач, которые нам нужно исполнить, часто задач бывает на несколько порядков больше.

Наивное решение – просто обработать их по порядку. По завершении одной мы приступаем к следующей. Если у нас четыре задачи, для их исполнения требуется в четыре раза больше времени, чем на одну задачу.
Это все легко, имеет смысл и подходит для традиционных вычислений, но не так выглядит взаимосовместимость для многих реальных задач. Еще они похожи не на однородные блоки вычислений, а скорее вот на это с большими периодами простоя в ожидании чего-нибудь. Например, выборки данных с диска или исполнения сетевого запроса.

Если применить наш наивный метод и исполнять их последовательно, получится, что мы проводим много времени в бездействии. Все равно у нас уходит в четыре раза больше времени, чем на исполнение одной задачи.
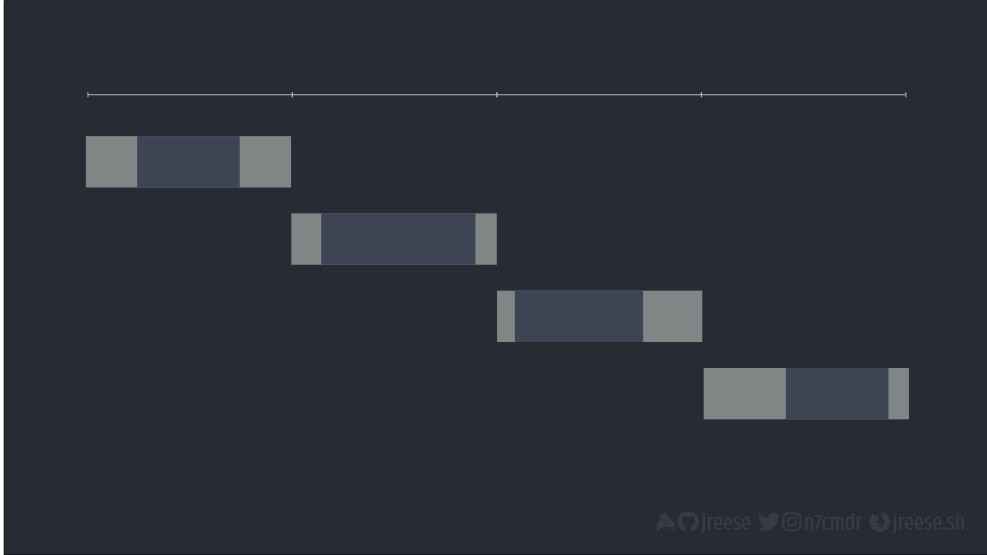
Вместо этого мы можем в полной мере воспользоваться моментами простоя, чтобы начать исполнение других задач.
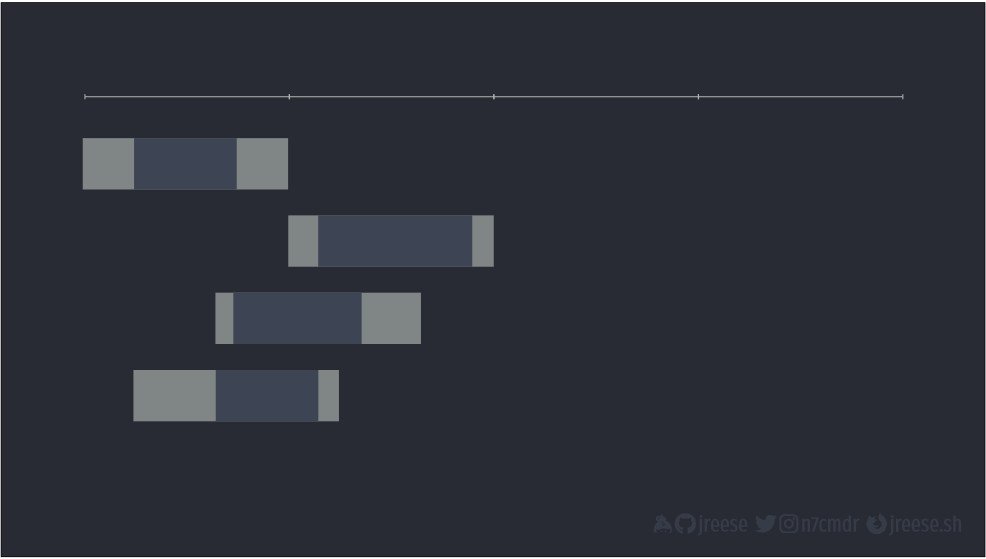
Мы можем исполнить все четыре задачи гораздо быстрее. Чем больше времени мы тратим на исполнение какой-то отдельной задачи, тем больше задач мы можем совмещать с ней для экономии времени.
В этом основной принцип и цель взаимосовместимости.
Реализация взаимосовместимости
Существует несколько различных стратегий для реализации взаимосовместимости.
Очевидный подход – несколько исполнителей (worker, "работник"). Каждый исполнитель мог бы обрабатывать одну задачу за раз.

Один из вариантов реализации – мультипроцессорная обработка (multiprocessing), где каждый процесс-исполнитель представляет собой отдельный процесс.
То есть, у каждого исполнителя есть своя рабочая среда CPython, свой стек, своя куча и свой набор скомпилированного байт-кода. Если мы хотим обрабатывать больше задач одновременно, мы просто добавляем больше исполнителей.
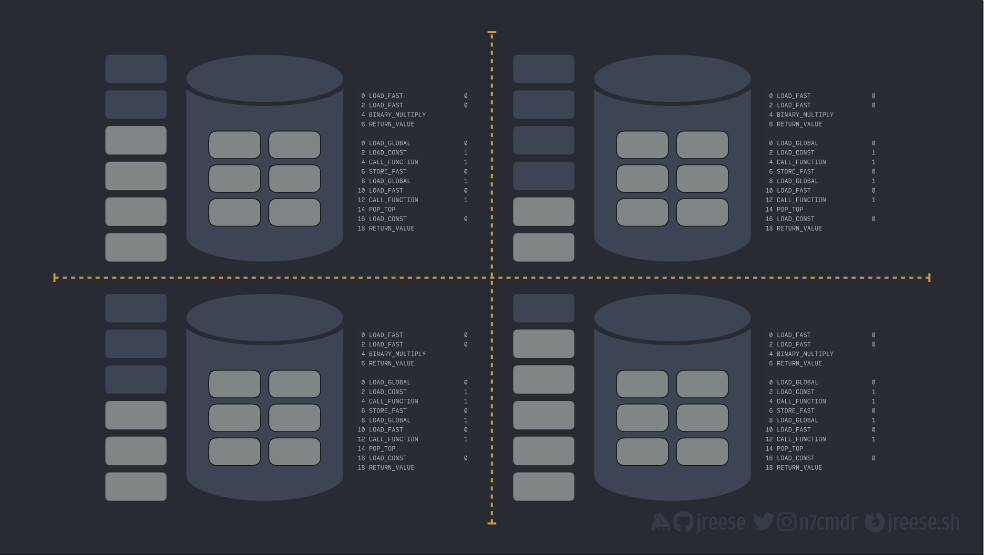
Но с этим вариантом связаны некоторые издержки. Конечно, прежде всего, это дублирование памяти, используемой для каждой рабочей среды. Во-вторых, любое взаимодействие между процессами должно происходить путем сериализации и десериализации данных, добавляя дополнительную работу для каждой задачи.
С положительной стороны это означает, что каждый исполнитель может обрабатывать задачи параллельно, обеспечивая для нас более высокий потенциал использования многозадачного курса.
Это — параллелизм (parallelism), младший и более популярный аналог взаимосовместимости.
Но, пусть даже общая пропускная способность обычно масштабируется с количеством исполнителей, каждый исполнитель и, следовательно, каждый процесс по-прежнему простаивает, пока задачи ожидают ресурсов.
Другой альтернативой является использование потоков (threads) для каждого исполнителя, а не процессов с одним исполнителем.
Мы начинаем с той же точки, что и с процессами, но на этот раз, когда мы добавляем больше исполнителей, нам нужно просто добавить новый стек вызовов для каждого потока, уменьшая дублирование куч и байт-кода.
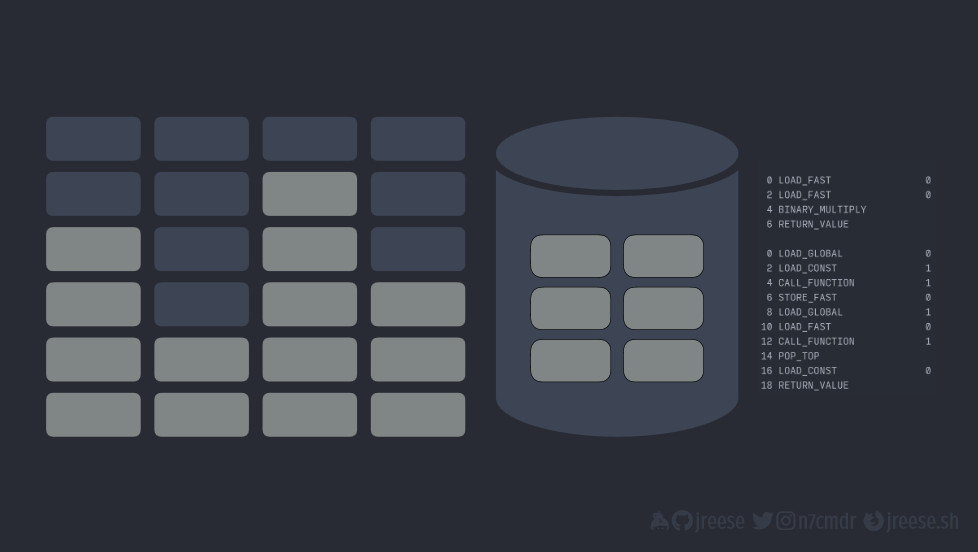
Благодаря этому также устраняется необходимость в сериализации данных между исполнителями, так как теперь все они используют один и тот же объем памяти.
Но, как всегда, данный вариант создает свои издержки и компромиссы вследствие уникального метода разработки CPython.
У нас есть хороший друг "Глобальный блок интерпретатора" (Global Interpreter Lock, GIL). Мы не можем запускать несколько потоков кода Python одновременно, поэтому все остальные потоки должны бездействовать и ждать своей очереди, пока исполняется текущий поток.
Кроме того, рабочая среда отвечает за планирование потоков, не имея представления о том, что они делают. Каждый раз, когда выбирается новый поток, мы должны ждать влекущего свои издержки переключения контактов, которое включает в себя сохранение стека исполнения предыдущего потока и восстановление состояния для нового.
Именно это известно как вытесняющая многозадачность (pre-emptive multitasking). Она гарантирует справедливый доступ к ЦП и упрощает полное использование отдельного ядра ЦП несколькими потоками.

Но здесь повышается вероятность того, что мы будем переключать потоки в неподходящее время. Именно это причиной неоптимального поведения, например, задержки при запуске сетевых запросов.
Это может значительно увеличить время отдельной задачи, как, например, у верхней задачи из четырех вышеприведенных, исполнение которой занимает в два раза больше времени, чем следовало бы.
Возможно, это пример самого плохого сценария. Но, в любом случае, чем больше потоков, тем чаще происходит переключение контекста. Это повышает вероятность того, что ваши задачи будут прерваны в критические моменты.
Так что, и многопроцессорность, и многопоточность имеют разные преимущества и недостатки, но никто из них не приближается к вот этой идеальной форме параллелизма, которую я показывал раньше.

Кооперативная многозадачность (cooperative multitasking)
На самом деле, мы хотим получить систему, в которой задачи могут проходить через свои критические фазы и переключаться на следующую задачу только тогда, когда они ожидают внешних ресурсов. Это — кооперативная многозадачность (cooperative multitasking), простая форма взаимосовместимости без больших издержек.
Компромисс заключается в том, есть зависимость от хороших манер каждой задачи и ее кооперации со всеми остальными задачами для совместного использования времени ЦП и общих ресурсов. Но в приложении, где мы контролируем все, это может дать большие преимущества.
На практике это означает, что каждая задача должна либо завершиться, либо явно передать контроль, прежде чем сможет исполняться другая задача. Очевидный момент для передачи управления: когда задача ожидает внешних ресурсов, ведь других действий у нее пока нет.

Когда мы получим от задачи контроль на данном уровне, то сможем планировать более оптимально, сможем лучше использовать ресурсы и запускать все задачи в одном потоке и в одном процессе. Поэтому у нас будет только один общий стек вызовов и одна общая куча.

Так что если мы думаем о том, как создать подобные кооперирующиеся задачи, то можно найти несколько простых решений.
Одним из них может стать создание задач, которые следуют простому шаблону: по возможности продвигаются, по возможности прогрессируют, выдают (yield), когда это не удается, и, в конечном итоге, завершаются и возвращают.
Если бы мы хотели реализовать нечто подобное в каком-нибудь наивном коде Python, мы могли бы начать с чего-то вроде этого:
class Task:
def __init__(self):
self.ready = False
self.result = NoResult
def run(self) -> None:
raise NotImplementedErrorМы просто исполняем метод run() несколько раз и рассчитываем, что в конечном итоге у него будет возврат (return) или выдача (yield) в тот момент, когда это наиболее удобно для отдельных задач.
В какой-то момент метод установит для атрибута ready значение True. Тогда мы сможем проверить результат на предмет конечного значения переменной.
Еще мы можем реализовать что-нибудь совсем бесполезное само по себе, например задачу Sleep с заданной продолжительностью и конечным значением.
class Sleep(Task):
def __init__(self, duration, result=None):
super().__init__()
self.threshold = time.time() + duration
self.result = result
def run(self):
now = time.time()
if now >= self.threshold:
self.ready = TrueПри каждом запуске данная задача проверяет время. Когда пройдет достаточно времени, она помечает себя как завершенную, указывая на то, что результат стал доступен.
Но сама по себе задача бесполезна. Нам нужно что-нибудь, что будет исполнять много задач одновременно. Нам нужен цикл с ожиданием событий (event loop).
def wait(ts: Iterable[Task]) -> List[Any]:
orig: List[Task] = list(ts)
pending: Set[Task] = set(orig)
before = time.time()
while pending:
for task in list(pending):
task.run()
if task.ready:
pending.remove(task)
print(f"duration = {time.time() - before:.3}")
return [task.result for task in orig]Мы будем использовать это как основу для исполнения задач. Она берет список объектов задач и многократно вызывает метод run() для ожидающих задач, когда каждая задача помечает себя как завершенную.
Цикл событий в конечном итоге будет исполнять меньше задач на каждой итерации. После завершения всех задач он возвращает список конечных результатов.
Теперь, раз мы создаем несколько задач, в данном случае спящие случайный объем времени, мы можем запустить для них цикл событий. Цикл завершит все 10 задач, а результаты вернутся, когда самая долгая задача будет окончательно завершена.
def main():
tasks = [Sleep(randint(1, 3)) for _ in range(10)]
wait(tasks)
tasks = [Sleep(randint(1, 3)) for _ in range(1000)]
wait(tasks)Если мы дадим ему тысячу таких задач, даже этот наивный цикл событий все равно сможет завершить их быстрее, чем могло бы потребоваться для запуска run() и компиляции результатов из тысячи потоков или тысячи процессов.
Но данная реализация Task не идеальна. В лучшем случае каждая задача должна вручную отслеживать свой прогресс, и каждая задача должна создавать свой метод run(), чтобы каждый раз запускаться сначала.
Наш фреймворк также не предлагает задачам легкий способ для вызова других функций, которым также может потребоваться подождать своих ресурсов.
Хорошо бы у нас был способ написать какой-нибудь код, который мог бы выдавать (yield) несколько значений с течением времени и иметь возможность начать исполнение с того места, где ранее произошла остановка. Некоторые из вас, возможно, уже поняли, к чему я веду.
Генераторы (Generators)
Генераторы идеально подходят под данное описание. Давайте посмотрим, как они работают.
Последовательность Фибоначчи — один из основных примеров генераторов и концептуально проста. Каждый раз по ходу цикла мы складываем два предыдущих числа и выдаем значение. В результате чего получается последовательность 1 1 2 3 5 и так далее.
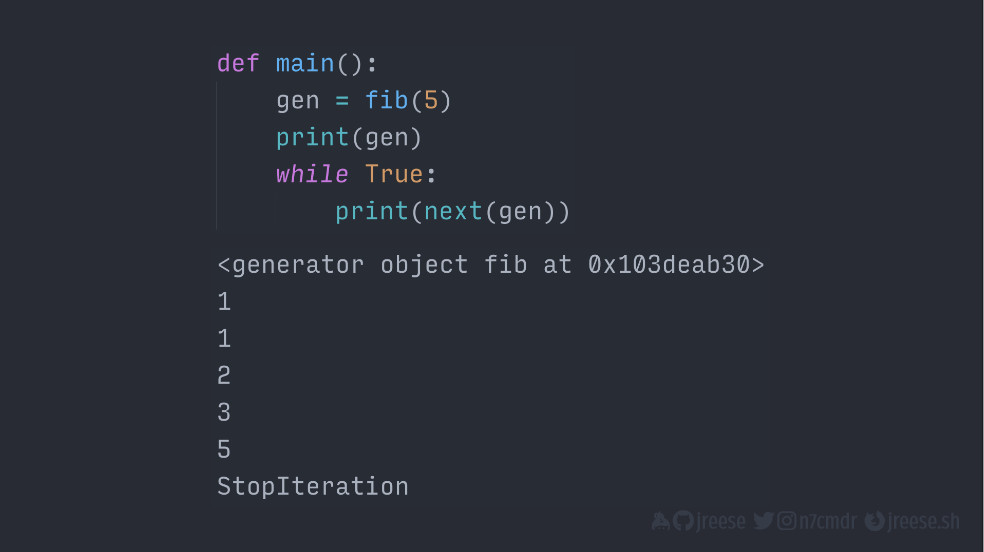
def fib(count: int):
a, b = 1, 0
for _ in range(count):
a, b = b, a + b
yield bНо когда мы вызываем данную функцию, мы не получаем ни одного из данных значений напрямую. Вместо это мы на самом деле получаем объект-генератор.
Вот скомпилированная версия нашей функции генератора. Фактический код, внутренняя функция даже не начала исполняться, но по объекту-генератору можно проводить итерацию, совсем как по списку.
def main():
gen = fib(5)
print(gen)
while True:
print(next(gen))Cтандартную функцию next() из стандартной библиотеки можно использовать для итерации только один раз.
Каждый раз, когда мы вызываем next() для своего объекта-генератора, он повторно входит в функцию на том месте, где остановился с полным сохранением состояния. И, если функция выдает другое значение, мы получаем данное значение как результат или возвращаемое значение от вызова next().
Когда функция генератора завершается или возвращает, объект-генератор поднимает значение остановки итерации StopIteration, как и любой другой итератор, когда вы достигнете его конца.
Довольно часто встречаются генераторы, которые выдают значения, но еще могут передавать или направлять значения обратно в генератор извне. Когда это происходит после передачи исполнения в функцию генератора, оператор yield сам дает значение, которое было направлено в генератор.
import time
from random import randint
from typing import Generator, Any, List, Iterable
NoResult = object()
## Направляем значения в генератор
def counter(start = 0, limit = 10):
value = start
while value < limit:
value += yield value
yield value
def main():
gen = counter()
gen.send(None) # первое значение для генератора
while True:
value = randint(1, 3)
total = gen.send(value)
print(f"sent {value}, got {total}")
if __name__ == "__main__":
try:
main()
except Exception as e:
passДля этого нам нужно заменить функцию next() методом send() для генераторов. Благодаря этому функция исполняется с того места, где она остановилась. Как и с next(), будут возвращаться все выданные значения генератора, пока функция не будет запущена по-настоящему.
Несмотря на то, что после этого можно направить только None, мы можем и дальше направлять и получать значения, пока генератор не завершится.
Ура, мы только что нашли сопрограммы (coroutines). Python годами прятал их на виду у всех.
Сопрограммы (coroutines)
Как в реальности использовать все это для исполнения параллельных задач. Оказывается, мы можем адаптировать наш цикл с ожиданием событий и улучшить его по ходу дела.
Как он выгядел:
def wait(ts: Iterable[Task]) -> List[Any]:
orig: List[Task] = list(ts)
pending: Set[Task] = set(orig)
before = time.time()
while pending:
for task in list(pending):
task.run()
if task.ready:
pending.remove(task)
print(f"duration = {time.time() - before:.3}")
return [task.result for task in orig]Как он будет выглядеть:
def wait(tasks: Iterable[Generator]) -> List[Any]:
pending = list(tasks)
tasks = {task: None for task in pending}
before = time.time()
while pending:
for gen in pending:
try:
tasks[gen] = gen.send(tasks[gen])
except StopIteration as e:
tasks[gen] = e.args[0]
pending.remove(gen)
print(f"duration = {time.time() - before:.3}")
return list(tasks.values())Вместо вызова метода run() для каждой задачи мы вызываем метод send() для каждого объекта генератора. Вместо того, чтобы искать флаг, мы перехватываем ошибку StopIteration и помечаем данные генераторы или задачи как завершенные.
Начиная с Python 3.3, StopIteration содержит значение, возвращаемое данными генераторами. Поэтому мы сохраняем их для добавления в конечный результат.
Наконец, мы также захватываем промежуточные выданные (yielded) значения и направляем их обратно на следующей итерации, что позволяет сопрограммам вызывать другие сопрограммы. То есть, теперь мы можем получать выдачу из другой сопрограммы, чтобы вызывать ее, и наша позиция в стеке вызовов сопрограмм будет сохраняться при всех выдачах.
В общем итоге наше использование сопрограмм становится более похожим на обычные функции.
def sleep(duration: float):
now = time.time()
threshold = now + duration
while now < threshold:
yield
now = time.time()
def bar():
yield from sleep(0.1)
return 123
def foo():
value = yield from bar()
return value
Но они по-прежнему уступают контроль на своих условиях и могут продолжить с того места, на котором остановились, когда снова придет их очередь.
Поэтому, если мы создадим пару сопрограмм из нашей функции foo() и передадим их нашему циклу событий, он будет следовать за исполнением через foo() в bar(), а затем в сопрограмму sleep().
def main():
tasks = [foo(), foo()]
print(wait(tasks))Там он будет и дальше делать выдачи обратно в цикл событий, пока не истечет время. Затем на следующей итерации через возврат контроля в bar, который возвращает значение обратно в foo, который, наконец, завершается и возвращает значение.
Уточню, что при каждой выдаче наш цикл с ожиданием событий циклически переходит к следующей ожидающей задаче, что дает нам кооперативную многозадачность, которую мы искали.
Пример программы с кооперативной многозадачностью
Теперь давайте сделаем что-нибудь более полезное, например, загрузим контент c нескольких URL-адресов.
Мы напишем сопрограмму fetch(), которая инициирует соединение для одного URL, и сопрограмму read(), которая отправляет в буфер данные из этого подключения по мере их доступности. Это делается через выдачу из сопрограммы read() после прочтения каждого фрагмента. Благодаря этому другие задачи могут исполняться, пока ожидается поступление новых данных.
import time
from random import randint
from typing import Generator, Any, List, Iterable
from requests import get, Response
# reuse wait() from part 5
wait = __import__("5-generator-coroutines").wait
SIZE = 1024
URLS = [
"https://2019.northbaypython.org",
"https://duckduckgo.com",
"https://jreese.sh",
"https://news.ycombinator.com",
"https://python.org",
]
def read(r: Response) -> bytes:
data = b""
for chunk in r.iter_content(SIZE):
data += chunk
yield
return data
def fetch(url: str) -> str:
with get(url, stream=True) as r:
data = yield from read(r)
return data.decode("utf-8")
def main():
coros = [fetch(url) for url in URLS]
results = wait(coros)
for result in results:
print(f"{result[:20]!r}")
if __name__ == "__main__":
main()Затем мы вызовем fetch() несколько раз, чтобы создать сопрограммы генератора. Наш цикл событий будет запускать каждую из них и исполнять их одновременно, пока не завершатся все запросы. Тогда у нас будут необработанные данные ответа для каждого запроса, и мы сможем поступать с ними по своему усмотрению.
Снова ура, вы только что изобрели асинхронный ввод-вывод (async i/o). То, что мы получили, на самом деле является очень примитивной версией асинхронного ввода-вывода с использованием того же синтаксиса, который был доступен в Python 3.4.
Но у нас пока нет абсолютно никаких наворотов.
Отмечу, что данный пример кода был информативным, и с ним было весело поиграться. Но он не очень гибкий и не будет полезным, если мы используем его с библиотеками, которые для него не предназначены. Поэтому очень прошу вас не использовать вот это все в продуктиве. Ведь неспроста этот код не выложили на PyPI.
Сопрограммы со стандартной библиотекой Python
Итак, теперь, когда мы поняли процесс создания сопрограмм из различных функций Python, давайте посмотрим, как реализована поддержка сопрограмм непосредственно в Python.
Начиная с версии 3.5, стандартная библиотека поддерживает синтаксис async def для декларирования нативных сопрограмм наподобие наших игрушечных сопрограмм-генераторов.
async def foo ():
return 37Это уже не стандартная функция, которая исполняется сразу после вызова. Если вызвать ее, то будет возвращен объект сопрограммы, который затем можно запускать в цикле событий.
result = asyncio.run(coroutine)Данный цикл событий создается, среди прочего, фреймворком асинхронного ввода-вывода и исполняет задачи циклически, как и наша функция wait().
Мы используем нового помощника из Python 3.7, который создаст цикл, исполняющий нашу сопрограмму, а затем закроет цикл событий, когда сопрограмма завершится.
Давайте попробуем. Мы вызываем функцию сопрограммы foo(), выводим данный объект через print(), затем запускаем сопрограмму в цикле событий, получаем результат и выводим его.
После завершения мы увидим сам объект сопрограммы, который мы получили при вызове foo(). Он начнет исполняться только после того как мы передадим его в asyncio.run(), запущенный внутри сопрограмм.
Еще нам стала доступна новая сила — способность ожидать объекты.
await asyncio.sleep(delay: float)Она немного похожа на то, как мы использовали сопрограммы-генераторы. Но в целом она лучше, в данном примере asyncio.sleep() исполняет ту же роль, что и наш генератор sleep.
Так создается простой способ передачи управления циклом событий, причем задержка при передаче равна нулю.
Но на самом деле у нас еще больше возможностей. Нам не обязательно ждать только другие сопрограммы, мы можем ожидать самые разные асинхронные объекты, в том числе объекты ожидания (awaitables) и фьючерсы (futures).
Данная гибкость упрощает совмещение синхронных библиотек старого стиля с базами асинхронного кода, а также дает нам более выразительные формы для встраивания параллелизма в приложения.
Итак, возьмем наши сопрограммы, которые мы сделали в начале. Мы можем вызывать и ожидать сопрограмму sleepy(). Сама sleepy() может что-то делать, ждать чего-то другого и в конечном итоге возвращать значение.
async def sleepy(duration: float):
print("sleeping...")
await asyncio.sleep(duration)
return 37
async def foo():
value = await sleepy(1.0)
return valueДанное значение затем возвращается благодаря ключевому слову await в foo() и может использоваться традиционными способами.
Одним из распространенных рабочих процессов в параллельном программировании является создание нескольких подзадач.
Если мы просто используем ключевое слово await напрямую на каждой задаче по порядку, мы не получим никакого параллелизма.
Вместо этого, если мы хотим ожидать несколько вещей одновременно и фактически запускать их одновременно, нам нужно использовать помощника asyncio.gather().
results = await asyncio.gather(*futures)Он берет несколько сопрограмм-фьючерсов или объектов ожидания, продвигает их в задачи и запускает их одновременно. В конечном итоге он возвращает результаты в том же порядке, в котором они были даны. Это прямой эквивалент в асинхронном вводе-выводе для нашей функции wait() из начала.
Еще у нас есть есть поддержка для асинхронных итерируемых объектов и менеджеров контекста.
async for value in iterable:
pass
async with context as c:
passАсинхронные итерируемые объекты похожи на стандартные, но используют сопрограммы для извлечения следующего элемента.
Аналогичным образом асинхронные менеджеры контекста используют сопрограммы вместо традиционных функций при входе в контекст и выходе из него.
Наконец, у нас есть поддержка асинхронных генераторов.
async def agen(x):
for i in range(x):
yield i
async for v in agen(37):
print(v)Они построены на основе генераторов и сопрограмм, чтобы дать нам, как вы уже догадались, больше генераторов. На самом деле, они представляют собой асинхронные итерируемые объекты. Благодаря этому, они фантастически полезны для создания выразительных асинхронных интерфейсов без ущерба для удобочитаемости или сопровождения.
Итак, давайте объединим все это в одну финальную демонстрацию и создадим вариант извлечения URL с асинхронным вводом-выводом.
import asyncio
import time
from aiohttp import request
URLS = [
"https://2019.northbaypython.org",
"https://duckduckgo.com",
"https://jreese.sh",
"https://news.ycombinator.com",
"https://python.org",
]
# Сопрограммы с aiohttp
async def fetch(url: str) -> str:
async with request("GET", url) as r:
return await r.text("utf-8")
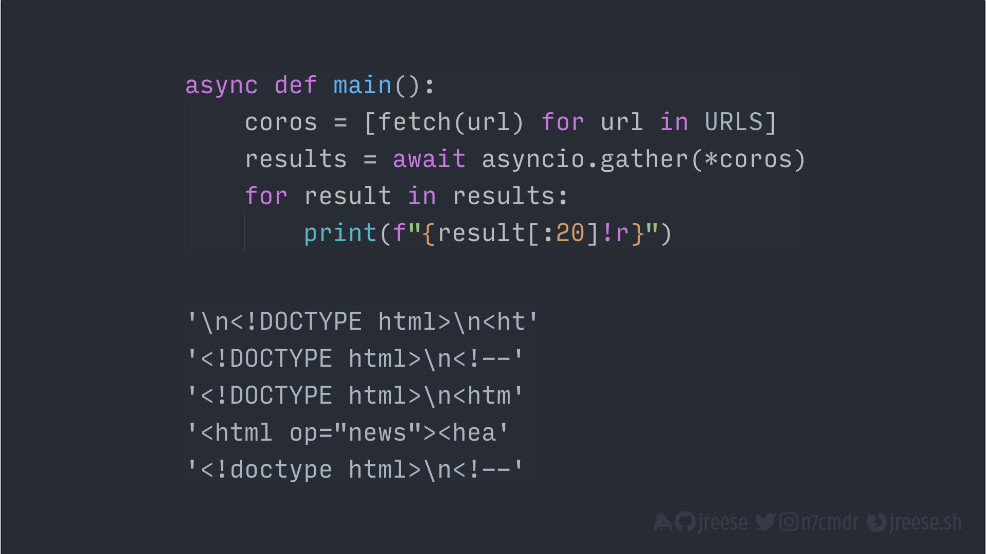
async def main():
coros = [fetch(url) for url in URLS]
results = await asyncio.gather(*coros)
for result in results:
print(f"{result[:20]!r}")
if __name__ == "__main__":
asyncio.run(main())В async def fetch() мы реализуем извлечение одного URL-адреса с использованием библиотеки aiohttp. Запрос создает для нас асинхронный контекст, который устанавливает соединение и дает нам объект ответа. Затем мы можем подождать метод text() и получить полное тело ответа от нашей основной сопрограммы.
В async def main() мы можем вызвать fetch() для каждого URL. Так мы получим список объектов сопрограмм.
Мы передадим их в asyncio.gather(), который будет исполнять каждую из них как параллельную задачу. Затем мы возьмем результаты ожидания gather и выведем ответы в консоль.
Когда мы запускаемся с помощью asyncio.run(), то увидим, что результаты соответствуют тем, что мы получили ранее с помощью сопрограмм-генераторов и настраиваемого цикла событий.
Заключение
Кооперативная многозадачность используется уже давно. Она даже была базовой функциональностью ранних версий Mac OS и Windows. Сопрограммы развиваются в Python более десяти лет. Async I/O как фреймворк в той или иной форме существует уже более шести лет.
Никакой магии здесь нет. Все, что мы видим, является результатом итеративной структуры и разработки на основе предыдущих функций или абстракций.
Просто нужно немного любопытства, чтобы продолжать чистить лук, расшифровать мотивы и понимать, как и почему принимались решения и как они повлияли на будущее.
Если вам понравилась какая-нибудь часть данного выступления, вам понравятся данные PEP:

Они на удивление хорошо читаются. Даже если вы уже знакомы с сопрограммами или Async I/O, готов поспорить, что вы узнаете что-то, что поможет вам или повлияет на решения, которые вы будете принимать в будущем. Возможно, в следующий раз, когда вы увидите, что кто-то работает с асинхронным вводом-выводом, вы наконец сможете сказать, что это сопрограмма.
Если вы хотите поиграть с какими-нибудь примерами кода, все они доступны в моем репозитории на github:
