Содержание
- Введение
- Пример из реальной жизни
- Базовый пример теста с патчем
- Пример из реальной жизни
- Вводные данные
- Программа для нашего примера
- Как будет выглядеть тест для нашего примера
- Возможные варианты традиционного рефакторинга
- Новый подход
- Немного истории
- Возражения против используемого подхода
- Мок-объекты — это не заглушки
- Рефакторинг теста для нашего примера
- Антишаблоны
- Контрафактное TDD
- Инверсия и блокировка
- Блоб
- Заключение
Введение
Когда меня одобрили на выступление, я, можно сказать, осознал, что стоит уделить немного больше времени этой теме как таковой. Поэтому как следует поразмыслил насчет других тем. В итоге мне показалось, что стоит начать с того, чтобы показать вам некоторые из вариантов тем выступления.

Так вот, мне кажется, что подошли бы все эти темы, причем каждая своим особенным образом. Думаю, самой любимой для меня будет использование нами мок-объектов, потому что данное выступление будет техническим. В то же время, оно частично будет своего рода ретроспективой некоторых наблюдений, сделанных мной вокруг вопроса о том, каким образом используются мок-объекты (mocks) в реальной жизни.
Поэтому в данном выступлении будет много личных мнений и умозрительных построений, а еще оно будет очень субъективным. Ну, если это еще не очевидно по списку тем на слайде. Поэтому надеюсь, что оно инициирует небольшую дискуссию и даст вам возможность подумать о различных способах использования мок-объектов и патчей (patch) в своих проектах.
Последняя тема, которую я хотел добавить "Mock Hell" (ад с мок-объектами), так уж вышло, не дожила до программы. На самом деле, она была добавлена благодаря замечанию одного моего коллеги. Она сказала, что я попал в ад с мок-объектами.
Данное выступление по своему уровню будет средне-продвинутым. У вас должен быть, как минимум, опыт работы с мок-объектами и патчами, опыт использования API для мок-объектов и патчей. Возможно, вы пока не очень хорошо разобрались, почему их использование причиняет иногда столько боли. Хотя, возможно, вы с комфортом пользуетесь мок-объектами, но вам хотелось бы посмотреть, какие еще есть варианты и мнения по этой теме.
Чему вы можете научиться:
- какие бывают стили блочного тестирования (unit testing) или проектирования на основе тестирования (Test-Driven Development, TDD),
- как на самом деле появились мок-объекты,
- какие есть альтернативы использованию мок-объектов,
- антишаблоны разработки,
- как между собой связаны мок-объекты и проектирование.
Я бы представил наш ад по аналогии со знаменитой поэмой Данте про девять кругов все более тяжелого ада:
1. На входе у нас комплексные целевые объекты-патчи. (Думаю, с этим сталкиваются все, причем первым делом изучают именно данный момент. В принципе, даже нельзя сказать, что это так уж плохо).
2. Многочисленные мок-объекты или патчи.
3. Мок-объекты с хрупкими утверждениями (assertions).
4. Мок-объекты с комплексными начальными установками.
5. Глубокие / рекурсивные мок-объекты; мок-объекты, которые возвращают другие мок-объекты.
6. Тесты, которые ничего не тестируют.
7. Вынужденное использование отладчика (debugger) для обратного проектирования мок-объектов.
8. Мок-объекты, которые мешают проводить рефакторинг.
Последние два пункта хуже всех. Если приходится использовать отладчика для обратного проектирования мок-объектов, чтобы просто разобраться в них, то у меня уже просто нет никакого желания заниматься рефакторингом кода. Ведь это закончится правкой десятков и десятков строк кода или даже файлов. Вот тогда мок-объекты и становятся тем самым техническим долгом (technical debt).
При виде всего этого я часто задавал себе вопрос, как же это так получается, что разработчики постоянно увязают во всех этих проблемах. Каким образом они учатся использовать мок-объекты, что приходят к такой ситуации. Ведь когда я сам пишу код, то редко пользуюсь мок-объектами или патчами, поэтому таких проблем у меня не бывает.
Тогда я начал читать много книг и блогов. Просто пытался разобраться во всем этом. Знаете, мне кажется, что, когда возникает необходимость внедрять мок-объекты, многие просто осматриваются вокруг, находят какой-нибудь блог или даже книгу, либо смотрят видеоролики. Они узнают, что есть такая библиотека Mock, она очень крутая. Ее можно использовать, чтобы изолировать тестовый код. Именно в этом месте удобно использовать "магические" объекты MagicMock, patch, spec, autospec, side_effect и т.д.
Базовый пример теста с патчем
По поводу патчей есть одна хитрость. Нужно следить за тем, чтобы патч был нацелен на правильное пространство имен. Обычно используют такой пример: у нас есть какой-то модуль, в нем используется еще один модуль под названием DB. В самом примере используется функция, которая считает общую сумму:
# my_module.py
from db import db_read
def total_value(item_id):
items = db_read(item_id)
return sum(items)Вполне обычный прямолинейный пример. Как мы используем мок-объекты и патчи для тестирования этого кода? Первым делом мы создаем патч, чтобы обойти модуль DB. Создаем мок-объект db_read и первым делом назначаем какое-нибудь значение-мишень, которое нужно будет вернуть.
# test_my_module.py
from unittest.mock import patch
from my_module import total_value
def test_total_value():
with patch('my_module.db_read') as db_read:
db_read.return_value = [100, 200]
assert 300 == total_value(1234)
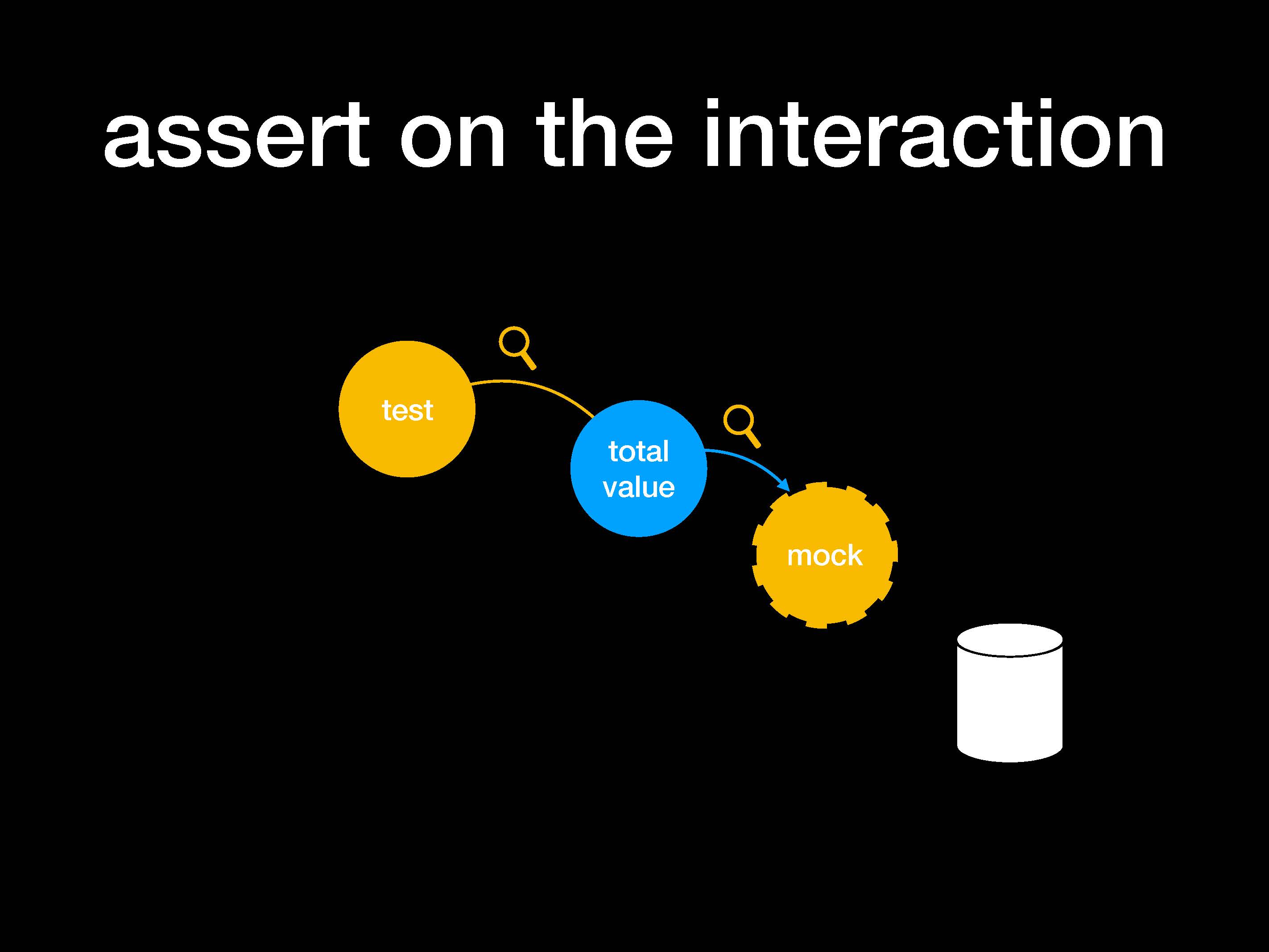
db_read.assert_called_with(1234)Мы исполняем код, прикладываем утверждение assert насчет побочных эффектов или взаимодействия с этой функцией db_read.
Если изобразить данное взаимодействие в виде картинки, то, думаю, получится примерно вот так:
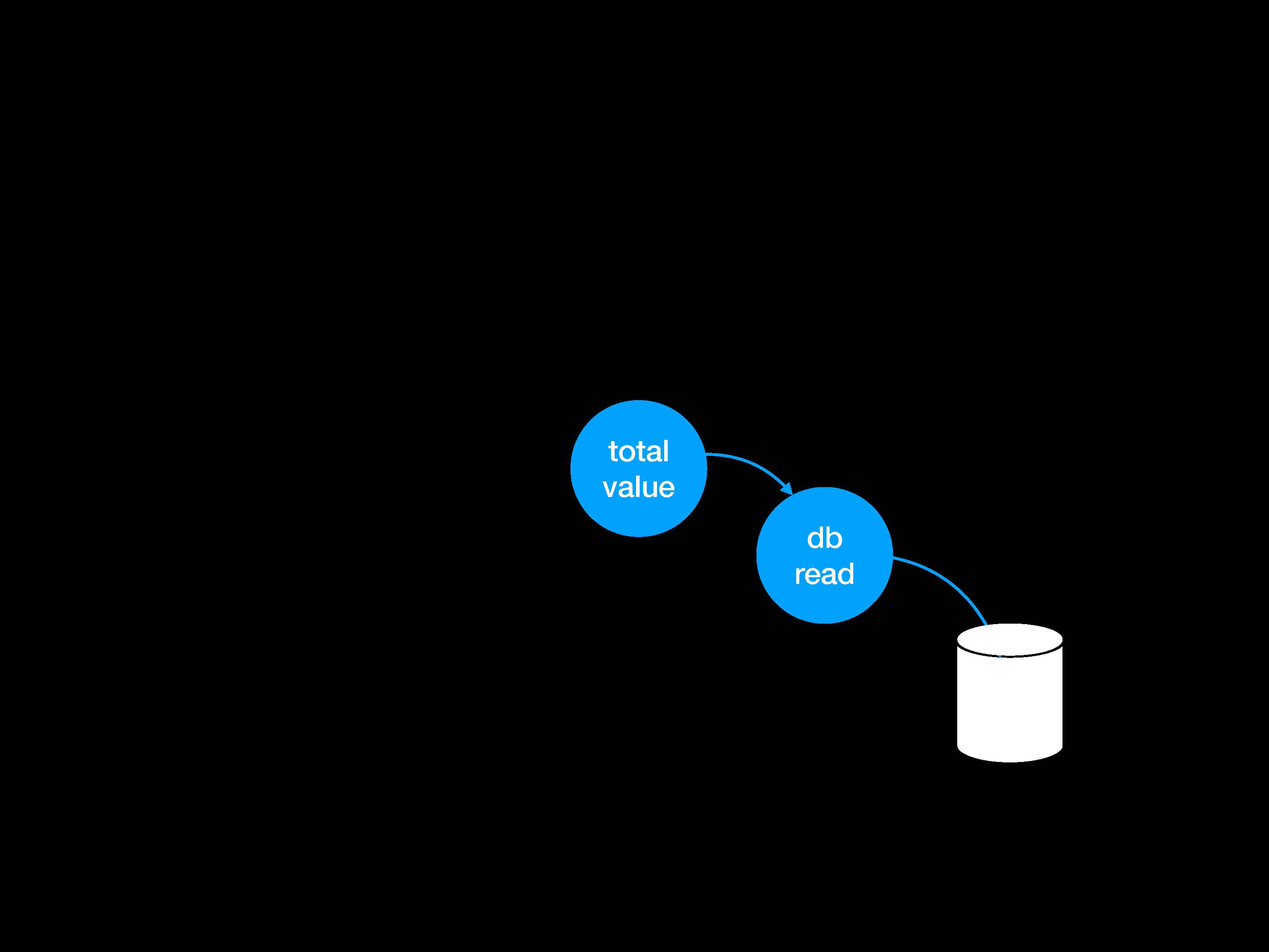
Итак, у нас есть общее значение в db_read, далее появится внешняя база данных. Когда мы пишем тест, то настраиваем патч для обхода этой функции db_read и заменяем ее на мок-объект.
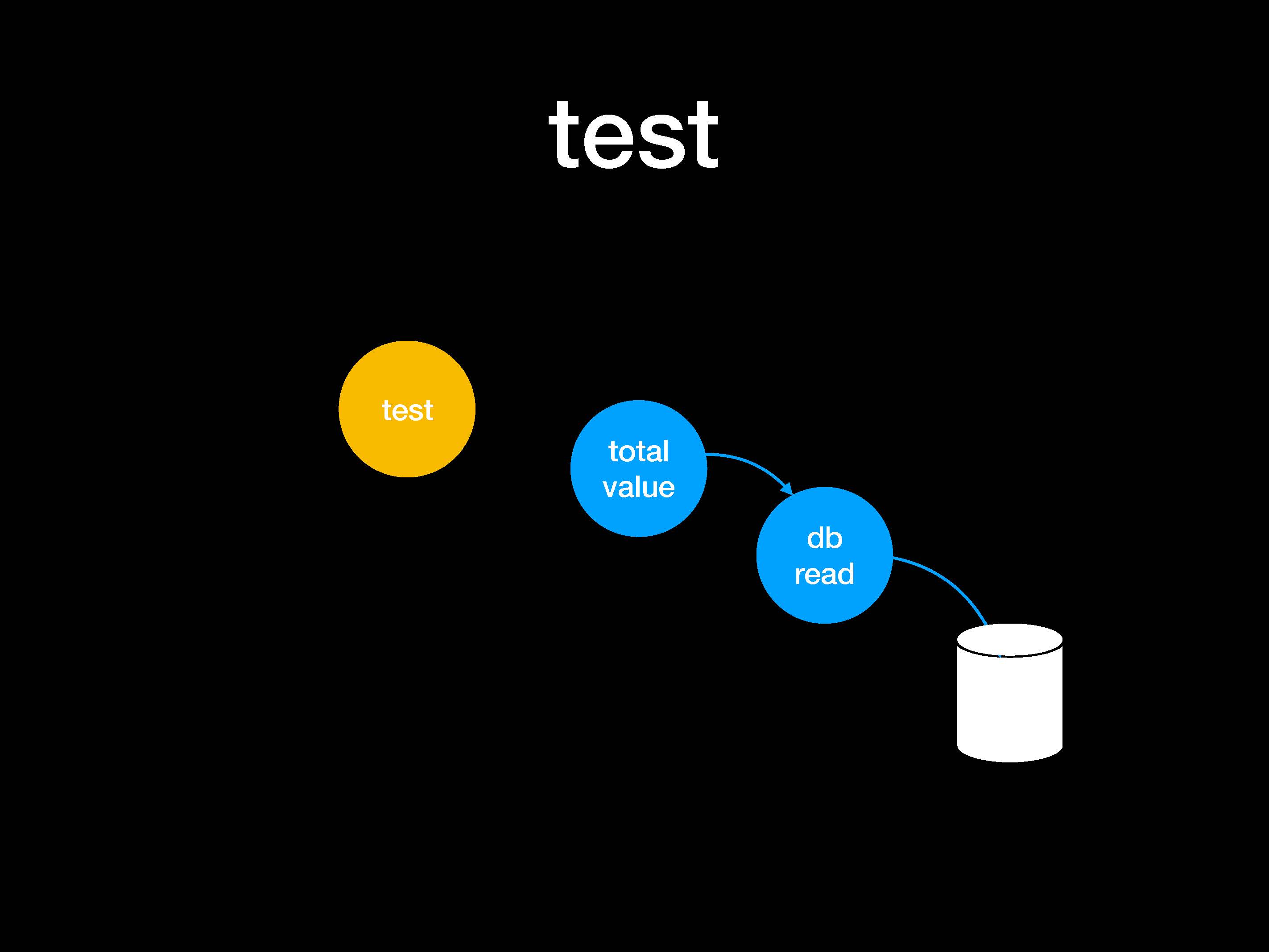
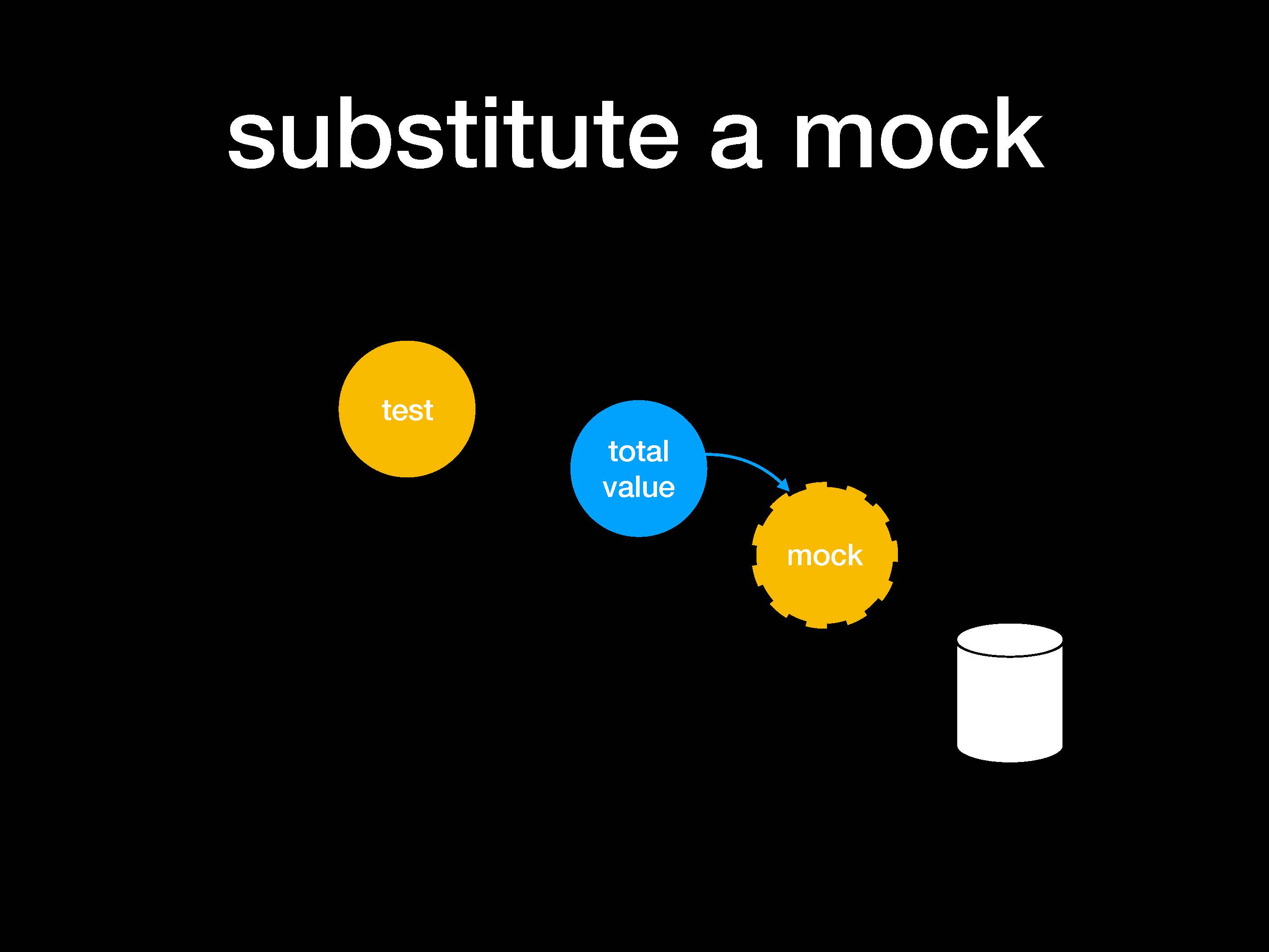
Теперь у нас есть общее значение (total value) в db_read и внешняя база данных (белого цвета). Напишем тесты, в которых предусмотрен патч в обход db_read. В итоге тест использует функцию total value и выполняет два утверждения (assertions) по результату и процедуре взаимодействия.
Пример из реальной жизни
Вводные данные
Мы можем воспользоваться этими знаниями и применить их при решении реальной проблемы. Я подготовил небольшой пример, более реалистичный, чем предыдущий. Мы сделаем фид с материалами газеты Guardian. Это новостной сайт в Англии, который предлагает REST API для поиска по всей своей базе данных статей.
В этом случае гипотетической проблемой будет определенная интересующая тема, например Брексит. Нужно найти все статьи за определенный период времени и скормить их сервису для веб скрейпинга.
Здесь REST API довольно прямолинейный:

Мы получаем URL и несколько параметров в строке запроса. Можно задать диапазон дат и нужный нам номер страницы, так как результат, скорее всего, будет не на одну страницу. Еще, конечно, ключ API.
Вот так выглядит ответ:
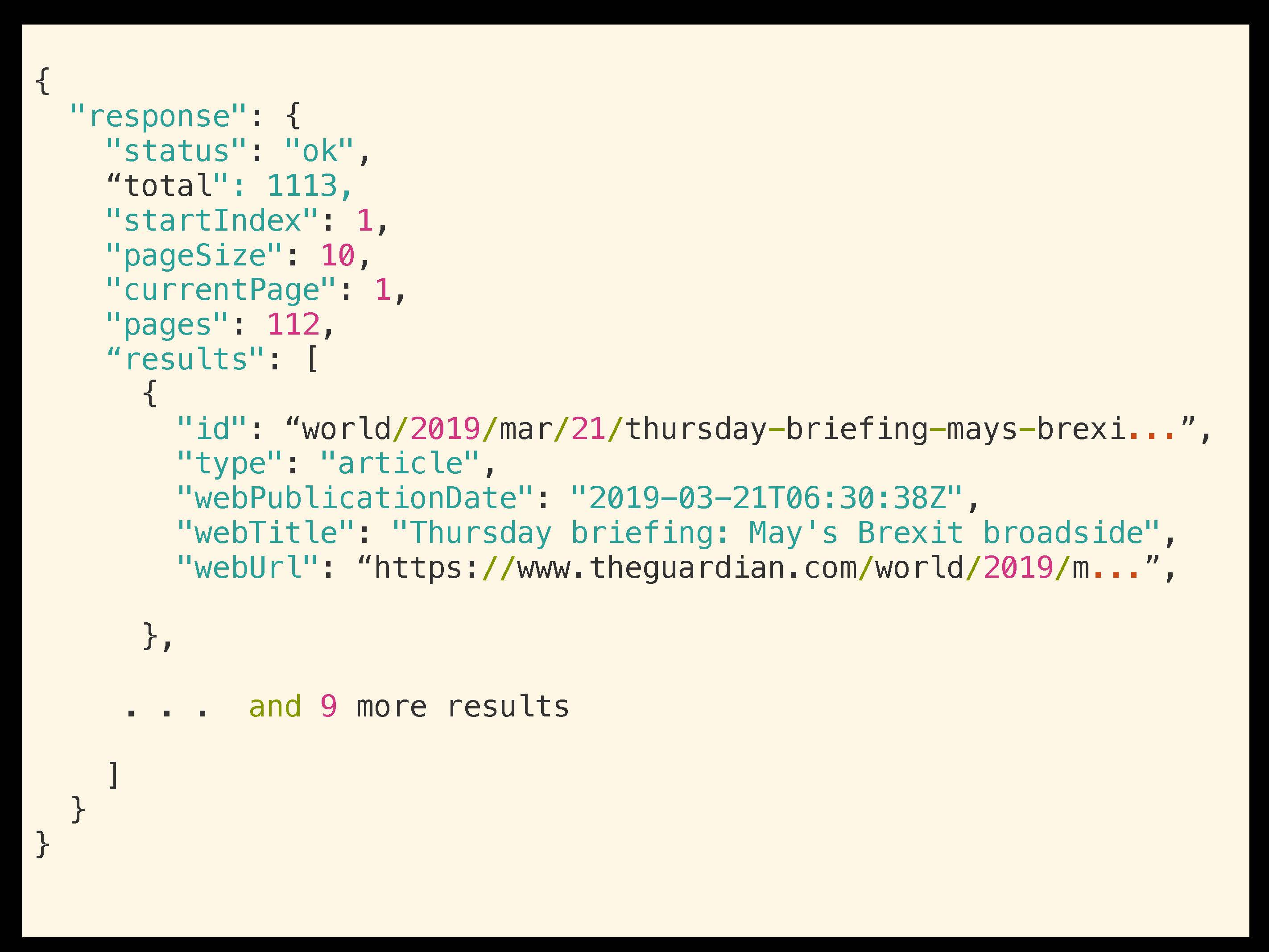
Это просто блоб ответа. В нем есть номер текущей страницы, массив (array) с результатом. Каждый элемент этого массива имеет поле для ссылки, которую мы и хотим забрать и перенести в скрейпера.
Программа для нашего примера
Она довольно прямолинейная. Мы создаем фид с помощью запроса и запускаем его. У нас будет класс Feed:
import redis
import requests
class Feed(object):
def __init__(self,
query,
redis_host=None,
page_size=None,
date_range=None):
self._query, self.page_size =query, page_size
self.date_range =date_range or (None, None)
self._redis_con =redis.Redis(redis_host or "localhost")
self._session =requests.Session()
def format_request(self, page):
def param(key, val):
return{key: val} ifval is not None else{}
params={"page": page,
"query": self._query,
"api-key": _APIKEY}
params.update(param("page_size", self.page_size))
# repeat for from-date, to-date
returnRequest('GET', _BASE_URL, params=params).prepare()
def run(self):
page, page_count = (1, 1)
while page <=page_count:
rsp = self._session.send(self.format_request(page))
rsp.raise_for_status()
response =rsp.json()['response']
page_count =response['pages']
results =response[‘results']
def push(web_url):
self._redis_con.rpush("scrape_urls", web_url)
list(map(push, (r['webUrl'] forr inresults)))
page += 1Сначала конструктор принимает параметр query с размером страницы page_size, который представляет собой количество результатов на страницу. Далее идет диапазон дат date_range. В конце у нас има хоста для Redis, куда мы и будем отправлять все ссылки.
Последние две строки конструктора как раз создают соединение для Redis и сессию requests. Функция просто берет все эти параметры и номер страницы и отправляет HTTP GET. Именно это можно увидеть на последней строке функции, где происходит вызов requests.
Последний метод run выполняет всю реальную работу в цикле while. Он принимает результаты, парсит поле со ссылкой в каждом элементе результата и отправляет ее в Redis. Последняя часть немного странная, потому что я хотел поместить все на один слайд.
Вот так это может выглядеть на картинке (сразу с тестом):
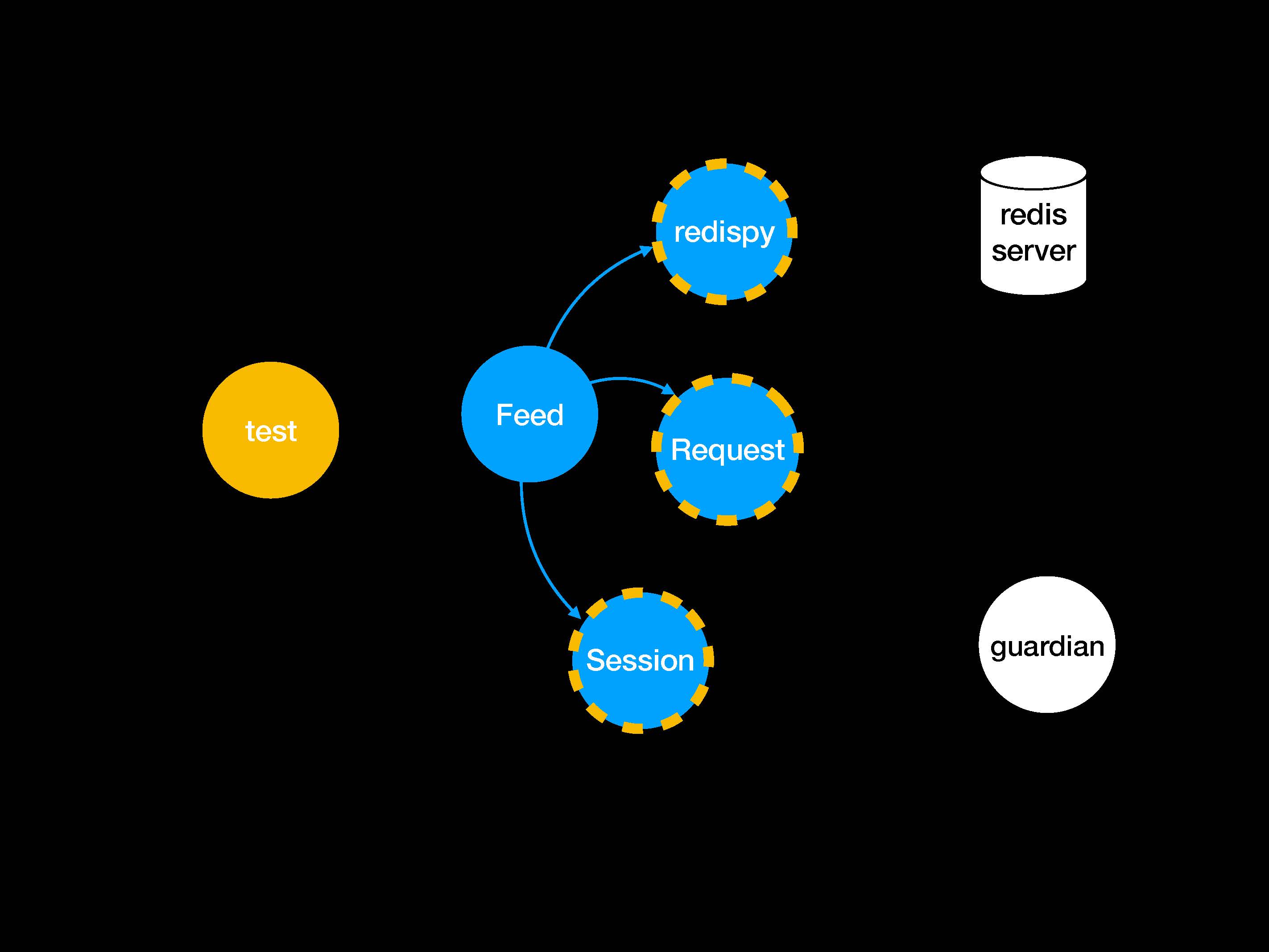
Внешние системы показаны белым цветом. Если исходить из вышеприведенного вновь изученного шаблона, нам нужно сделать патчи для обведенных желтым зависимостей (dependencies), чтобы изолировать класс Feed. Потом мы сделаем мок-объекты и запустим тест.
Как будет выглядеть тест для нашего примера
@patch("feed.redis.Redis", autospec=True)
@patch("feed.requests.Session", autospec=True)
@patch("feed.Request", autospec=True)
def test_run(request_mock, session_mock, mock_Redis):
mock_response =MagicMock(spec=requests.Response)
mock_response.json.return_value ={
"response": {
"pages": 1,
"results": [
{"webUrl": "http://article1"},
{"webUrl": "http://article2"}
]
}
}
session_mock.return_value.send.return_value =mock_response
Feed("brexit").run()
request_mock.return_value.prepare.assert_called()
params ={"page": 1, "api-key": ‘<apikey>', 'query': 'brexit'}
expected_call = mock.call("GET", _GUARDIAN_URL, params=params)
assert expected_call ==request_mock.call_args
mock_Redis.assert_called_with("localhost")
expected_calls = [call('scrape_urls', 'http://article1'), ...]
assert expected_calls ==mock_Redis.return_value.rpush.call_args_listСначала нам нужно сделать ответ на запрос. Поэтому у нас появился фейковый ответ, который просто возвращает одну страницу с двумя результатами после реального вызова функции run. Она дотянется до request API, который станет побочным эффектом.
Поэтому я сделаю несколько утверждений для этих побочных эффектов. Сначала будет утверждение о том, что вызван метод подготовки. Мы проверяем, что сообщение запроса сконструировано корректно через сопоставление с ожидаемыми параметрами.
Также у нас будет утверждение о запросе в адрес Redis. Проверяем, что оно тоже сконструировалось корректно, и вызвано две ссылки.
В итоге получилось довольно много кода. Много мок-объектов и патчей. В реальности, когда я заканчиваю с кодом, построенным по такому шаблону, но на гораздо более высоком масштабе, я просто изумляюсь. Непонятно, как же так получается, почему код выглядит именно так.
Какой перед нами вопрос? Есть ли понимание, как править нечто, похожее на это, или как этого избежать изначально. Прежде чем переходить к этой части, нужно уметь задавать конкретные вопросы, помогающие обозначить проблемы с этим кодом.
Первый вопрос. Сколько мок-объектов, по вашему, в этом коде?
Давайте просто поднимать руки. Кто думает, что три? Кто — четыре? Кто думает, что больше четырех? Ладно. Похоже тут многие знакомы с моими методами. На самом деле, здесь 11 мок-объектов.

У нас образчик поведения на основе мок-объектов, которые становятся палкой о двух концах. С одной стороны, они — фича, с другой — обуза. Потому что они автоматически создают еще один мок-объект, если мы вызываем непредусмотренный метод. Это хорошо, когда мы настраиваем тест, но когда их становится много, то очень легко запутаться.
Выше я уже подсветил все строки с мок-объектами и патчами. Так вот, когда я вижу что-то подобное, то задаю себе вопрос: это и есть то самое важное поведение, на котором должны быть сосредоточены мои тесты или это просто деталь реализации?
Возьмем набор патчей:
@patch("feed.redis.Redis", autospec=True)
@patch("feed.requests.Session", autospec=True)
@patch("feed.Request", autospec=True)Здесь есть по-настоящему нужная информация? Которую тест должен знать, или это просто нарушение принципа скрытия информации или инкапсуляции с точки зрения класса Feed.
Если посмотреть на следующие строки, то можно утверждать, что они нарушают закон Деметера:
def test_run(request_mock, session_mock, mock_Redis):
mock_response =MagicMock(spec=requests.Response)
mock_response.json.return_value ={
session_mock.return_value.send.return_value =mock_response
request_mock.return_value.prepare.assert_called()
assertexpected_calls == mock_Redis.return_value.rpush.call_args_listЭто идея из объектно-ориентированного проектирования о построении вызовов методов в цепочки переменных с экземплярами объектов. Почему это плохо? Это очень агрессивный подход, так мы погружаемся в иерархию объектов слишком глубоко.
Возможные варианты традиционного рефакторинга
Можно переключиться на другие мысли по этой теме. Например, как можно тривиальным образом разбить этот тест с помощью мягких безвредных идей рефакторинга. Например:
from redis import Redis
import requests
Но тогда будет нарушен один из патчей.

Еще один пример такого подхода. Допустим, мы поменяем конструктор запроса, чтобы вместо kwargs принимать args:
Было:
class Feed(object):
def format_request(self, page):
def param(key, val):
return{key: val} if val is not None else{}
params={"page": page,
"query": self._query,
"api-key": _APIKEY}
params.update(param("page_size", self.page_size))
# repeat for from-date, to-date
returnRequest('GET', _BASE_URL, params=params).prepare()Стало:
class Feed(object):
def format_request(self, page):
def param(key, val):
return{key: val} ifval is not None else{}
params={"page": page,
"query": self._query,
"api-key": _APIKEY}
params.update(param("page_size", self.page_size))
# repeat for from-date, to-date
returnRequest('GET', _BASE_URL, params).prepare() Тогда будет нарушен этот мок-объект:

Итак, получается, что у нас пример довольно хрупкой спецификации или чрезмерной верификации. Наверное, можно было бы показать гораздо больше примеров такой базы кода. Мне кажется, именно это происходит, когда мы учимся пользоваться мок-объектами и патчами. Не замечаем текст с мелким шрифтом, да.
Обычно мелким шрифтом в сноске пишут: кстати, избегайте чрезмерного количества мок-объектов. Этот совет часто появляется в самом конце как дополнительная мысль. Его просто игнорируют или не очень хорошо понимают.
А еще может даже оказаться вторая сноска со словами о том, что мок-объекты — это не заглушки (studs).
Новый подход
Как я уже говорил, при изучении вопроса я посмотрел все видео про мок-объекты с предыдущих конференци PyCon. Хотелось убедиться, что не буду просто повторять уже известную информацию или говорить что-то безумное.
По большей части оказалось, что воспроизводится та модель поведения, о которой я сейчас говорил. В прошлом году было одно выступление на PyCon Cleveland 2018 под названием "Demystifying the Patch Function". Очень хорошее выступление, на самом деле. Особенно если вы запутались в том, как нужно использовать patch API.
Посмотрев данное выступление, я кое-что понял по поводу некоторых своих приемов и нескольких из примеров, которые будут дальше. Кстати, хочу сказать спасибо Лизе Роуч, автору того выступления. Ведь я попросил ее посмотреть на мои слайды и дать какой-нибудь фидбек. И она была настолько любезна, что даже сделала это.
Так вот, причиной моего выбора этой темы было кое-что интересное, произошедшее в Кливленде на стадии вопросов и ответов. Кто-то поднялся и сказал о том, что сталкивается со всеми этими проблемами с патчами, обслуживанием и техническим долгом (technical debt). Что же делать, есть ли у вас какие-нибудь подсказки?
Ответ: патчи и правда могут выйти из-под контроля. Возможно, вам следует присмотреться, почему так много тяжелых мок-объектов. Сам по себе этот ответ не так интересен. Просто это пример того самого мелкого шрифта.
Теперь к интересному моменту. Еще кто-то поднимается, здоровается, хвалит выступление и говорит, что он — тот самый Майкл Фоорд, который придумал мок-объекты. Он говорит, что патчи — признак провала. Чем больше нам нужно патчей для кода, тем хуже наш код.
Мне кажется, это совет в самую точку. Так оно и есть. Не нравится в нем то, насколько он загадочный. Если у нас проблемы с мок-объектом, этот ответ не особо поможет.
Что же делать дальше? Предполагается, что мы попытаемся исправиться. Я хочу опуститься поглубже в значение этих объектов. Что такое патчи и почему они являются показателем неудачного кода. Другими словами, нам, возможно, стоит разобраться, почему так много мок-объектов.
Немного истории
Мок-объекты и их место
Думаю, есть смысл больше узнать о происхождении мок-объектов, откуда они взялись. На самом деле, при создании мок-объектов идея заключалась в том, что в идеале должна существовать симбиотическая связь между кодом и тестами. Другими словами, тесты должны отражать качество кода.
Иногда встречается такой совет: слушайте свои тесты. Он впервые появился в книге "Growing Object-Oriented Software, Guided by Tests" Стива Фримана и Нэта Прайса (Steve Freeman, Nat Pryce). Авторы изобрели процесс использования мок-объектов. В приложении к этой книге они рассказывают о том, каким образом пришли к своим идеям, на что была похожа их работа в контексте экстремального программирования, TDD и объектно-ориентированного проектирования на Java.
Когда они писали эту книгу, то параллельно подготовили академическую работу под названием "Mock Roles, not Objects" (Создавайте мок-объекты для ролей, а не для объектов). В аннотации к этой работе есть три по-настоящему важных момента, которые будут полезны тем, кто попадает в ад с мок-объектами или просто сталкивается с проблемами при их использовании.
1. Мок-объекты представляют собой расширение процесса разработки на основе тестирования.
2. Мок-объекты помогают следовать принципам хорошего объектно-ориентированного проектирования.
3. Мок-объекты не предназначены для изолирования тестов.
Мне кажется, это нужно понимать, потому что данный текст прямо противоречит тому, что можно прочитать в Интернете в каком-нибудь блоге или материале об использовании мок-объектов или причинах существования мок-объектов и патчей.
Мок-объекты были созданы в контексте реализации TDD и объектно-ориентированного проектирования. Никогда они не считались инструментом для изолирования.
Если подумать о вышеприведенных трех пунктах, то окажется, что:
- следуя принципам TDD мы выполняем быстрые циклы мелкого рефакторинга;
- в объектно-ориентированном проектировании важна идея сотрудничества объектов (object collaboration) и ролевого подхода к проектированию (role-based design). Если вы когда-нибудь слышали про CRC-карты, то на базовом уровне это все одно и то же;
- мок-объекты предназначены для использования в качестве инструмента предпроектного исследования (exploratory design) и изучения.
На мой взгляд, эти три момента существуют совместно как ножки табурета. Если убрать одну из ножек, все начинает разваливаться.
Возражения против используемого подхода
Этот стиль TDD нравится не всем. Например, есть книга "The Art of Unit Testing with examples in C#". Она мне нравится, потому что в ней используется довольно тонкий и проницательный подход. В ней говорится, что тестирование взаимодействия (interaction testing) и мок-объекты должны быть последним средством. Это очень важный момент, не все с ним согласны.
Нэт Прайс сказал бы в защиту этой позиции, что с точки зрения обслуживания мок-объекты создают больше проблем, чем пользы. Не могу сказать, что полностью не согласен с этим.
В общем, я просто поднимаю эту тему, потому что это довольно убедительно. И вы, наверное, не найдете ничего подобного ни в каких материалах про Python и мок-объекты.
Итак, если вы согласны с этой идеей о том, что не нужно пользоваться мок-объектами, или хотите избавиться от мок-объектов, то вы задаете вопрос: как же тестировать без мок-объектов?
Мок-объекты — это не заглушки
Мы уже почти перешли к работе с кодом. Последнее, что скажу, будет насчет идеи о том, что мок-объекты нельзя называть заглушками. Представлю эту мысль следующим образом:
1. Мок-объекты — не заглушки
2. Мок-объекты != заглушки
3. Заглушки — не мок-объекты
Почему я так педантично к этому подхожу. Потому что это важно, в том числе для понимания остальных слайдов.
Рассмотрим понятие тестовых дублей (test doubles). По сути, это объект, которым мы заменяем реальный объект. Получается, что мок-объект представляет собой один из видов дублей. Библиотека Python Mock немного путает термины, ведь ее можно настроить для работы в качестве любого из дублей. Просто в ней используется другой словарь, другая терминология. Поэтому становится немного труднее говорить об этом всем.
Я добавлю определения для понятий и просто покажу их на примерах.
Мок-объект (mock) — записывает вызовы объекта.
Заглушка (stub) — возвращает фиксированные данные, логики нет.
Фейк (fake) — реализует несуществующий вариант производственной версии.
Пустышка (dummy) — ничего не делает.
Шпион (spy) — ведет запись и делегирует реальному объекту.
Вернемся к примеру из начала выступления. Там у нас есть заглушка и мок-объект.

Что такое заглушка? Это просто значение, которое будет возвращаться. На слайде под заглушкой идет мок-объект, важной частью которого является то, что он создает предполагаемое действие или побочный эффект с помощью другой системы. Именно это и называют лондонским стилем тестирования.
Мы можем сделать альтернативный вариант с фейковым патчем. У нас будет функция fake_db_read() с небольшой логикой для возврата зафиксированного объекта (fixture) из файловой системы. Далее я воспользуюсь этим объектом, чтобы создать патч и пользоваться им вместо мок-объекта.
# test_my_module.py
from unittest.mock import patch
from my_module import total_value
def test_total_value():
def fake_db_read(item_id):
with open(f'./fixtures/{item_id}.json') asfobj:
return json.load(fobj)
with patch('my_module.db_read', new=fake_db_read):
assert 300 == total_value(1234) Теперь мне не нужно ставить assert для проверки побочного эффекта или взаимодействия.
Как это может выглядеть в графике. Сначала мы создаем патч.
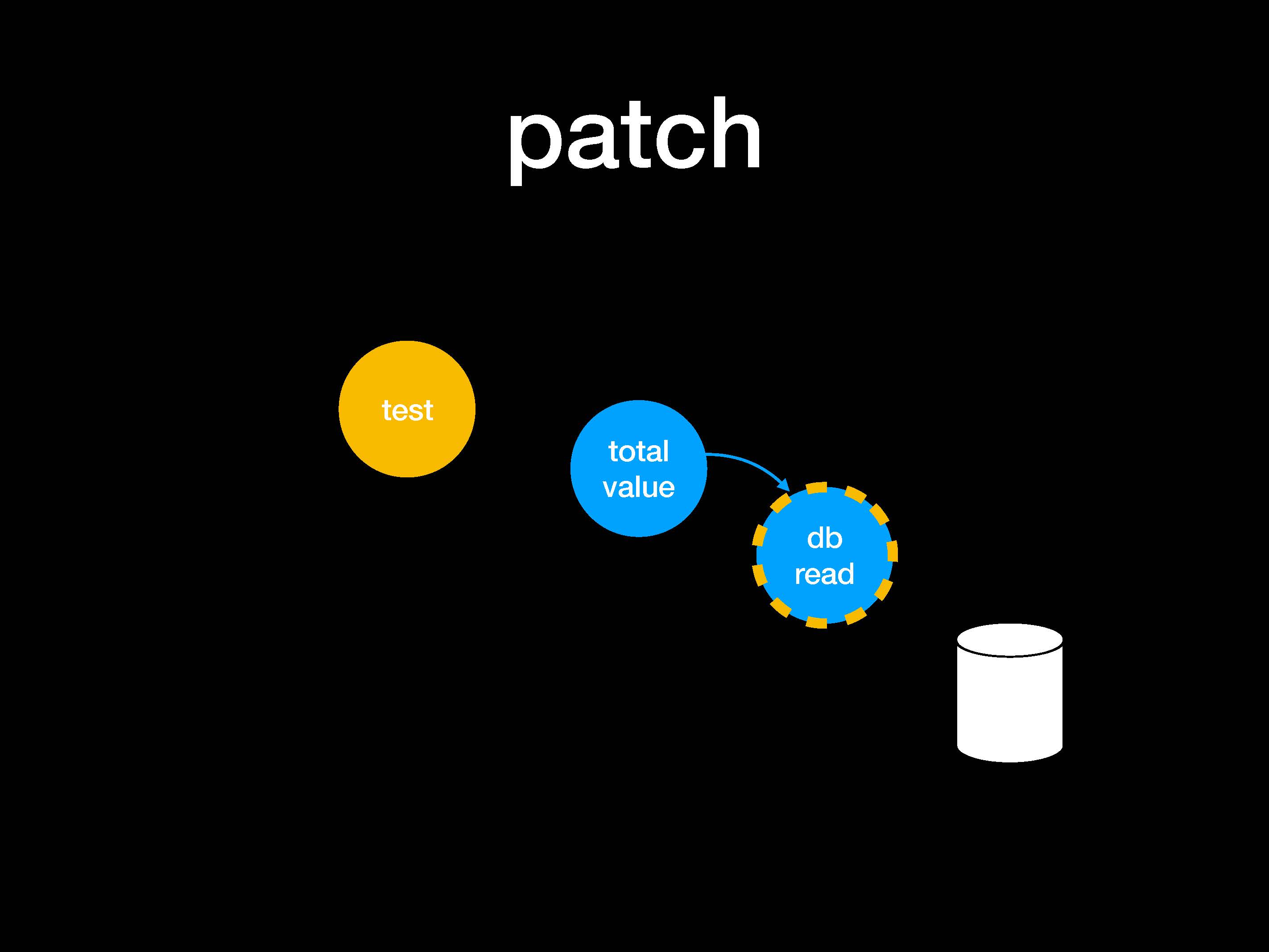
Далее мы вставляем свой патч по методу внедрения зависимости (dependency injection). Нам нужно подменить функцию total_value и избавиться от необходимости импортировать DB_read.
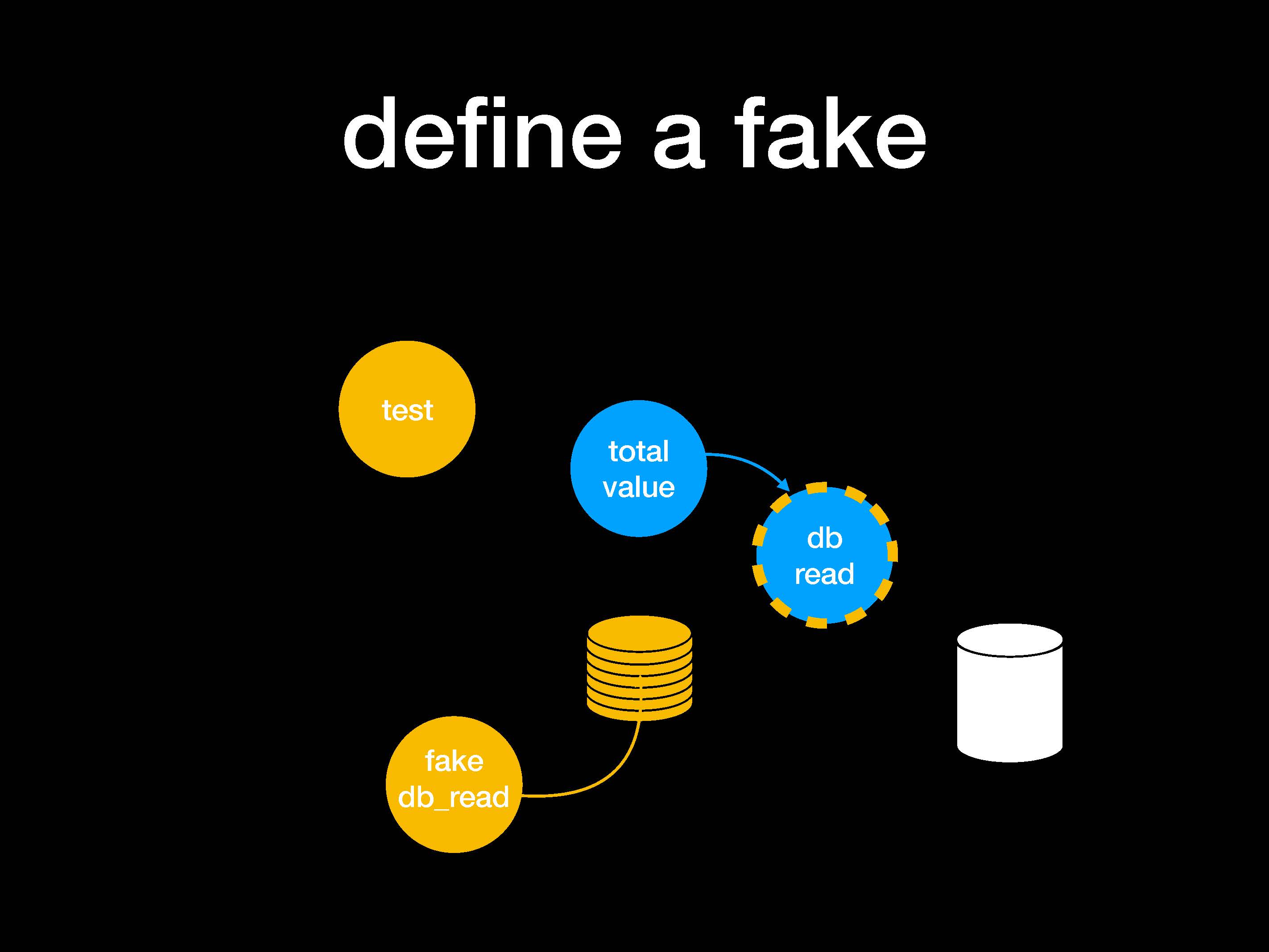
Получается, что total_value обращается к fake db_read вместо реальной функции.
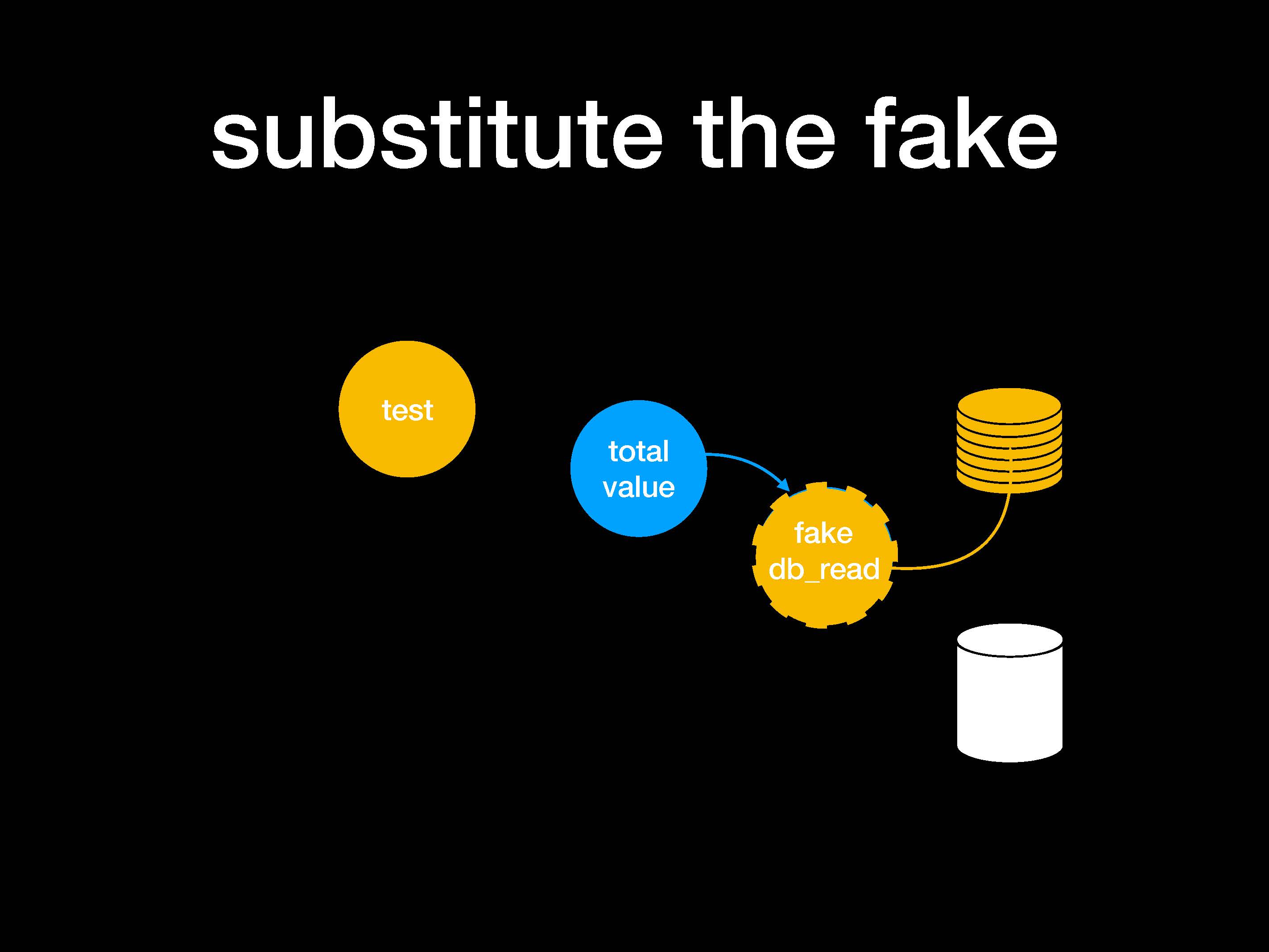
Таким образом, мой модуль перестает зависеть от реализации DB_read. Когда мы вставляем патч, тест будет одинаковым в любом случае, исключая добавленный мной параметр при вызове функции.
Итак, когда речь заходит про тестирование и рефакторинг, мне кажется удобным задавать три вопроса:
1. Какой следует использовать тестовый дубль (мок-объект или что-то другое)?
2. Каким стилем тестирования следует пользоваться: лондонским (побочные эффекты) или детройтским (просто проверить возвращенные значения)?
3. Мы будем делать патч или инъекцию?
Эти методики можно выбирать и сочетать, чтобы получить абсолютно любой результат.
Рефакторинг теста для нашего примера
Вернемся к тесту, который мы используем в качестве примера. Сначала разработаем план тактик и будем перемещать наш самолетик, чтобы лучше понимать, где мы сейчас находимся.
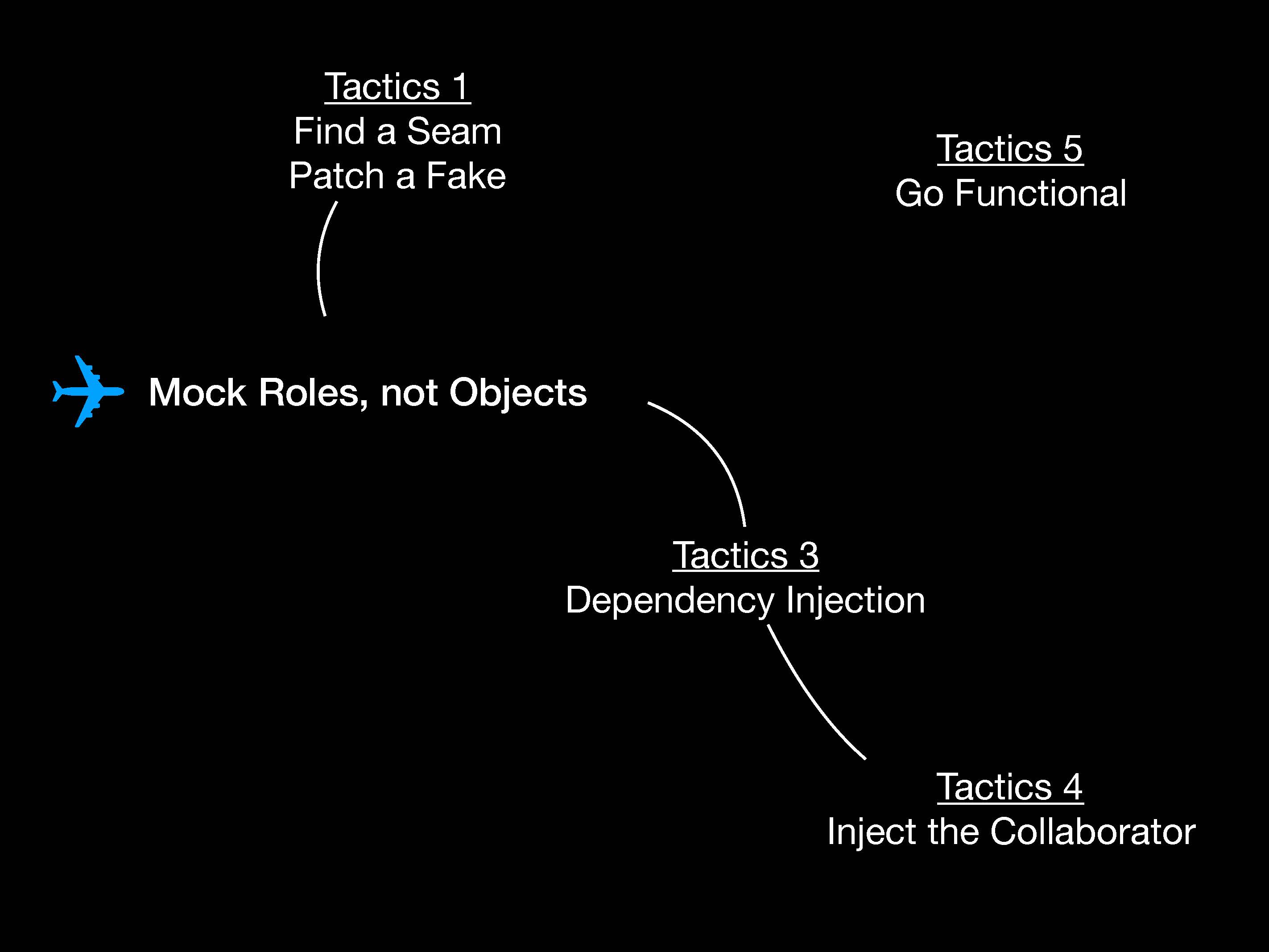
Тактика первая. Создавать мок-объекты для ролей, а не для объектов. Чтобы лучше понять, как это работает, как всегда, нужен пример.
Вспомним про Люка. В своих отношениях с Йодой он выступал в роли ученика.
А еще вспомним Оби-Вана и Анакина. Сначала они тоже играли роли учителя и ученика.
Но потом они же брали на себя роли героя и злодея.

Наконец, Люк и Дарт Вейдер тоже пересекались при исполнении ролей героя и злодея.

Но под конец они взаимодействовали в ролях отца и сына.
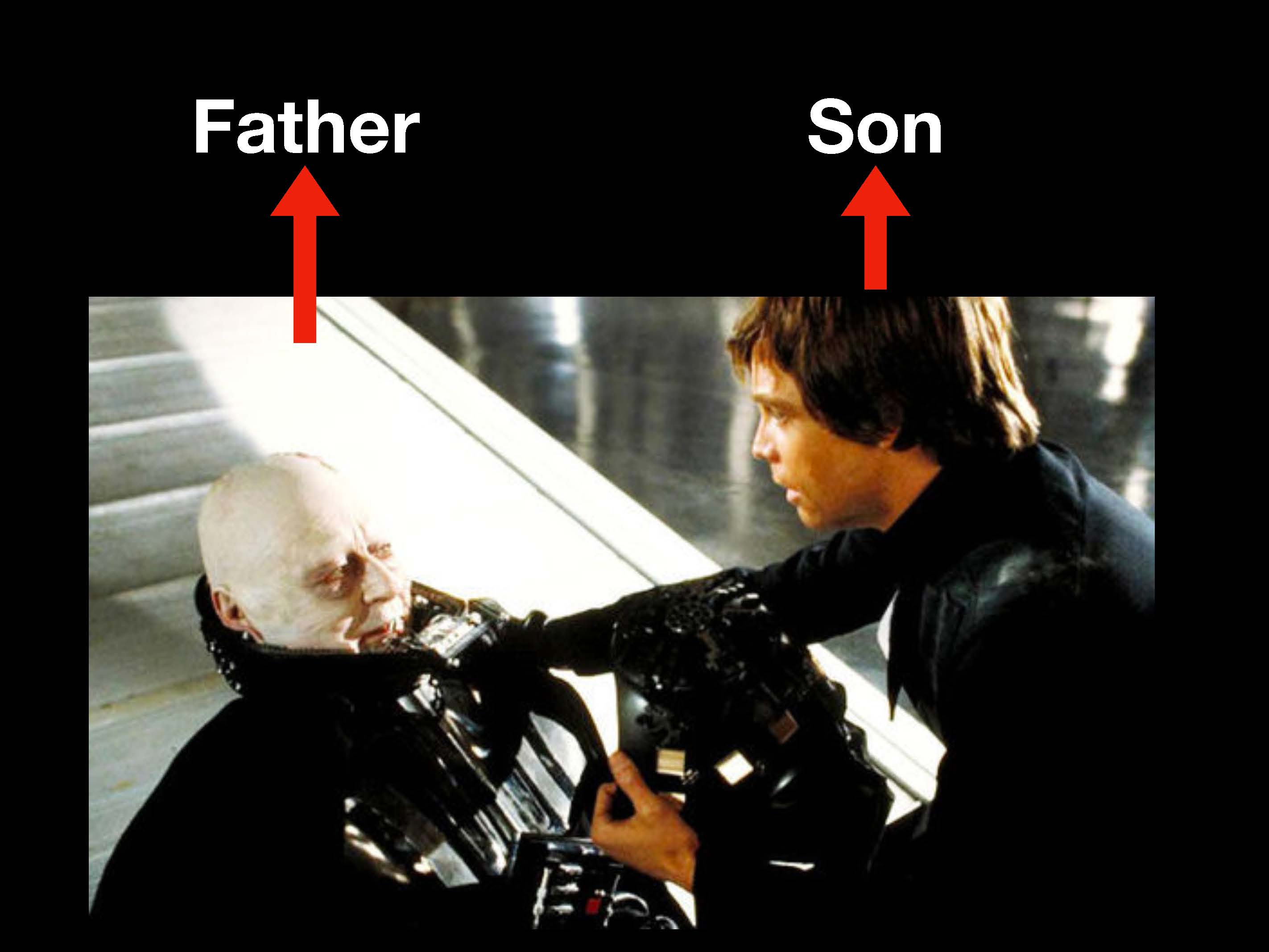
Что все это значит? Изучая код, мы должны задавать вопрос о том, какие в нем выполняются роли. Посмотрим еще раз на схему нашей программы с фидом сайта Guardian.
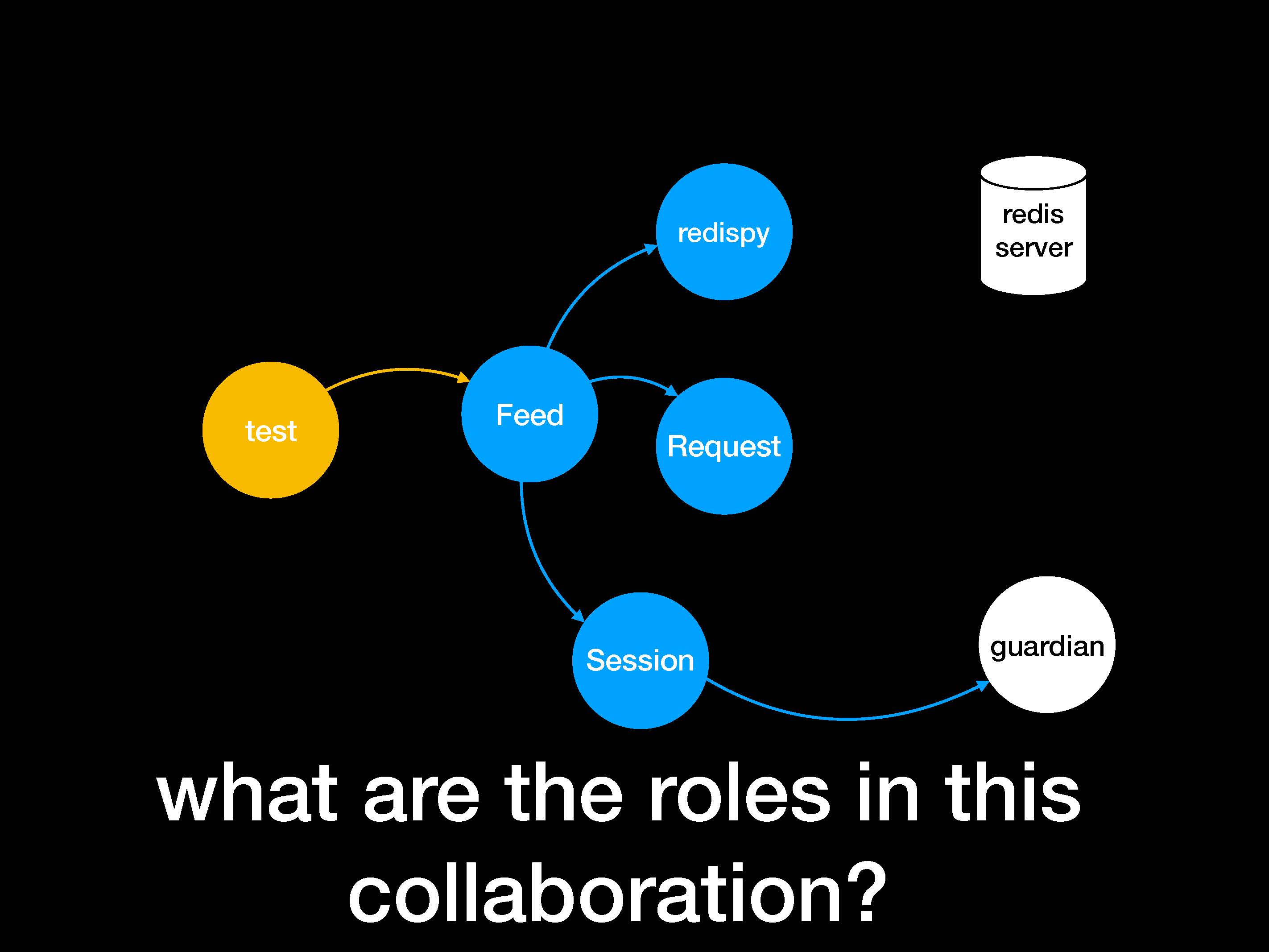
Отвечая на этот вопрос с точки зрения нашей программы, мы скажем, что нам нужен какой-нибудь парсер или коннектор. Нам нужен объект на роль поглотителя данных и на роль источника.
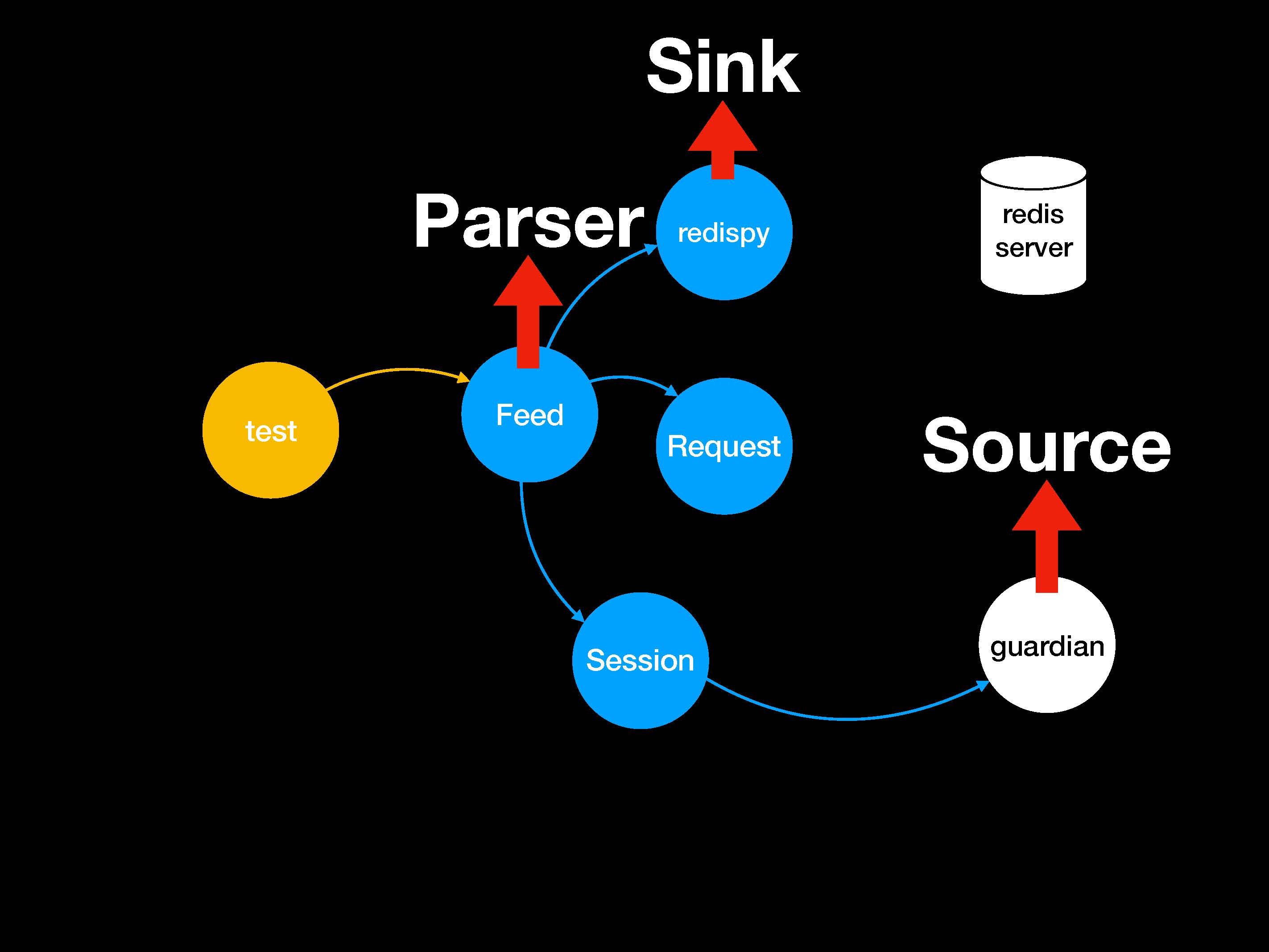
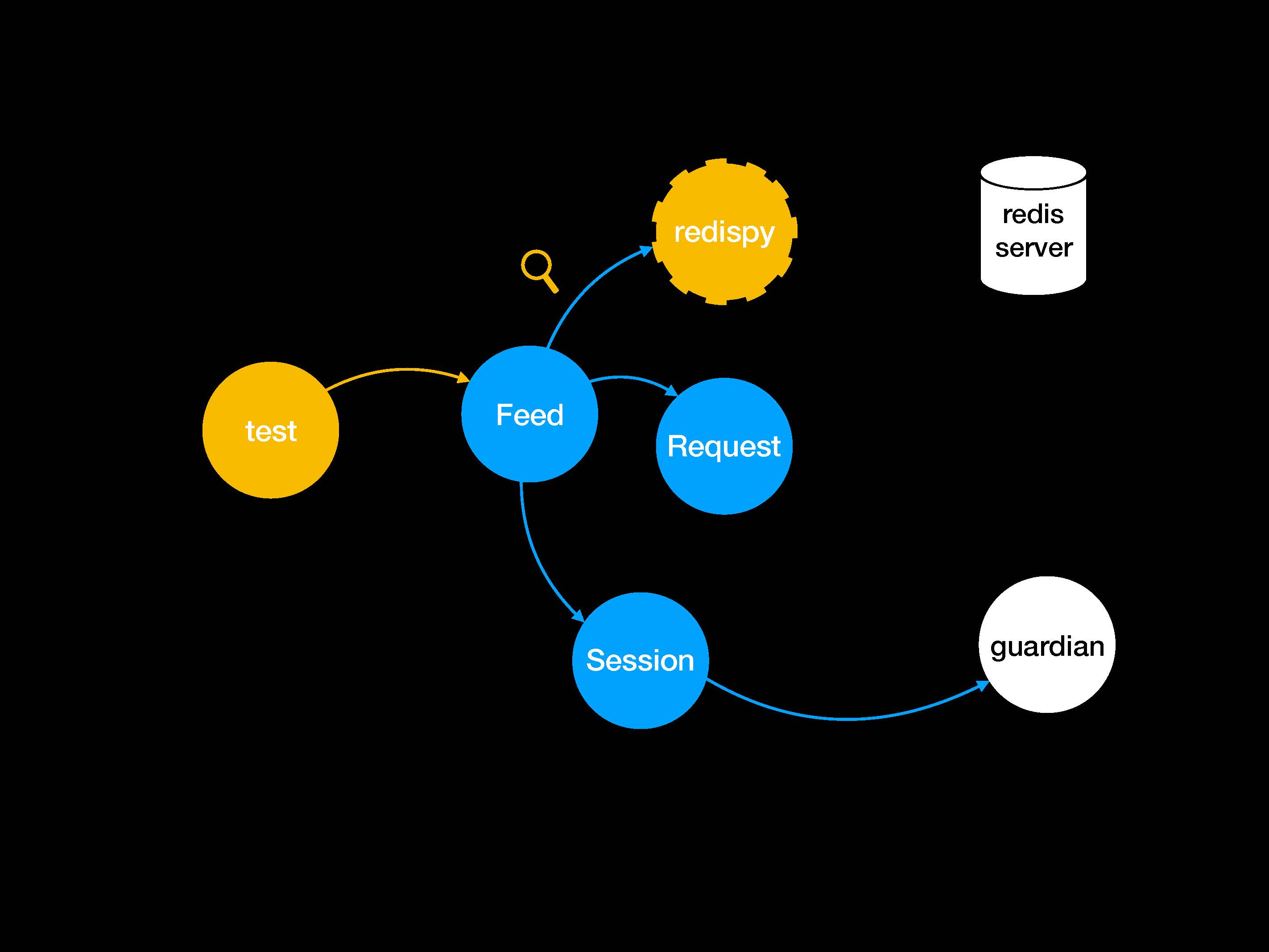
Поэтому мы, как обычно, будем делать мок-объекты или абстракции.
Посмотрим на другие тактики. Первым делом мы займемся мок-объектами и патчами для requests. Идея в том, чтобы найти место стыка, подготовить фейк и внедрить его с помощью патча.
Что такое стык (seam)? Это понятие пришло из рефакторинга и представляет собой такое место, где можно менять поведение в программе без редактирования кода.

Наша главная задача — создать мок-объект для библиотеки Guardian, а не для Session или Request. Ведь Session не пользуется волшебством для подключения к Guardian.
Нет, используется целый пакет других библиотек с большим количеством промежуточных уровней абстракции. Наверное, проще всего будет использовать TCP. В этом случае можно просто сделать мок-объект и вставить его с помощью патча прямо в библиотеку requests вместо того, чтобы пытаться создать мок-объект нашего приложения.
Для этого существует полезная библиотека HTTMock.
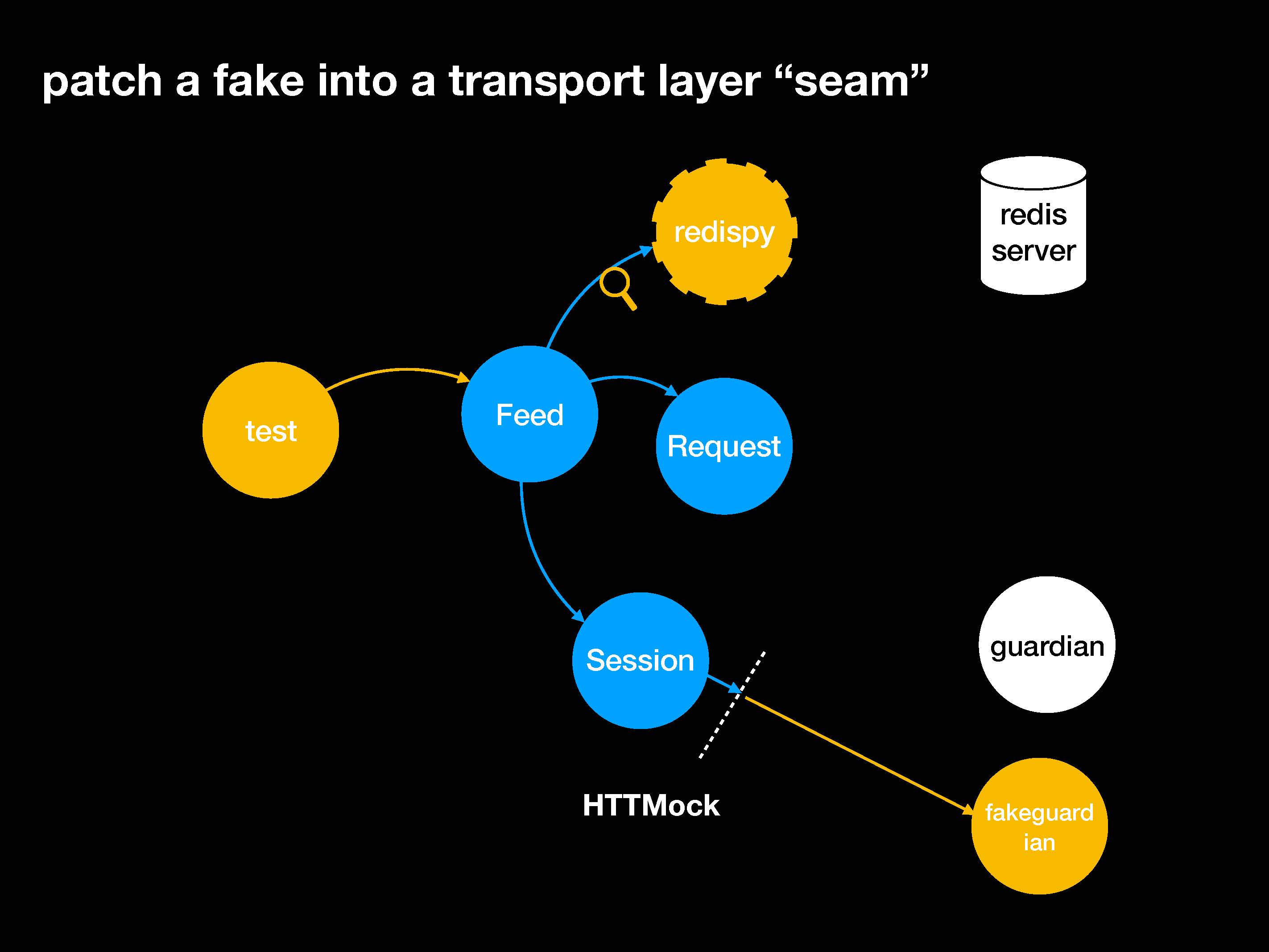
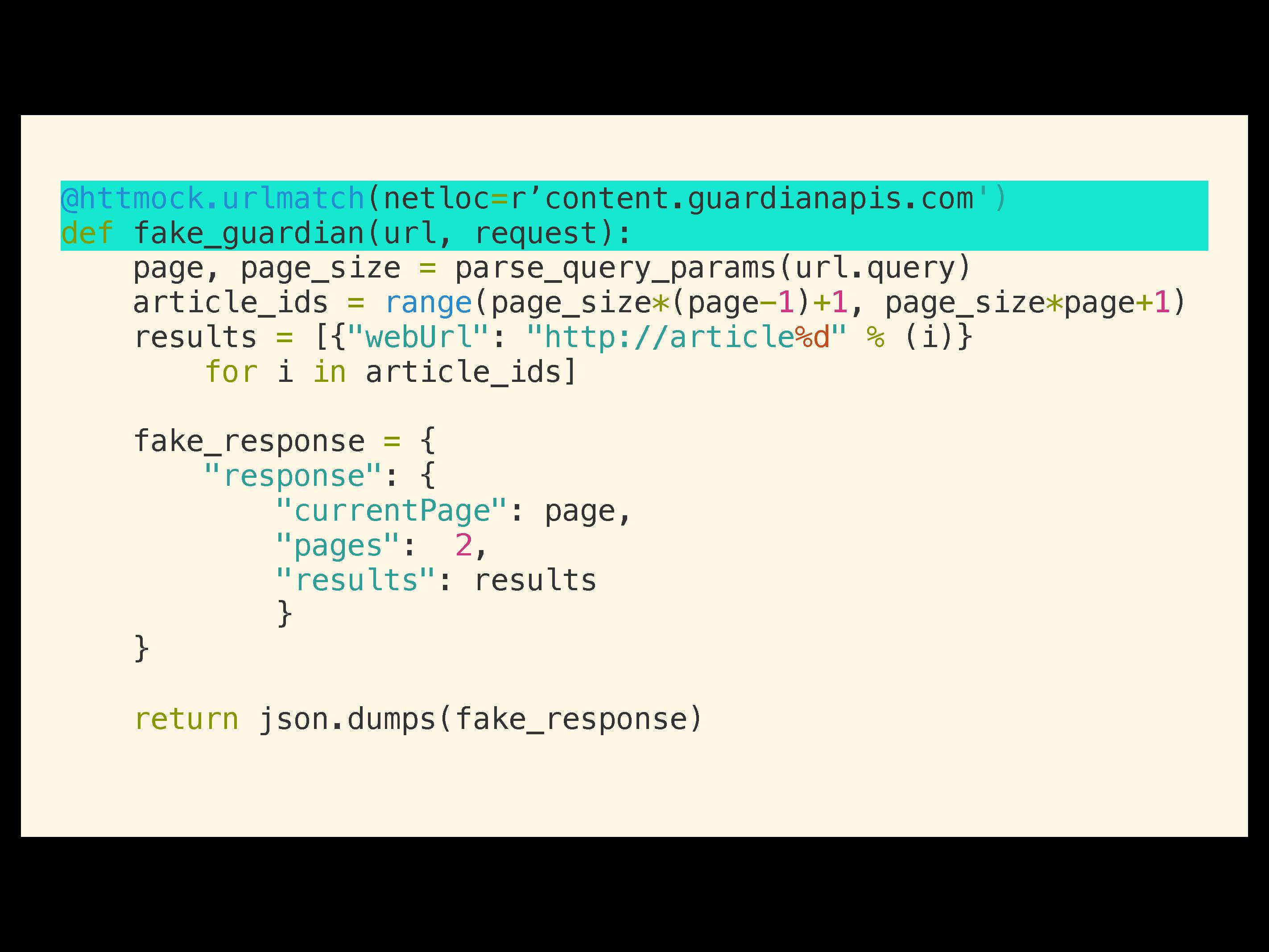
Что мы поменяем в коде. Вместо мок-объекта мы вставим в тест фейк. Фейковая функция будет реализовывать очень простую логику для симуляции настоящего API с сайта Guardian.
Здесь важны две строки. На первой будет urlmatch для HTTMock, который переправляет весь трафик с хоста API на эту функцию. Функция получает URL и тело запроса, мы можем их обрабатывать и делать все необходимое для генерации фейкового ответа и возвращать его.
Вот как это будет выглядеть:
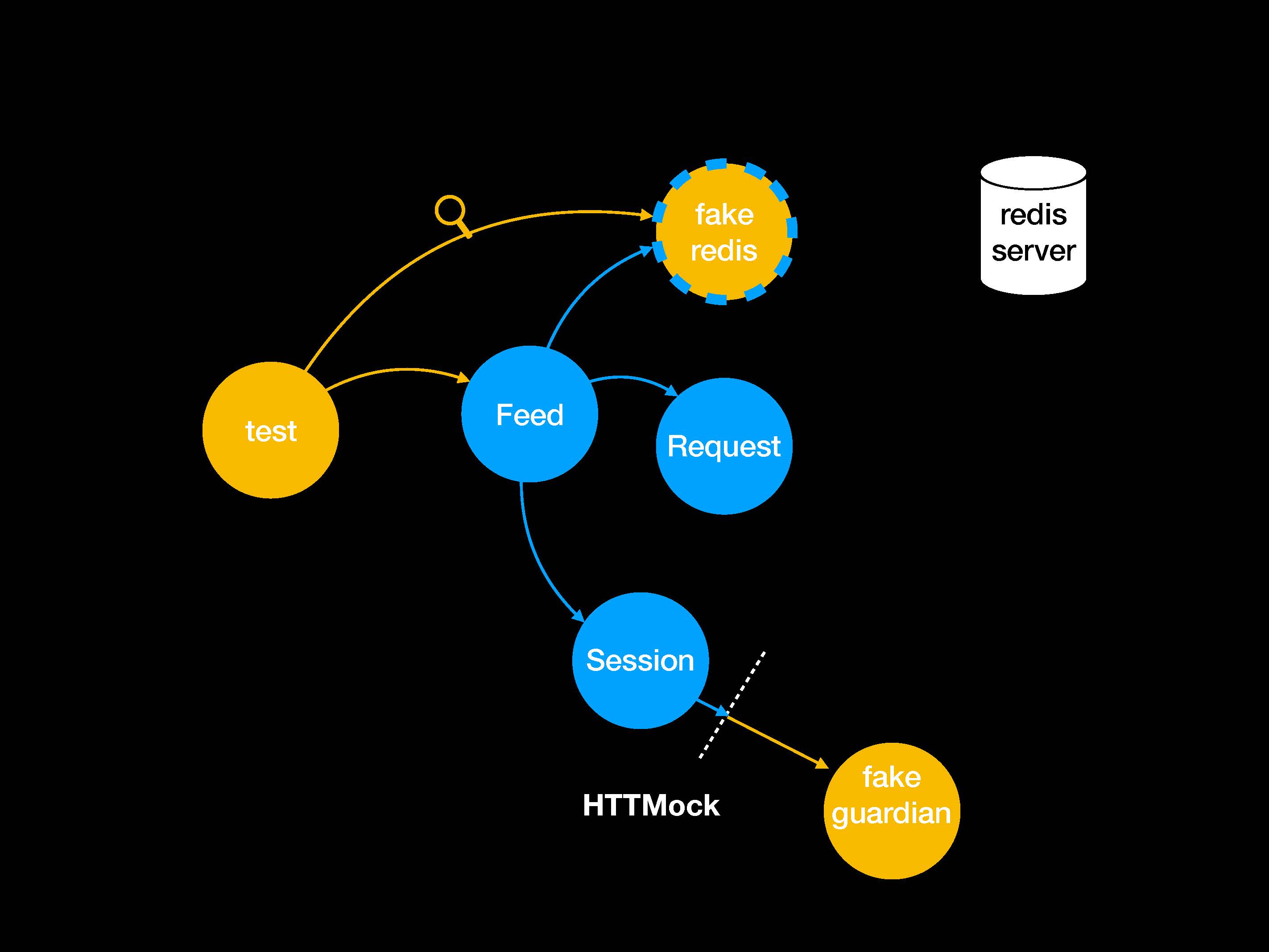
Мок-объект для Redis все еще на месте. Предлагаю избавиться от всех остальных патчей и мок-объектов. Заменим их одним патчем.
Отмечу то самое нужное мне сотрудничество объектов. Мы не отказываемся от патчей, просто используем фейк вместо мок-объекта.
Во-вторых, сделаем инъекцию зависимости. Нацелимся на мок-объект для Redis. Для этого мы поменяем класс Feed и сделаем фейковое подключение к Redis для подмены.

Далее, вместо assert для побочного эффекта мы сделаем assert для статуса фейкового Redis. Вот так это будет выглядеть:

При запуске теста у нас все еще используется хост для Redis. Наше изменение заключается в том, что мы просто хотим сделать инъекцию подключения к Redis. Здесь все достаточно прямолинейно.
Как мы поменяем тест. Нам все еще нужно создать подключение, и фейковый Redis по сути представляет собой библиотеку, создающую по ходу процесса сервер Redis с тем же самым API.
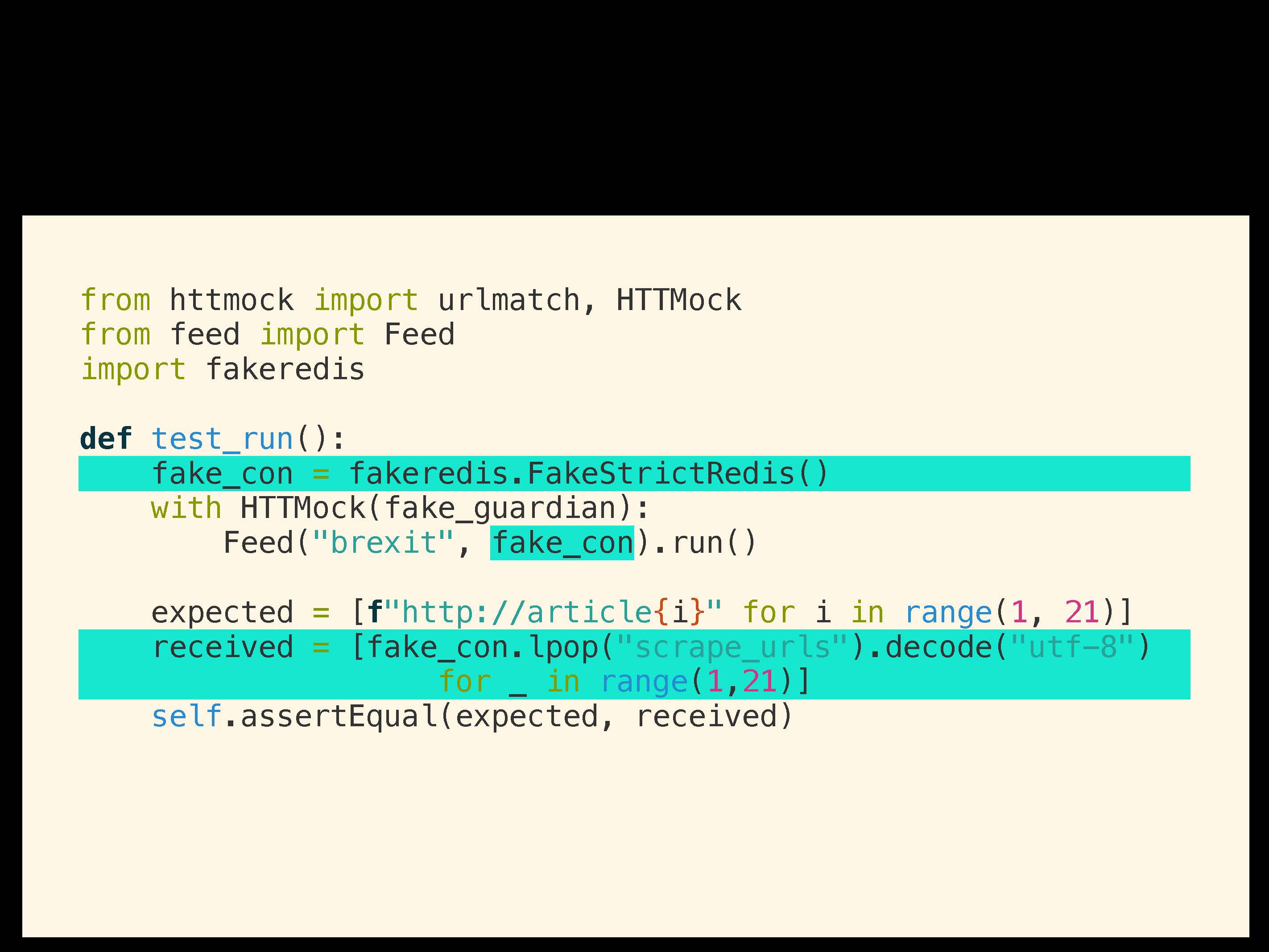
Итак, мы создаем фейковое подключение, добавляем его с помощью инъекции. Благодаря этому assert меняется таким образом, что данные берутся из фейкового Redis, а не через проверку сделанных вызовов. То есть, наша тактика в том, чтобы сделать инъекцию сотрудничающего объекта.
На самом деле, не само подключение к Redis будет настоящим сотрудничающим объектом. Нам просто нужно сделать инъекцию в виде функции, которая будет действовать как получатель данных. Изменение довольно простое. Мы используем объект sink (получатель):

В методе для запуска исполнения run мы и будем использовать этот объект sink вместо подключения к Redis:
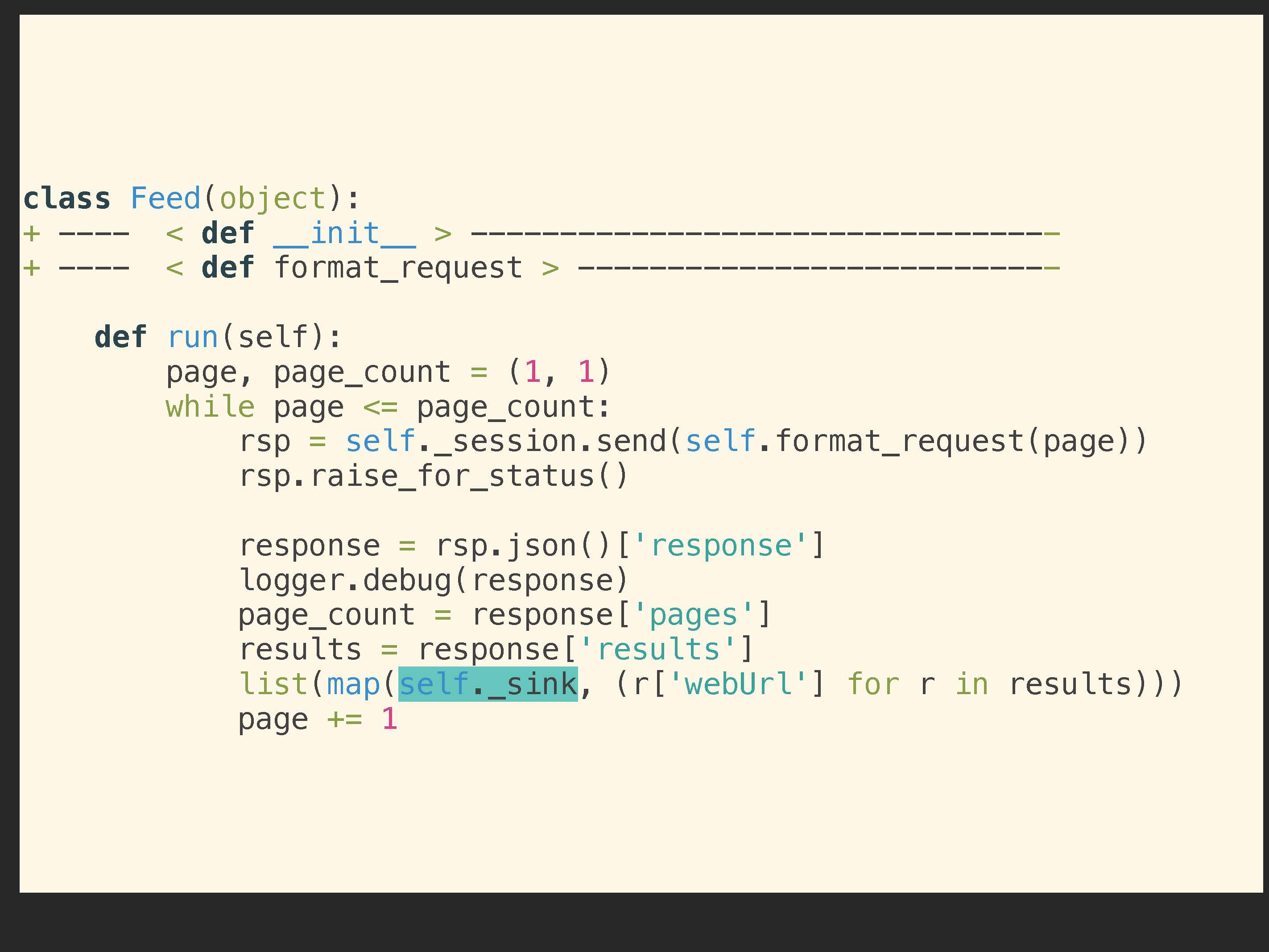
Еще один момент по поводу этого класса. Теперь он полностью независим от Redis и вообще не будет знать о том, какое хранилище данных направляет эти URL.
Как будет изменен тест. Мы убираем мок-объект для Redis. У нас будет просто массив (array) и метод received.append. Далее мы будем использовать assert, который проверит результаты на разумность:
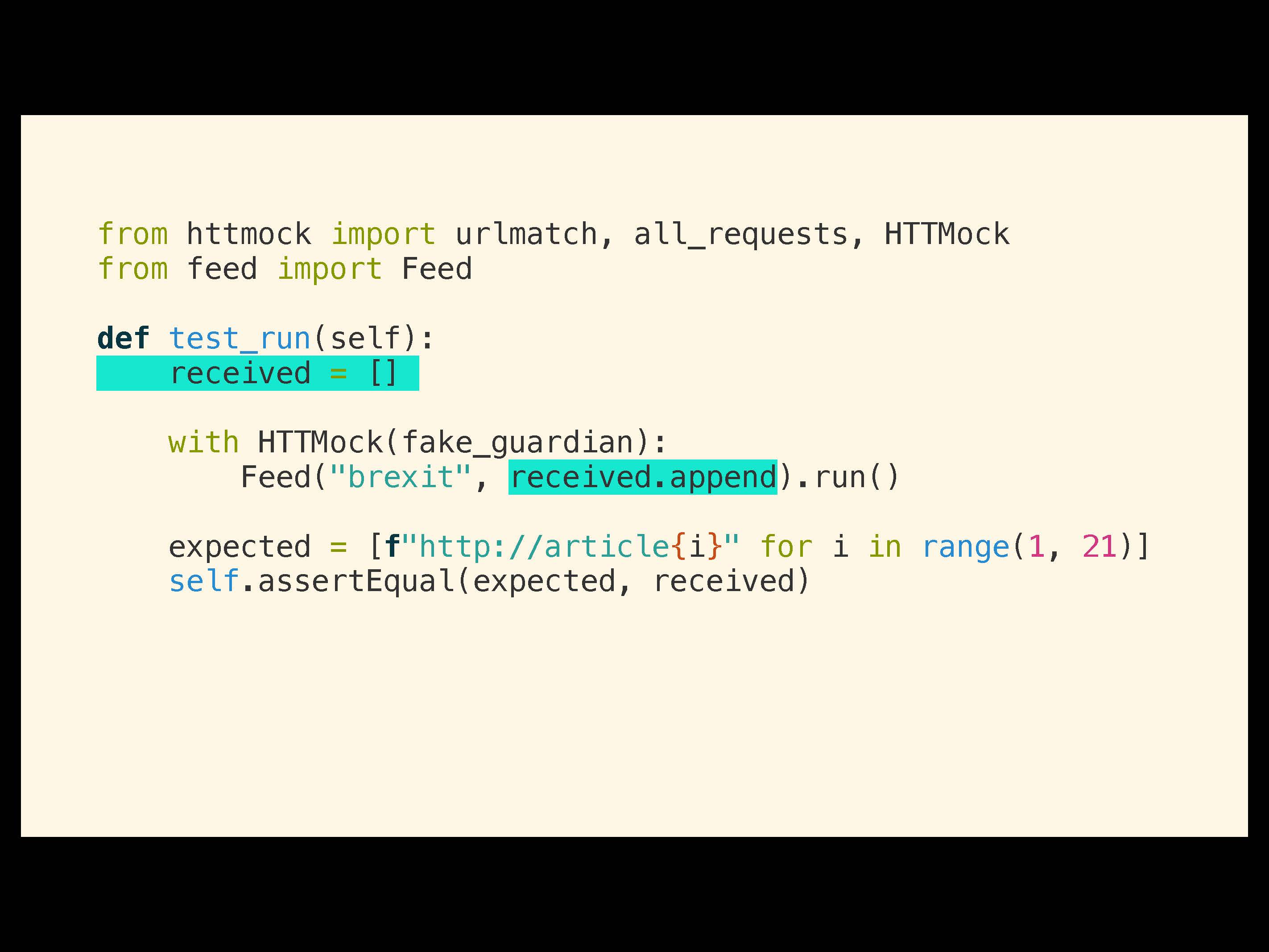
Последнее изменение будет в функции main, чтобы создать реальное подключение к Redis и затем добавить его в фид и метод run с помощью инъекции.
На выходе получилось, что мы перешли к функциональному программированию. Какой-нибудь специалист по функциональному программированию сказал бы, что нашей настоящей проблемой является то, что все эти ваши функции имеют побочные эффекты. Если бы вы сделали функции без побочных эффектов (pure functions), то всех этих проблем не возникло.
Я попробовал сделать рефакторинг кода на основе этого подхода. У нас будет просто функция feed:
def feed(query):
s = requests.Session()
first_page = s.send(initial_request(query))
all_pages = map(s.send,
page_requests(first_page.json(), query=query))
web_urls = munge(all_pages)
redis.Redis("localhost").rpush("scrape_urls", *web_urls)
if__name__ == "__main__":
feed("brexit") Она создает первое обращение request на основе переданной в функцию строки запроса (query string), направляет его и получает первую страницу с результатами. Следующая строка берет первую страницу результатов и создает целый набор обращений к страницам для получения всех URL. Далее они отправляются с помощью того же объекта сессии session, чтобы получить все страницы. После парсинга все URL просто передаются в Redis.
def flatmap(f, items):
return itertools.chain.from_iterable(map(f, items))
def param(key, val):
return {key: val} ifval is not None else{}
def format_request(query, page, page_size = None, date_range=None):
date_range = date_range or (None, None)
params = { "page": page, "query": query, "api-key": _APIKEY}
params.update(param("page_size", page_size))
params.update(param("start_date", date_range[0]))
params.update(param("end_date", date_range[1]))
return Request('GET', _BASE_URL, params=params).prepare()
def initial_request(query, page_size=None, date_range=None):
return format_request(query, page=1, page_size=page_size, date_range=date_range)
def page_requests(body, query):
response = body['response']
page_count = min(3, int(response['pages'])) # IRL needs flow control
forpage in range(1, page_count+1):
params = {"page": page, "query": query, "api-key": _APIKEY}
yield Request('GET', _BASE_URL, params=params).prepare()
def munge(all_pages):
bodies = map(lambdar: r.json(), all_pages)
results = flatmap(lambda body: body['response']['results'], bodies)
return map(lambda result: result['webUrl'], results)Вот и весь код. В нем нет входа и выхода, только трансформации.
Антишаблоны
Контрафактное TDD
Мне встречалось несколько антишаблонов проектирования, расскажу про них. Этот раздел будет немного более субъективным. Мне интересно, замечал ли кто-нибудь похожие моменты.
Начнем с антишаблона, который я называю контрафактным (bootleg) TDD. Это название пришло в голову благодаря одному моему другу, который подписан на Instagram фид с пиратскими игрушками по Звездным войнам.

Как видите, качество не очень, даже лица на обложке не соответствуют игрушке. Именно так я понимаю контрафактность: когда что-то с виду вроде как положено, а на самом деле все неправильно.
На мой взгляд перед нами контрафакт, если:
1. Стремиться к 100 % изоляции теста и 100 % покрытию (coverage). Допустим, программист хочет, чтобы все было идеально, но не занимается рефакторингом, а предпочитает, например, расщепление процесса исполнения или любит нисходящее проектирование (top-down design) вместо объектно-ориентированного программирования. При этом он работает с жизненной ситуацией, в которой не очень хорошо разбирается.
Вот он делает программу P на очень высоком уровне абстрации, потом разбивает ее на более мелкие подпроблемы A и B, их он тоже разбивает дальше на C, D и Е. И так далее.
Функции становятся все более подробными и, наконец, научились подключаться к базе данных. Пора заняться тестированием:
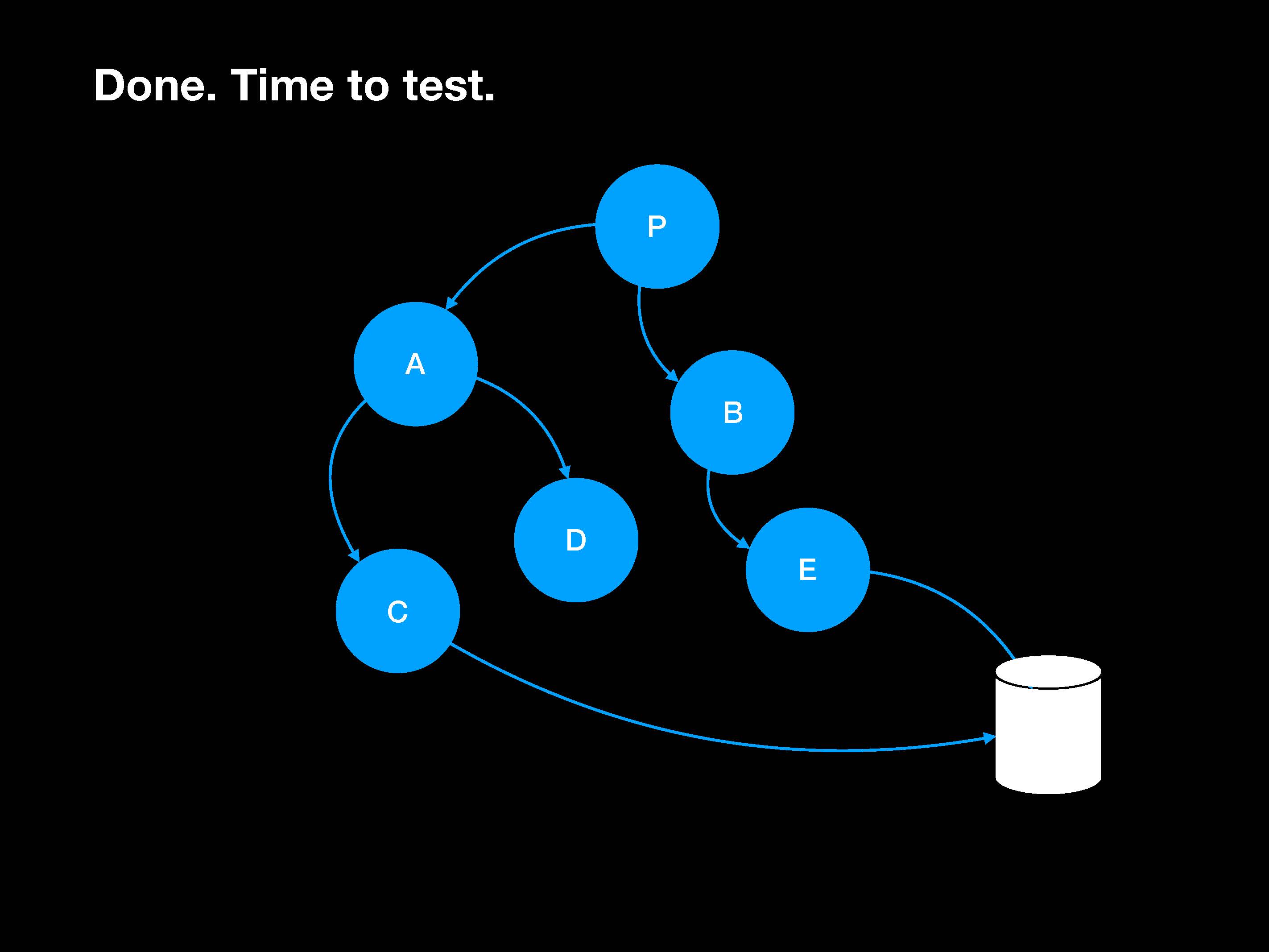
Какие же тут будут тесты? Мы ведь хотим покрытие и изоляцию на 100 %. Давайте тестировать программу P, сделаем мок-объекты для А и В. Аналогично с C, D и E:
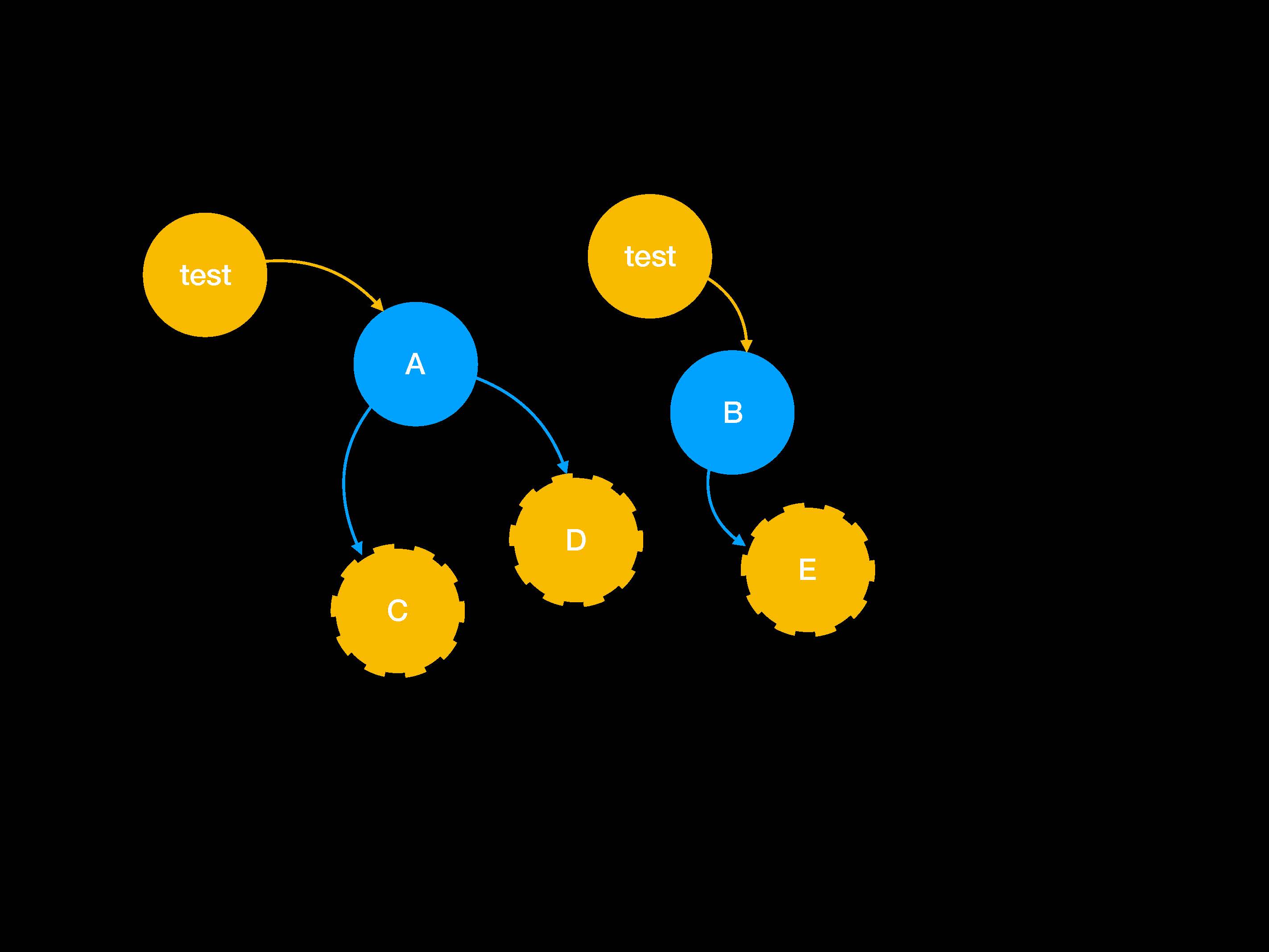
Теперь вопрос о том, как подключаться к базе данных. Наверное, нужно сделать мок-объект для подключения или языка запросов.
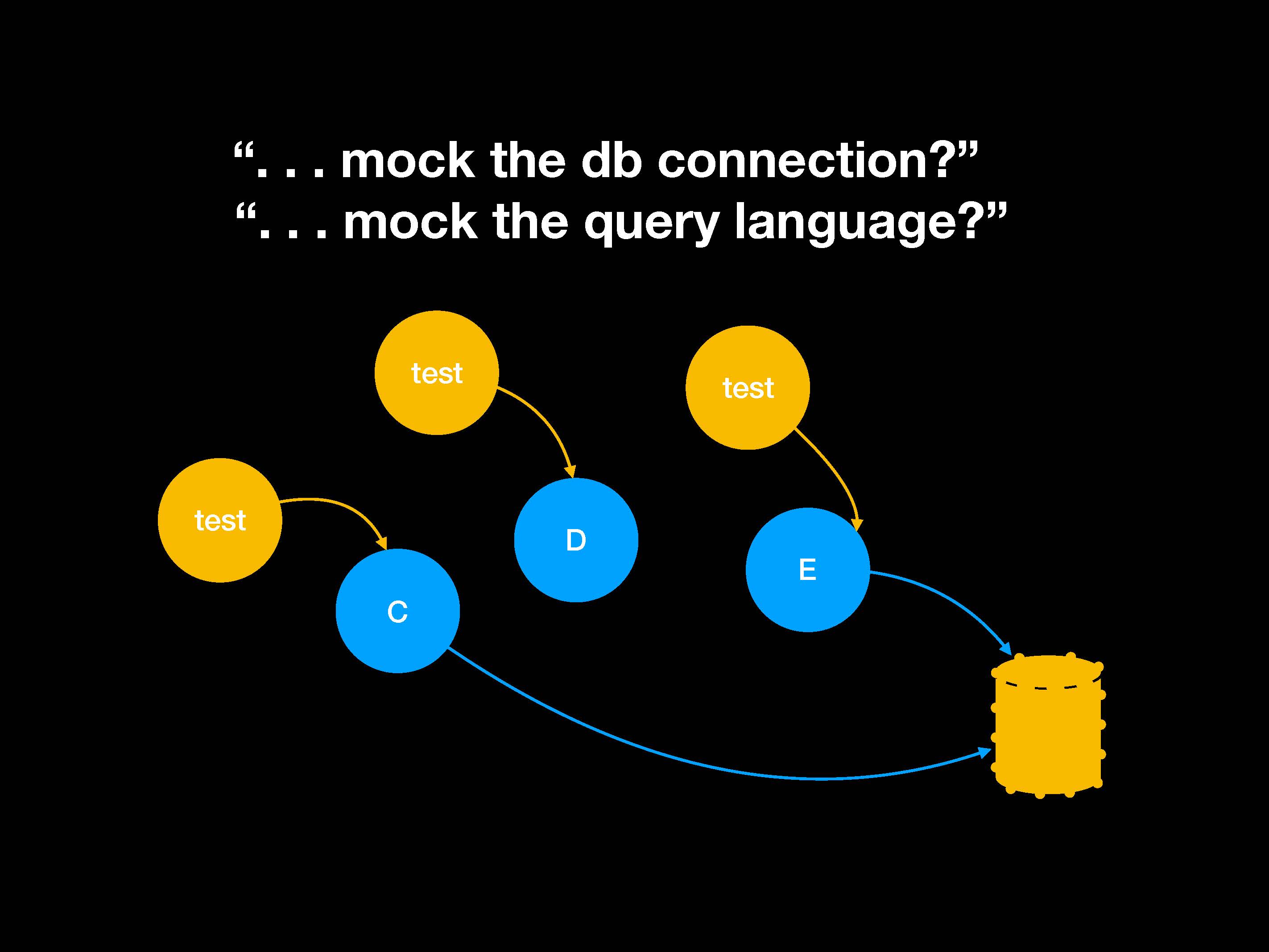
Данное решение — не лучшее в мире, потому что оно привязывает ваши тесты к деталям реализации очень низкого уровня. Однажды у меня разрушились тесты только потому, что поменялся пробел и запрос SELECT.
Если вернуться к Фриману и его книге. По этой теме он советует не делать мок-объекты для того кода, который нам нельзя менять или который нам не принадлежит. Ведь предполагается, что мок-объекты будут инструментом для исследовательского проектирования. Он советует просто создать адаптер базы данных и делать мок-объект для него, а не пытаться заменять мок-объектами подключение к базе данных или язык запросов.
Инверсия и блокировка (inversion-lock)
Когда мы разрабатываем программу, то строим ее от верхнего уровня к нижнему, к уровням абстракций. Поэтому зависимости тоже идут от верхнего уровня к нижнему.
Потом добавляем все наши тесты. В такой ситуации, как я заметил, при использовании нисходящего проектирования нет понимания того, что такое инверсия зависимости (dependency inversion). В связи с большим количеством патчей и мок-объектов очень часто структура кода фиксируется в одном положении.
Получается, что частое использование патчей мешает понимать и применять принципы инверсии зависимости и контроля.
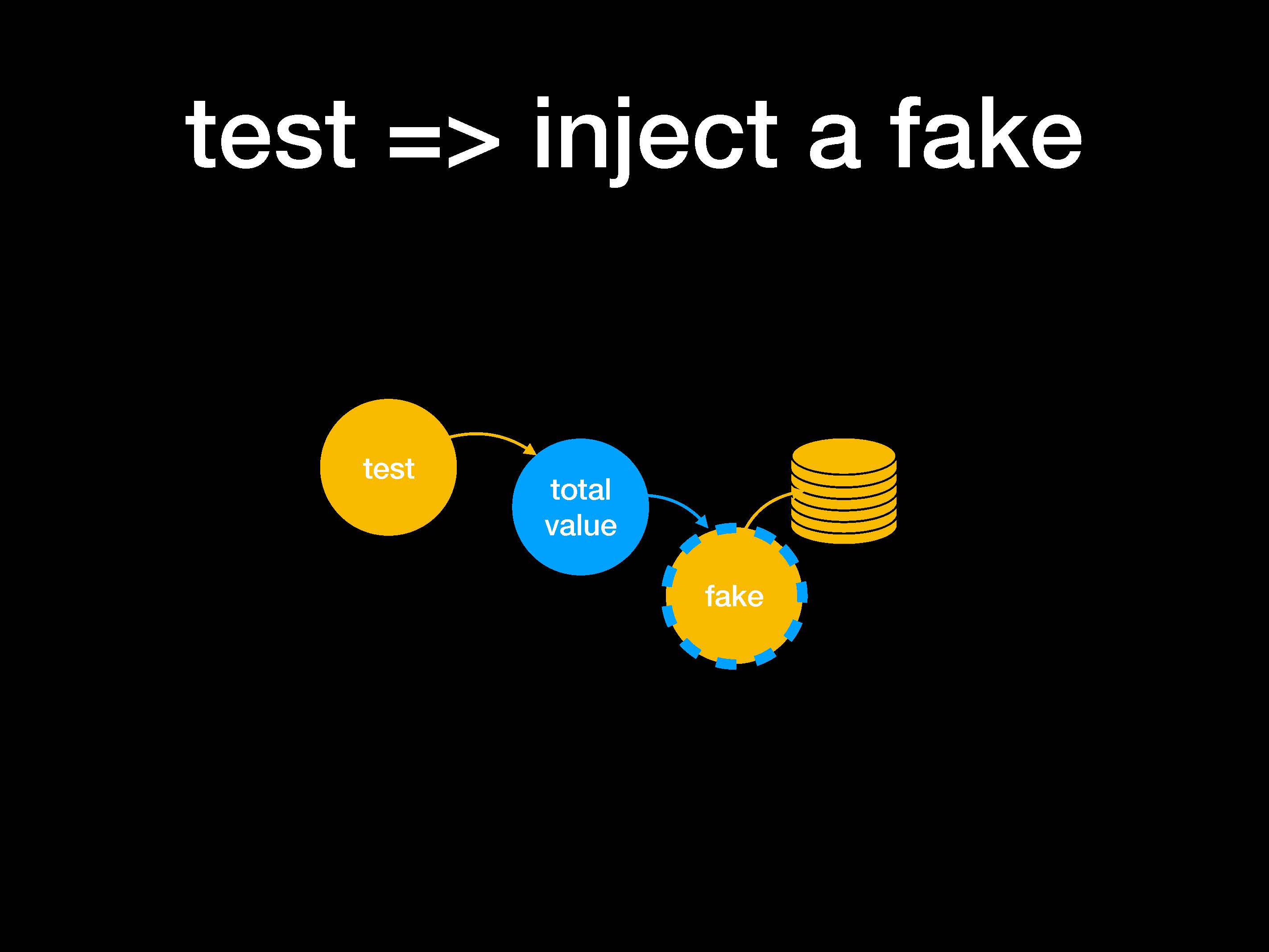
В вышеприведенном примере теста мы делали инъекцию фейка. Это позволило превратить total value в очень гибкий объект, не зависящий от деталей реализации:
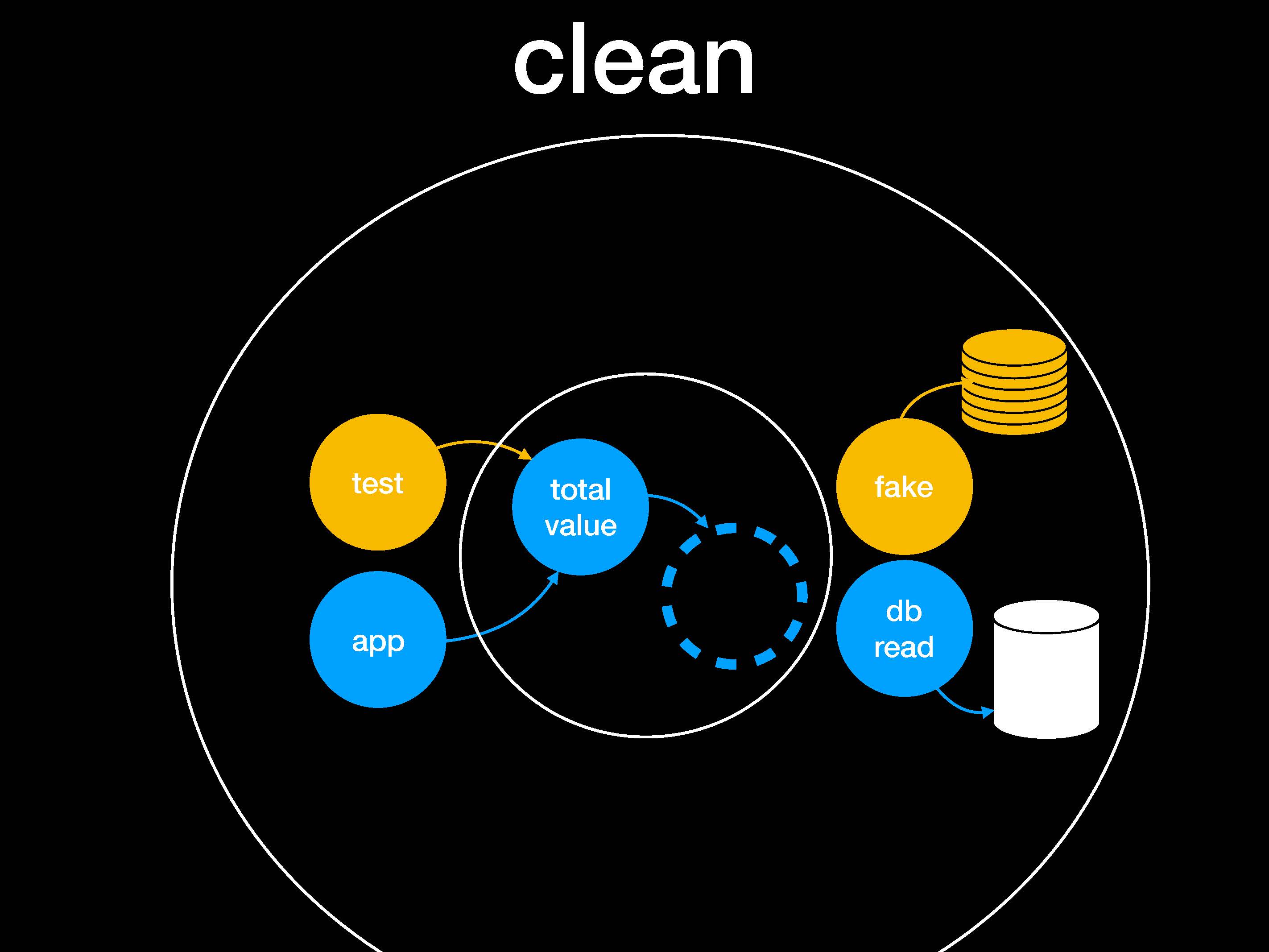
Наш драгоценный код всегда в центре, а детали реализации — снаружи. Нет никаких зависимостей, идущих изнутри наружу. Поэтому для total value неважно, какая используется база данных, есть ли вообще подключение к веб-приложению, либо реализация идет через командную строку или графический интерфейс пользователя.
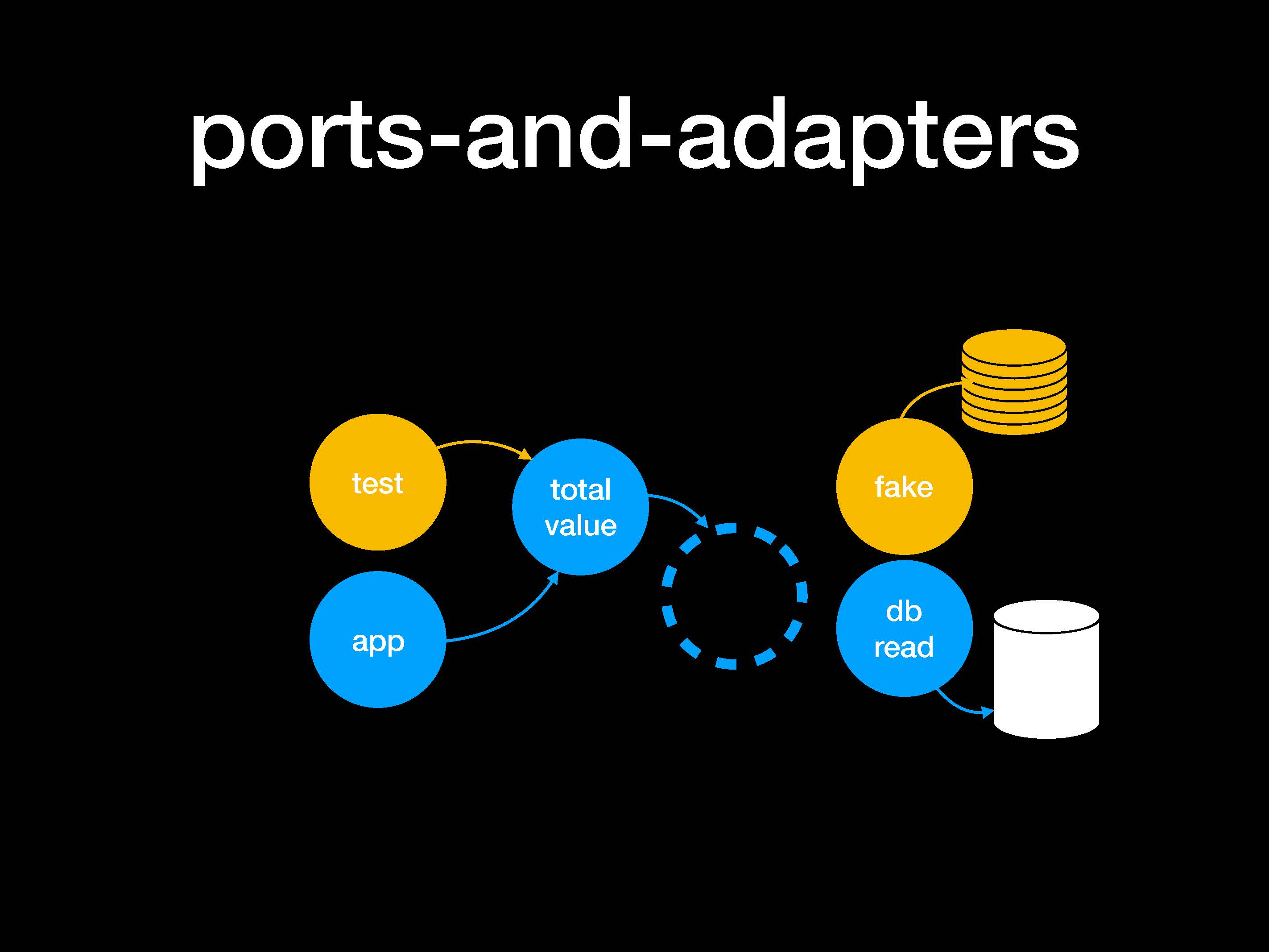
Иногда такую структуру называют чистой архитектурой (clean architecture) или луковой архитектурой (onion architecture). Еще есть такой термин как "порты и адаптеры" (ports and adapters):
Такие архитектуры еще называют гексагональными (hexagonal):
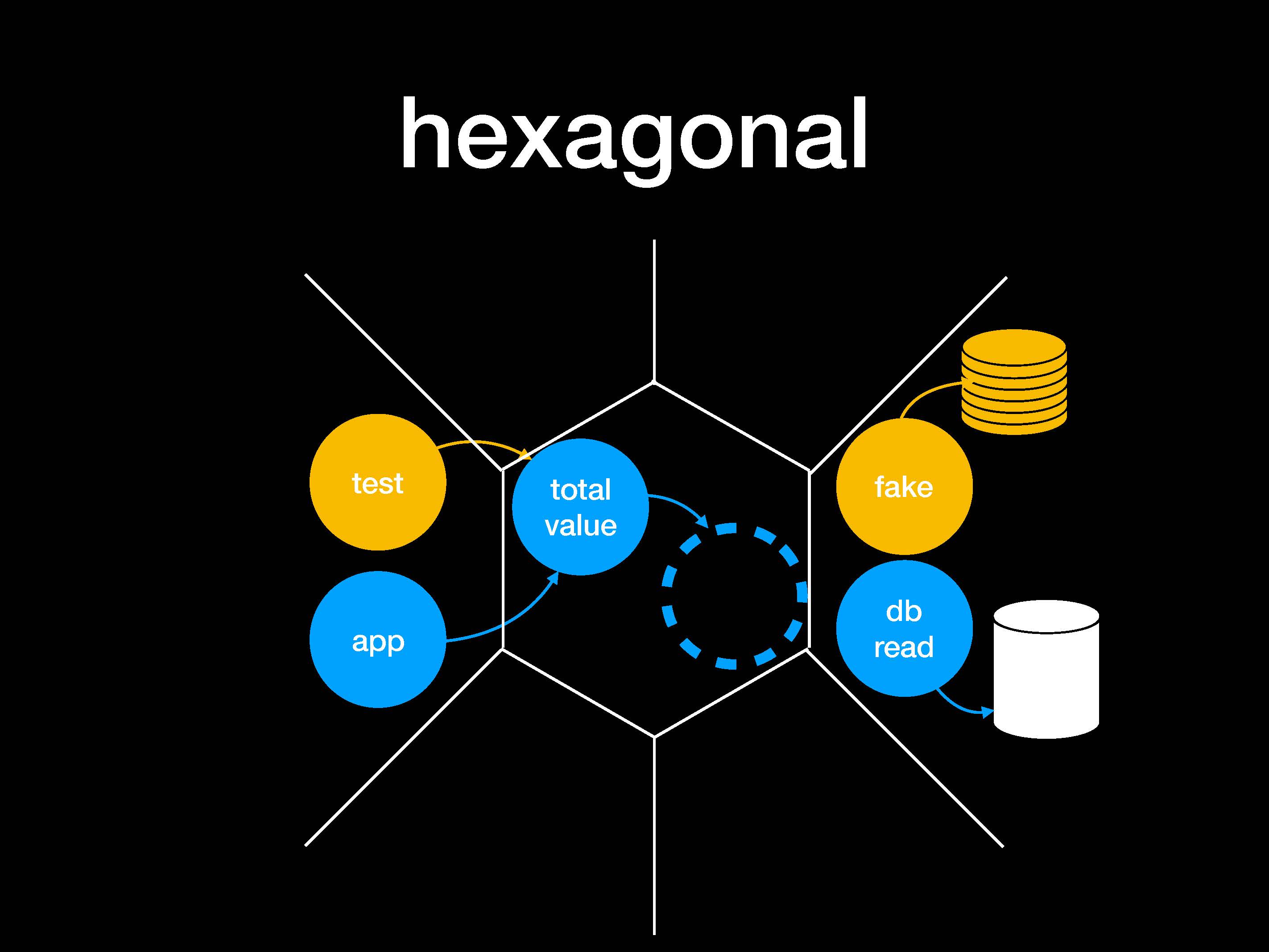
Здесь особенность только в способе организации наружных объектов, которые формируются в две разные группы адаптеров.
Поэтому если вам встретятся все эти умные слова или вот эти загадочные диаграммы, в которых написано про чистую, луковую и гексагональную архитектуру:
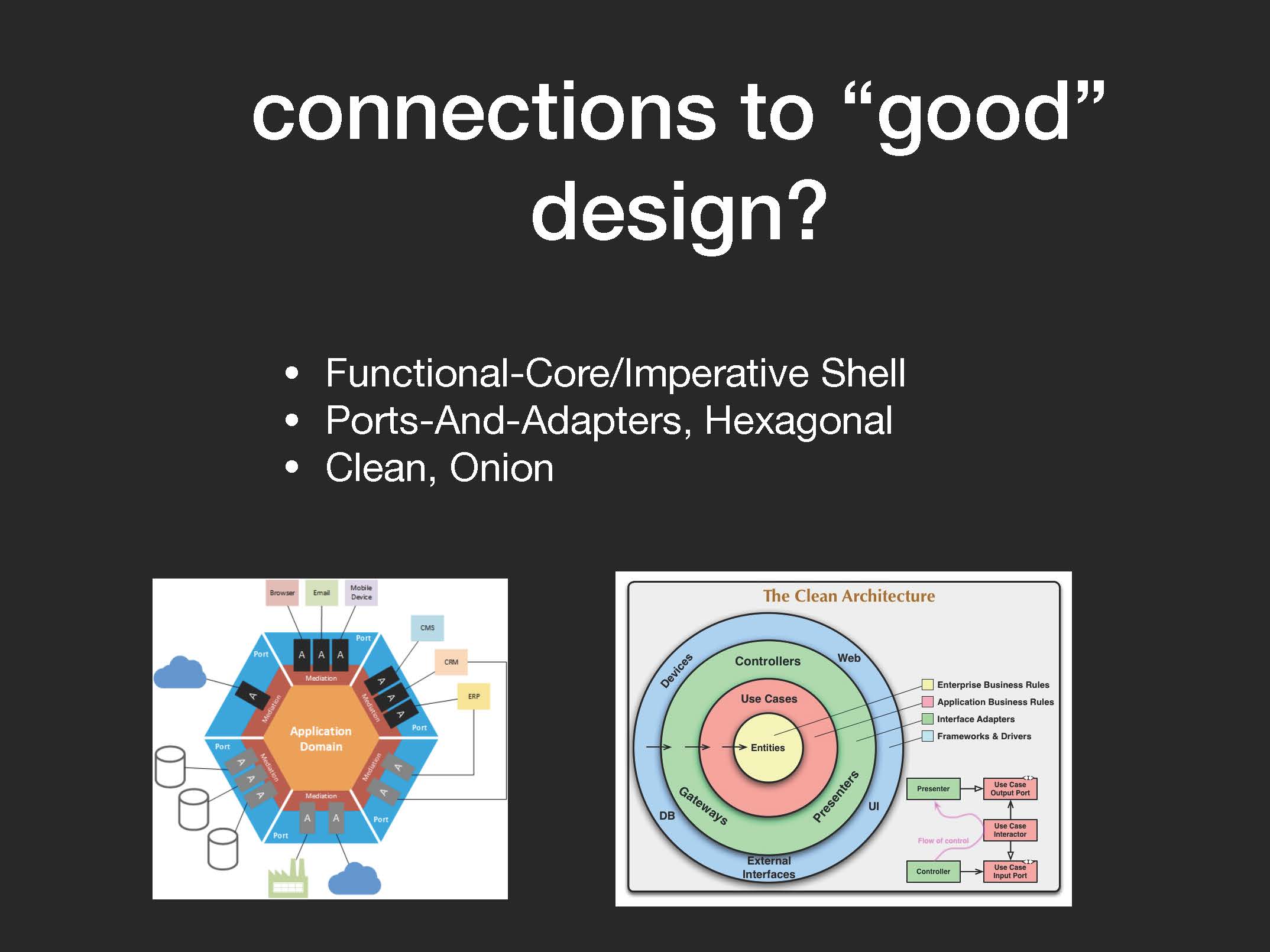
То сразу же на 90 % понятно, о чем идет речь.
Блоб (blob)
Представим себе программу, которая подключается к базе данных. Вот вы над ней работаете, работаете... Спустя неделю вы заканчиваете... Можно перейти к тестам. Думаю, это понравится специалистам по данным (data scientists), потому что такая ситуация возникает у людей, которые умеют программировать, но не являются инженерами ПО (software engineers):

Мы уже умеем тестировать вот это с помощью базы данных. Прибегать к блочным тестам (unit tests) уже поздно. Поэтому мы просто делаем патчи, либо тактически либо экстремально. Мы начинаем закапываться и наконец все тесты проходят успешно:
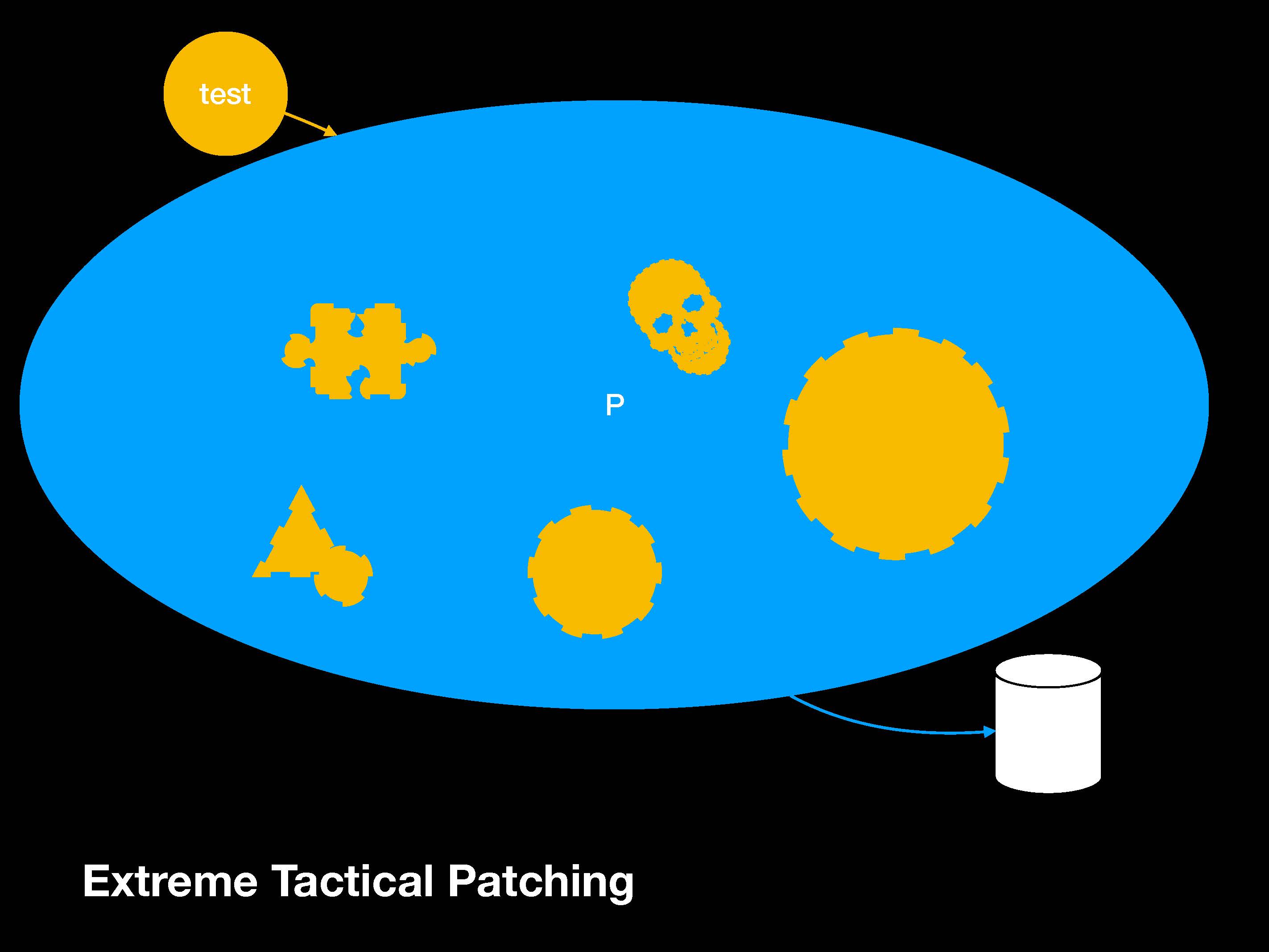
Становится непонятно, что это за тесты. Точно не блочные тесты. Возможно, это нечто, похожее на регрессионный тест (regression test). Кто знает.
На самом деле, у меня двойственное отношение к таким тестам. С одной стороны, возможно, это прагматичный способ использования патчей и logging. С другой, мы, возможно, приучаемся к плохой привычке. Рабочий процесс может пойти и по первому, и по второму сценарию.
Заключение
Хочу спросить по поводу варианта использования патчей как короткого пути. Это довольно субъективный момент. Мне интересно, кто-нибудь видел примеры использования патчей в качестве короткого пути? Есть такой аргумент: в идеале, тест должен проверять только одно действие, а патч является нарушением некой границы капсулы (инкапсуляции).
Поэтому, если в тесте много патчей, то он будет нарушать границы многих капсул. Моя гипотеза в том, что, если в вашем тесте много патчей, то это признак проблем со связностью и согласованностью.
Возможно, в какой-то момент требования поменялись, и структура пакета или модулей перестала подходить для вашего приложения. Возможно, следует подумать о том, чтобы внести изменения. Еще такая ситуация может быть примером поиска короткого пути, который не очень хорошо вписан в структуру пакета.
В заключение хочу высказать несколько мнений:
- нужно всегда заниматься рефакторингом тестов;
- подумайте о возможности использования дублей для тестов помимо мок-объектов; можно применять другие функции мок-объектов;
- патчи следует использовать реже, на самом деле они должны быть последним средством;
- что касается мок-объектов, если все-таки будете ими пользоваться, то нацеливайтесь на роли, а не на объекты, и никогда не пользуйтесь мок-объектами исключительно для изоляции теста.